Привет, друзья!
Представляю вашему вниманию перевод этой замечательной статьи, в которой автор рассказывает о том, как разработать компилятор для WebAssembly на TypeScript.
Обратите внимание: мой вариант компилятора можно найти в этом репозитории, а поиграть с его кодом можно в этой песочнице.
Что такое WebAssembly и зачем он нужен?
Если вы никогда раньше не слышали о WebAssembly (далее - WA или wasm), рекомендую взглянуть на это визуальное руководство от Lin Clark.
Сравнение WA с JavaScript (далее - JS) можно представить следующим образом:
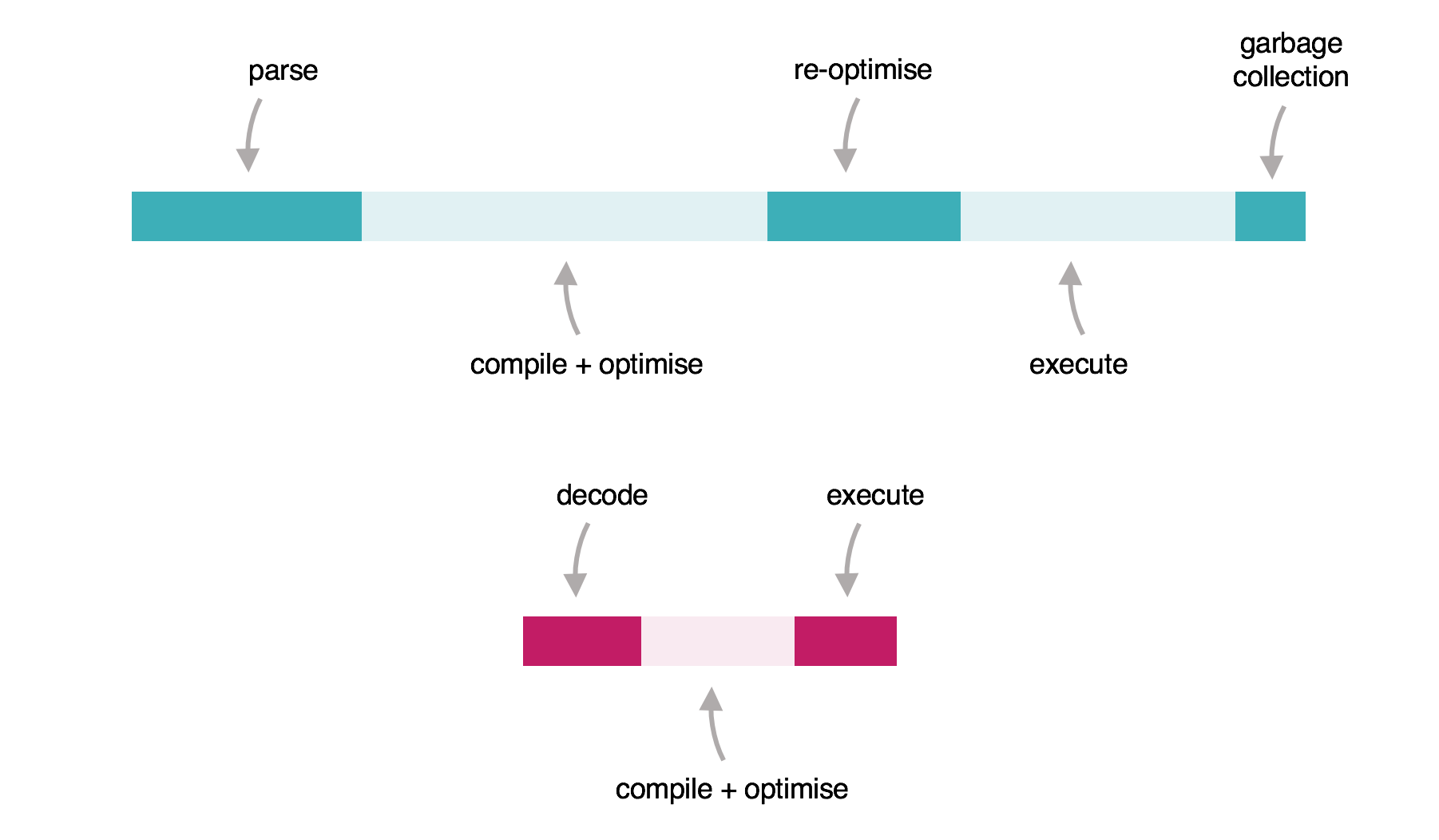
На верхней диаграмме представлен упрощенный процесс выполнения JS-кода в браузере. Слева направо: код (обычно доставляемый в виде минифицированной мешанины) р�азбирается (парсится) в абстрактное синтаксическое дерево (Abstract Syntax Tree, AST), первоначально выполняется в интерпретаторе, затем прогрессивно оптимизируется/повторно оптимизируется до тех пор, пока не будет выполняться достаточно быстро. Современный JS, в конечном счете, является очень быстрым, но для его "подготовки" к выполнению требуется какое-то время.
На нижней диаграмме представлен эквивалент WA. Код, написанный на одном из нескольких языков (Rust, C, C# и др.) компилируется в WA, который доставляется в бинарном (двоичном) формате. Этот формат легко декодируется, компилируется и выполняется, что обеспечивает предсказуемо высокую производительность.
Наша цель
Наша цель - разработать язык программирования, достаточный для создания программы для рендеринга множества Мандельброта.
Это будет выглядеть так:

Я назвал свой язык chasm. Его исходный код можно найти в этом репозитории на GitHub, а в этой онлайн-песочнице можно с ним поиграть.
Минимальный модуль wasm
Создадим минимальный модуль wasm (далее - модуль).
Определим эмиттер (emitter - часть компилятора, генерирующая инструкции для целевой системы), создающего такой модуль:
// https://webassembly.github.io/spec/core/binary/modules.html#binary-module
const magicModuleHeader = [0x00, 0x61, 0x73, 0x6d]
const moduleVersion = [0x01, 0x00, 0x00, 0x00]
const emiter: Emitter = () => {
const buffer = [
...magicModuleHeader,
...moduleVersion
]
return Uint8Array.from(buffer)
}
Эмиттер состоит из 2 частей: "магического" заголовка, представляющего собой строку \0asm в формате ASCII, и номера версии. Эти 8 байт формируют валидный модуль. Обычно, модуль доставляется в браузер в виде файла с расширением .wasm.
Для выполнения модуля его необходимо инстанцировать (instantiate - создать экземпляр класса) следующим образом:
const wasm = emitter()
const instance = await WebAssembly.instantiate(wasm)
Если мы запустим этот код, то ничего не произойдет, поскольку наш модуль пока не содержит никаких инструкций.
В указанном выше репозитории имеются коммиты для каждого шага, которые мы будем рассматривать в дальнейшем.
Функция для сложения чисел
Реализуем функцию для сложения 2 чисел с плавающей точкой/запятой (float).
WA - это бинарный формат, не рассчитанный на чтение людьми, поэтому был специально разработан текстовый формат WA (WebAssembly TextFormat, WAT). Вот пример модуля в текстовом формате, в котором определяется функция $add, принимающая 2 числа с плавающей точкой, складывающая их и возвращающая результат:
(module
(func $add (param f32) (result f32)
get_local 0
get_local 1
f32.add)
(export "add" (func 0))
)
Для компиляции WAT в wasm можно использовать wat2wasm из бинарного набора инструментов для WA.
Из приведенного выше кода можно извлечь следующую информацию:
WA- это низкоуровневый язык с небольшим набором инструкций (всего их около60), в котором большая часть инструкций близко связана с инструкциями для центрального процессора/ЦП (CPU). Это облегчает процесс компиляции модулей в специфичный для процессора машинный код;- он не имеет встроенного ввода/вывода (
input/output,I/O). Не существует инструкций для вывода данных в терминал, на экран или в сеть. Поэтому для взаимодействия с внешним миром модули используют хостовое окружение (host environment), которым в случае с браузером являетсяJS; WA- это стек машина (stack machine). В приведенном примереget_local 0получает локальную переменную (параметр функции), находящуюся на позиции с индексом 0, и помещает ее в стек. То же самое делает следующая инструкция (меняется только индекс). Функцияf32.addизвлекает значения из стека, складывает их и помещает результат обратно в стек;WAимеет всего лишь 4 числовых типа: 2 для целых чисел и 2 для чисел с плавающей точкой. Об этом позже...
Обновим код эмиттера.
Модули - это композиция предварительно определенных опциональных разделов (sections), каждый раздел имеет префикс - числовой идентификатор. Имеется раздел для типа, в котором закодированы сигнатуры типов, и раздел для функций, определяющий тип каждой функции. Я не буду на этом останавливаться - реализация является достаточно наивной. Вы найдете ее здесь.
Интересным является раздел для кода. Вот как функция add преобразуется в бинарный формат:
const code = [
Opcodes.get_local, // 0x20
...unsignedLEB128(0),
Opcodes.get_local, // 0x20
...unsignedLEB128(1),
Opcodes.f32_add // 0x92
]
const functionBody = encodeVector([
...encodeVector([]), // locals
...code,
Opcodes.end // 0x0b
])
const codeSection = createSection(Section.code /* 0x0a */, encodeVector([functionBody]))
Opcodes (opcode, operation code - код операции) - это перечисление (enum), содержащее все инструкции wasm. unsignedLEB128 - это функция для сжатия кода переменной длины для хранения произвольно больших целых чисел в небольшом количестве байтов (LEB128). Она используется для кодирования параметров инструкций.
Инструкции функции комбинируются с ее локальными переменными (которые в данном случае отсутствуют), код операции end сигнализирует о завершении выполнения �функции. Наконец, все функции помещаются в раздел. Функция encodeVector просто добавляет префикс со значением общей длины к коллекции байтовых массивов.
Длина получившегося модуля составляет около 30 байт.
Обновим JS-код:
const { instance } = await WebAssembly.instantiate(wasm)
console.log(instance.exports.add(5, 6))
Обратите внимание: если вы исследуете экспортируемую функцию add с помощью инструментов разработчика в Chrome, то увидите, что это "обычная функция" (native function).
Разработка компилятора
Пришло время для разработки компилятора. Начнем с терминологии.
Вот некоторый chasm-код, аннотированный для отображения ключевых компонентов языка:
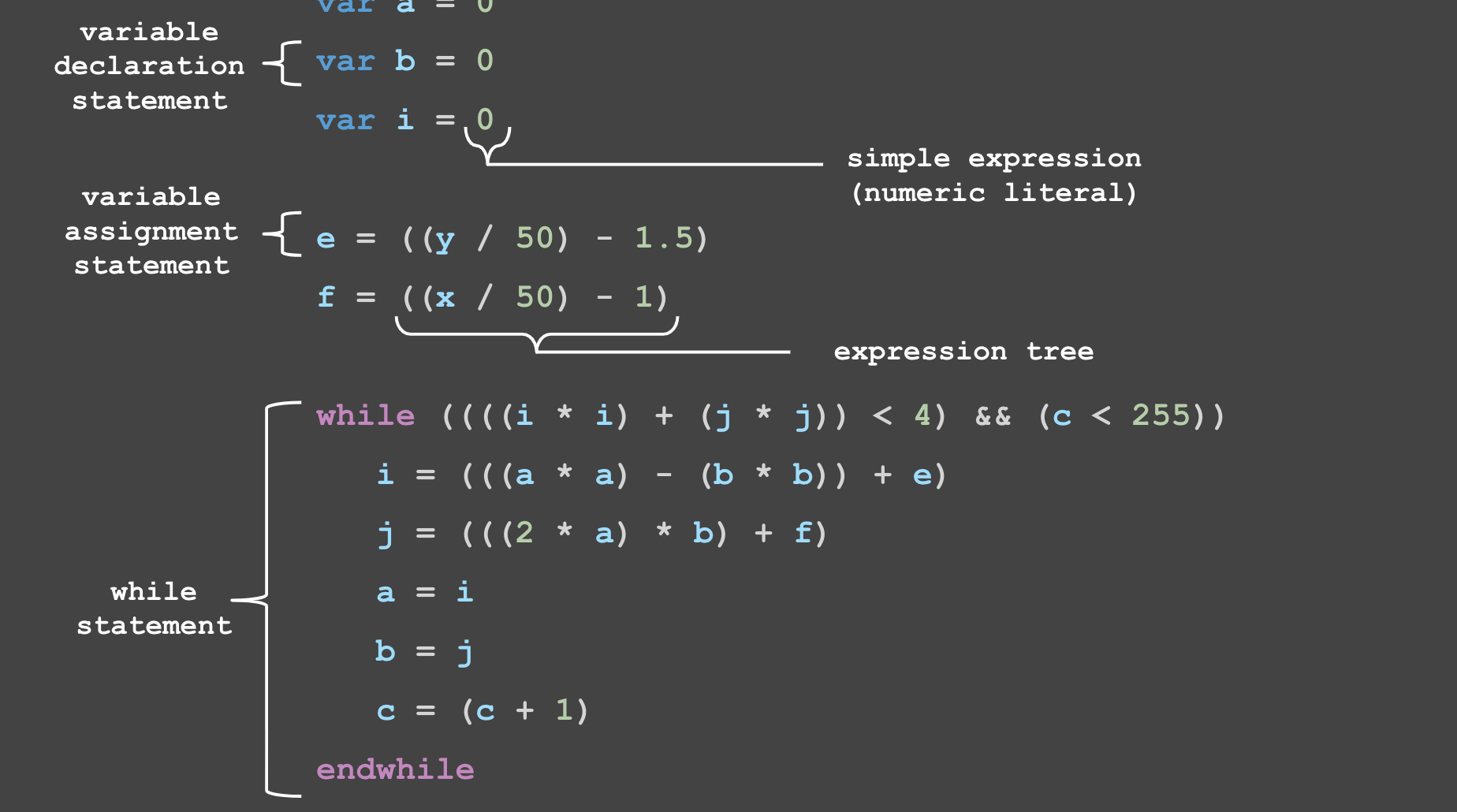
Мы познакомимся с каждым из этих компонентов в процессе разработки компилятора.
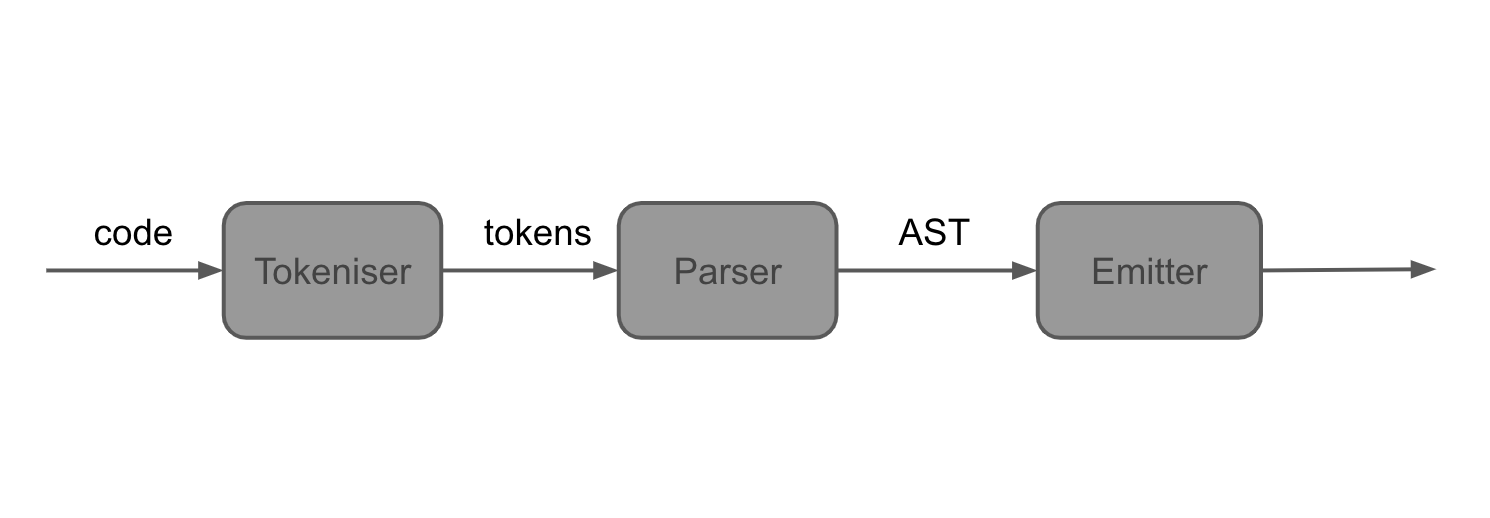
Сам компилятор состоит из 3 частей:
- токенизатора (
tokenizer), разделяющего/разбивающего (split) входящую/входную программу (input program) в виде строки на отдельные токены (tokens); - парсера (
parser), принимающего токены и преобразующего их вAST; - эмиттера, преобразующего
ASTв бинарный модуль.
Пример архитектуры компилятора:
Вместо того, чтобы погружаться в полную реализацию, мы сосредоточимся на небольшой группе задач. Первая задача - разработать компилятор для языка, поддерживающего инструкции для вывода (print statements), выводящие числовые литералы (numeric literals):
print 22
print 45
Токенизатор
Токенизатор перебирает строку по одному символу, выполняя поиск совпадения с определенным типом токенов. Следующий код создает 3 совпадения (number, keyword и whitespace) с помощью простого регулярного выражения:
const keywords = ['print']
// возвращает токен, если переданное регулярное выражение совпадает с символом на позиции с текущим индексом
const regexMatcher = (regex: string, type: TokenType): Matcher =>
(input: string, index: number) => {
const match = input.substring(index).match(regex)
return (
match && {
type,
value: match[0]
}
)
}
const matchers = [
regexMatcher('^[.0-9]+', 'number'),
regexMatcher(`^${keywords.join('|')}`, 'keyword'),
regexMatcher('^\\s+', 'whitespace')
]
Интерфейс Matcher определяет функцию, принимающую строку и индекс и возвращающую токен при наличии совпадения.
Основная функция парсера перебирает строку посимвольно и при наличии совпадения добавляет токен в массив:
const tokenize: Tokenizer = (input) => {
const tokens: Token[] = []
let index = 0
while (index < input.length) {
const [match] = matchers.map((m) => m(input, index)).filter((f) => f)
if (match.type !== 'whitespace') {
tokens.push(match)
}
index += match.value.length
}
return tokens
}
Вот "токенизированый" вывод программы print 23.1:
[
{
"type": "keyword",
"value": "print",
"index": 1
},
{
"type": "number",
"value": "23.1",
"index": 7
}
]
Как видите, токенизатор удаляет пробелы, поскольку в нашем языке они не имеют никакого значения. Он также определяет валидность токенов. Однако, он не проверяет правильность оформления строки, например, он (с удовольствием) пропустит print print, несмотря на очевидную некорректность такой программы.
Парсер
Цель парсера - создание AST, древовидной структуры, которая кодирует отношения между токенами в форме, которая потенциально может быть напрямую передана интерпретатору для выполнения.
Парсер перебирает переданные токены, потребляя (consuming) их с помощью функции eatToken.
const parse: Parser = (tokens) => {
const iterator = tokens[Symbol.iterator]()
let currentToken = iterator.next().value
const eatToken = () =>
(currentToken = iterator.next().value)
// ...
const nodes: StatementNode[] = []
while (index < tokens.length) {
nodes.push(parseStatement())
}
return nodes
}
Парсер преобразует массив токенов в массив инструкций, которые являются ключевыми строительными блоками любого языка. Он ожидает, что переданные токены будут соответствовать указанному паттерну, при несоответствии выбрасывается исключение.
Функция parseStatement ожидает, что каждая инструкция начинается с ключевого слова, за которым следует некоторое значение:
const parseStatement = () => {
if (currentToken.type === 'keyword') {
case 'print':
eatToken()
return {
type: 'printStatement',
expression: parseExpression()
}
}
}
В данный момент единственным поддерживаемым нашим языком ключевым словом является print - возвращается узел (node) AST типа printStatement, в котором разбирается соответствующее выражение.
Парсер выражений выглядит так:
const parseExpression = () => {
let node: ExpressionNode
switch (currentToken.type) {
case 'number':
node = {
type: 'numberLiteral',
value: Number(currentToken.value)
}
eatToken()
return node
}
}
В данный момент наш язык принимает только выражения, состоящие из одного числа - числовой литерал. Поэтому парсер ожидает, что следующим токеном будет число и, когда происходит совпадение, возвращается узел типа numberLiteral.
Для программы print 23.1 результат работы парсера будет следующим:
[
{
"type": "printStatement",
"expression": {
"type": "numberLiteral",
"value": 23.1
}
}
]
Как видите, AST для нашего языка - это массив узлов с инструкциями. Парсинг гарантирует, что входящая программа является синтаксически корректной, т.е. правильно сформирована, но не гарантирует успешность выполнения этой программы, поэтому в ней могут присутствовать ошибки времени выполнения.
Эмиттер
В данный момент эмиттер возвращает функцию add. Однако он должен принимать AST и генерировать соответствующие инструкции:
const codeFromAst = (ast) => {
const code = []
const emitExpression = (node) => {
switch (node.type) {
case 'numberLiteral':
code.push(Opcodes.f32_const)
code.push(...ieee754(node.value))
break
}
}
ast.forEach((statement) => {
switch (statement.type) {
case 'printStatement':
emitExpression(statement.expression)
code.push(Opcodes.call)
code.push(...unsignedLEB128(0))
break
}
})
return code
}
Эмиттер перебирает инструкции, формирующие "корень" (root) AST, в поисках совпадений. Первое, что он делает - генерирует инструкции для выражений. Поскольку WA - это стек-машина, инструкции выражений должны обрабатываться первыми с помещением результата в стек.
Функция print реализована через операцию call, которая вызывает функцию по нулевому индексу.
Ранее мы видели, как модули могут экспортировать функции. Они также могут импортировать функции, которые доставляются при инстанцировании модуля. Пример импорта функции env.print для вывода сообщений в консоль:
const instance = await WebAssembly.instantiate(wasm, {
env: {
print: console.log
}
})
Эта функция доступна по индексу call 0.
Полный код текущего шага можно найти здесь, а поиграть с этим кодом - здесь.
Эволюцию программы на каждом этапе компиляции можно представить следующим образом:

Реализация выражений
Займемся реализацией бинарных выражений. Это позволит языку выполнять простые математические операции, например, print ((42 + 10) / 2).
Изменения токенизатора довольно тривиальные - мы просто добавляем несколько регулярок для скобок и операторов. Я не буду на этом останавливаться. Результат работы парсера будет следующим:
[
{ "type": "keyword", "value": "print" },
{ "type": "parens", "value": "(" },
{ "type": "parens", "value": "(" },
{ "type": "number", "value": "42" },
{ "type": "operator", "value": "+" },
{ "type": "number", "value": "10" },
{ "type": "parens", "value": ")" },
{ "type": "operator", "value": "/" },
{ "type": "number", "value": "2" },
{ "type": "parens", "value": ")" }
]
Рассмотрим изменения парсера - парсер выражений теперь принимает токены типа number и parens (parenthesis - скобки):
const parseExpression = () => {
let node: ExpressionNode
switch (currentToken.type) {
case 'number':
// ...
case 'parens':
eatToken()
const left = parseExpression()
const operator = currentToken.value
eatToken()
const right = parseExpression()
eatToken()
return {
type: 'binaryExpression',
left,
right,
operator
}
}
}
Обратите внимание: парсинг выражений parens является рекурсивным, узлы для левого и правого операндов вызывают функцию parseExpression.
AST для программы print ((42 + 10) / 2) будет выглядеть так:
[
{
type: "printStatement",
expression: {
type: "binaryExpression",
left: {
type: "binaryExpression",
left: {
type: "numberLiteral",
value: 42
},
right: {
type: "numberLiteral",
value: 10
},
operator: "+"
},
right: {
type: "numberLiteral",
value: 2
},
operator: "/"
}
}
]
Древовидная структура AST становится более очевидной, не правда ли?
Добавляем в эмиттер обработку узла типа binaryExpression:
const emitExpression = (node) =>
traverse(node, (node) => {
switch (node.type) {
case 'numberLiteral':
code.push(Opcodes.f32_const)
code.push(...ieee754(node.value))
break
case 'binaryExpression':
code.push(binaryOpcode[node.operator])
break
}
})
Функция traverse обходит дерево, вызывая переданного посетителя (visitor) для каждого узла. Несмотря на то, что для линейных структур существует только один логический способ обхода (по порядку), деревья можно обходить разными способами. Метод, используемый эмиттером, представляет собой обход в глубину после упорядочения (depth-first post-order traversal). Другими словами, при переборе он обходит левый, правый, затем корневой узлы - такой порядок обеспечивает правильное помещение wasm-инструкций в стек: сначала помещаются операнды, затем оператор.
Это все изменения, которые необходимо произвести для поддержки выражений. Поиграть с кодом данного шага можно здесь.
Сложная архитектура компилятора начинает оправдываться.
Переменные
Добавим поддержку переменных:
var f = 2
print (f + 1)
Переменные объявляются с помощью ключевого слова var и могут быть использованы в выражениях как идентификаторы.
Мы не будем рассматривать изменения токенизатора - еще парочка регулярок. В основном цикле парсера, где происходит чтение инструкций из массива токенов, тип инструкции определяется на основе ключевого слова:
const parseVariableDeclarationStatement = () => {
eatToken() // var
const name = currentToken.value
eatToken()
eatToken() // =
return {
type: 'variableDeclaration',
name,
initializer: parseExpression()
}
}
const parseStatement: ParseStep<StatementNode> = () => {
if (currentToken.type === 'keyword') {
switch (currentToken.value) {
case 'print':
return parsePrintStatement()
case 'var':
return parseVariableDeclarationStatement()
}
}
}
Обратите внимание, что функция parseVariableDeclarationStatement использует парсер выражений. Это обеспечивает возможность объявления переменной с присвоением ей значения в одном выражении, например, var f = (1 + 4).
Далее следует эмиттер. Функции WA могут содержать локальные переменные, которые определяются в начале функции и доступны через методы get_local и set_local, которые также позволяют извлекать параметры функции.
Переменные в нашем AST доступны по названиям идентификаторов, хотя wasm идентифицирует локальные переменные по индексу. Поэтому эмиттеру требуется символьная таблица (symbol table), которая является простой картой (map), связ�ывающей название символа с индексом:
const symbols = new Map<string, number>()
const localIndexForSymbol = (name: string) => {
if (!symbols.has(name)) {
symbols.set(name, symbols.size)
}
return symbols.get(name)
}
При обходе дерева объявление переменной преобразуется в выражение, затем вызывается функция set_local для присвоения значения соответствующей локальной переменной.
case 'variableDeclaration':
emitExpression(statement.initializer)
code.push(Opcodes.set_local)
code.push(...unsignedLE128(localIndexForSymbol(node.value)))
break
Также необходимо обновить кодирование функции для добавления локальных переменных для функции, которую сгенерировал эмиттер. chasm поддерживает единственный тип переменных - все является числом с плавающей точкой.
Поиграть с кодом этого шага можно здесь.
Цикл while
Для рендеринга множества Мандельброта нам требуется какой-нибудь цикл. Для chasm я выбрал цикл while. Пример простой программы, выводящей числа от 0 до 9:
var f = 0
while (f < 10)
print f
f = (f + 1)
endwhile
WA имеет разные инструкции для потока управления (control flow): ветки, if, else, цикл, блок и т.д. Вот как может выглядеть цикл while на WAT:
(block
(loop
[loop.condition] // условие
i32.eqz
[nested statements] // вложенные инструкции
br_if 1
br 0)
)
Ветвление (branching) в WA основано на глубине стека. Внешние инструкции block и loop помещают сущности в стек потока управления. Инструкция br_if 1 выполняет ветку условия (conditional branch) на первом уровне глубины стека, а br 0 - это обычная ветка, повторно запускающая loop.
Эмиттер преобразует приведенный выше WAT в бинарный формат следующим образом:
case 'whileStatement':
// внешний `block`
code.push(Opcodes.block)
code.push(Blocktype.void)
// внутренний `loop`
code.push(Opcodes.loop)
code.push(Blocktype.void)
// вычисляем выражение `while`
emitExpression(statement.expression)
code.push(Opcodes.i32_eqz)
// br_if $label0
code.push(Opcodes.br_if)
code.push(...signedLED128(1))
// вложенная логика
emitStatements(statement.statements)
// br $label1
code.push(Opcodes.br)
code.push(...signedLEB128(0))
// конец цикла
code.push(Opcodes.end)
// конец блока
code.push(Opcodes.end)
break
Поиграть к кодом данного шага можно здесь.
Графика
Мы почти закончили - остался последний шаг. Сейчас единственным способом увидеть результат работы нашего компилятора является использование инструкции print, которая привязывается к console.log через функцию, импортируемую в модуль. Для множества Мандельброта нам требуется какой-то способ рендерить графику на эк�ране.
Для решения этой задачи мы используем еще один важный компонент модулей - линейную память (linear memory):
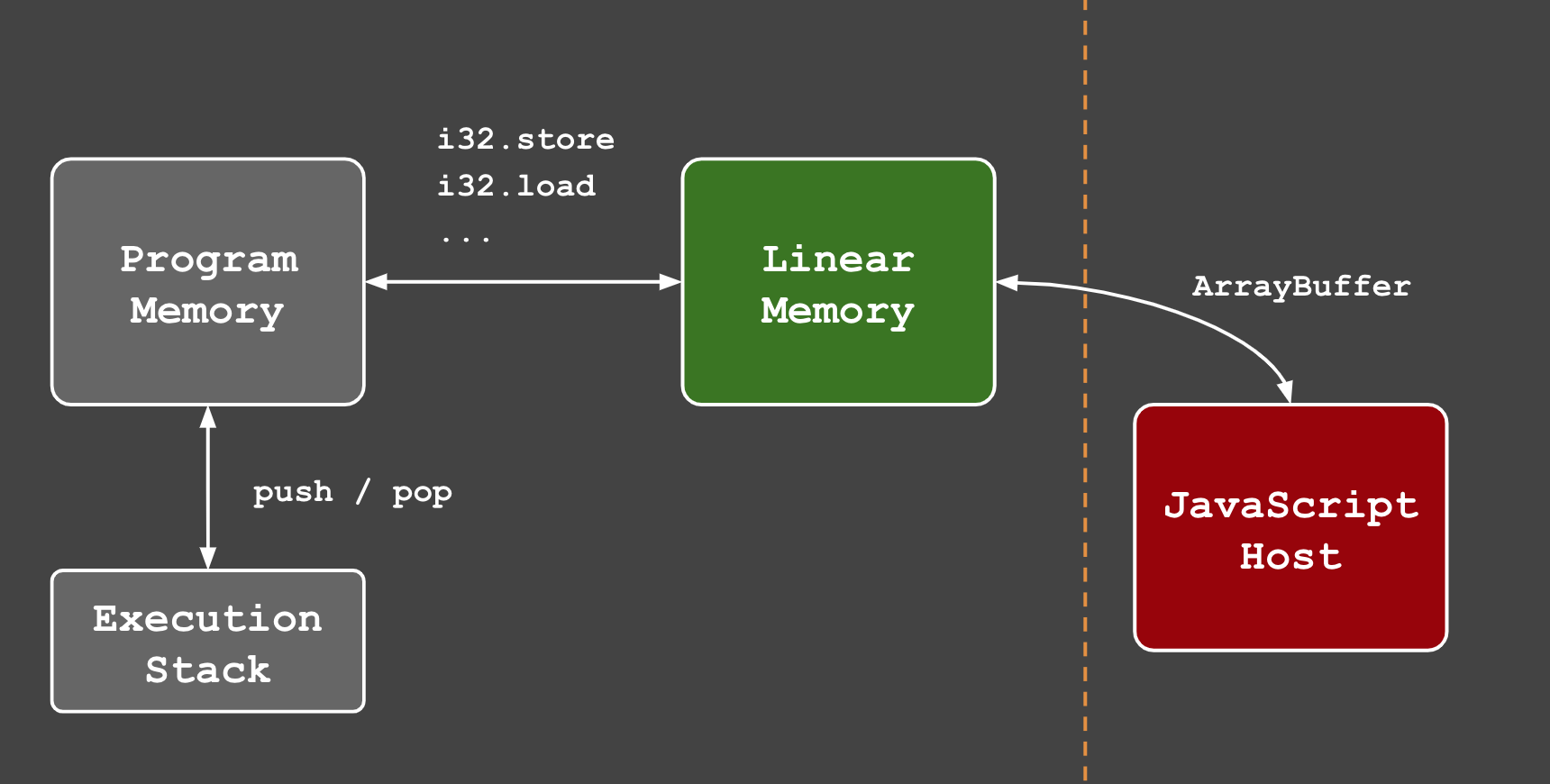
Как упоминалось ранее, WA имеет всего 4 числовых типа данных. Как язык с более богатой системой типов (строка, структура, массив и др.) может быть скомпилирован в wasm?
Модули могут определять (или импортировать) блоки линейной памяти, представляющие собой непрерывные блоки памяти, распределяемые между модулями и их хостами - оба могут читать и писать в эту память. Таким образом, для передачи в модуль строки мы записываем ее в линейную память.
Нам нужен какой-то способ отображения результата, поэтому мы будем использовать линейную память как разновидность ОЗУ для видео (Video Random Access Memory, VRAM).
chasm поддерживает простую команду setpixel, которая принимает 3 параметра: координату x, координату y и цвет (color). Например, такая программа заливает экран горизон�тальным градиентом:
var y = 0
while (y < 100)
var x = 0
while (x < 100)
setpixel x y (x * 2)
x = (x + 1)
endwhile
y = (y + 1)
endwhile
Поиграть с этой программой можно здесь.
Команда setpixel реализована с помощью wasm-инструкции store, которая позволяет писать в линейную память. На стороне хоста (JS) эта память читается и переносится на холст (canvas) HTML. Реализацию данной команды можно найти здесь.
На этом разработку chasm можно считать завершенной. Разработанный нами язык прекрасно справляется с задачей рендеринга множеств�а Мандельброта:
Благодарю за внимание и happy coding!