Привет, друзья!
Представляю вашему вниманию перевод этой замечательной статьи, которая содержит интересный обзор истории развития веб-разработки с точки зрения используемой архитектуры.
Веб состоит из технологий, появившихся более 25 лет назад. HTTP, HTML, CSS и JS были стандартизированы в середине 90-х (когда мне было 8 лет). С тех пор веб эволюционировал в вездесущую платформу приложений. Одновременно с эволюцией веба развивалась и архитектура разработки соответствующих приложений. Сегодня существует большое количество архитектур, которые можно использовать для разработки веб-приложений. В настоящее время самой популярной из них является "Одностраничное приложение" (Single Page App, SPA), но сейчас наблюдается переход к новой улучшенной архитектуре.
Элементы <a> и <form> были с нами с самого начала. Ссылки для получения чего-либо от сервера и формы для отправки чего-либо на сервер (и получения чего-либо в ответ). Эта двусторонняя коммуникация, являющаяся частью первоначальной спецификации, дает возможность создавать мощные приложения для веба.
Основные архитектуры (в хронологическом порядке пика популярности):
- Многостраничное приложение (Multi-Page App, MPA).
- Прогрессивно улучшенное многостраничное приложение (Progressively Enhanced Multi-Page App, PEMPA, приложения с так называемыми "вкраплениями JavaScript").
- SPA.
- Следующий этап.
Каждая архитектура веб-разработки имеет свои преимущества и недостатки. В конечном счете, недостатки становятся мотивацией для перехода к следующей архитектуре, которая также имеет свою цену.
Неважно, как мы разрабатываем приложения, нам почти всегда требуется код, выполняемый на сервере. Разница между архитектурами состоит в том, где код "живет". Изучим каждую архитектуру и посмотрим, как в течение времени менялась локация кода. При изучении архитектуры мы будем акцентировать внимание на следующих вещах:
- хранилище (persistence) - запись и чтение данных из базы данных;
- маршрутизация (routing) - направление трафика на основе адреса (
URL); - получение данных (data fetching) - извлечение данных из хранилища;
- модификация (мутация) данных (data mutation) - изменение данных в хранилище;
- логика рендеринга (rendering logic) - отображение данных для пользователя;
- обратная связь пользовательского интерфейса (UI Feedback) - ответ
UIна действия пользователя.
На самом деле, существует гораздо больше частей, из которых состоит веб-приложение, но �указанные элементы присутствуют всегда, на их разработку уходит большая часть времени. В зависимости от масштаба проекта и структуры команды, мы можем работать над всеми этими категориями или только над частью одной.
MPA
В начале существовала только одна архитектура, которая могла использоваться для разработки веб-приложений на основе возможностей браузеров того времени.
MPA
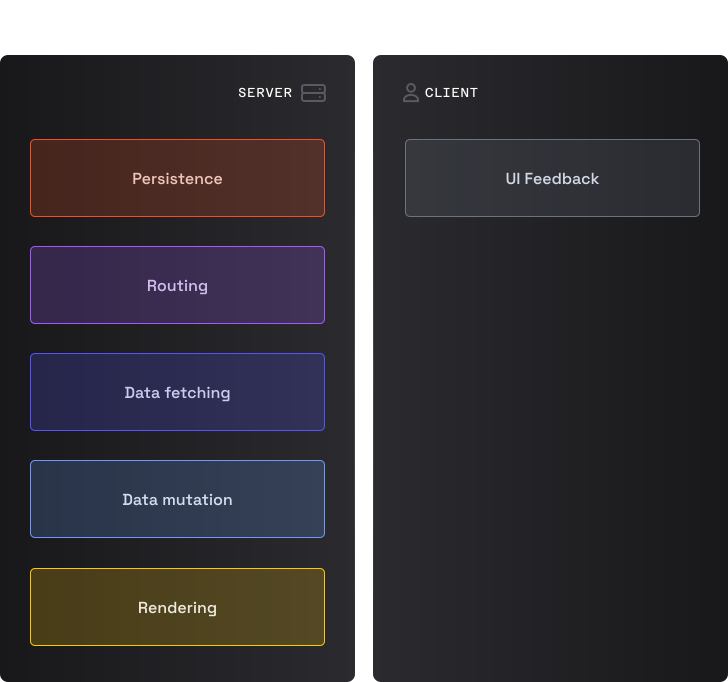
В MPA весь код живет на сервере. Код UI на клиенте обрабатывается браузером пользователя.
Архитектурные особенности MPA
Запрос документа
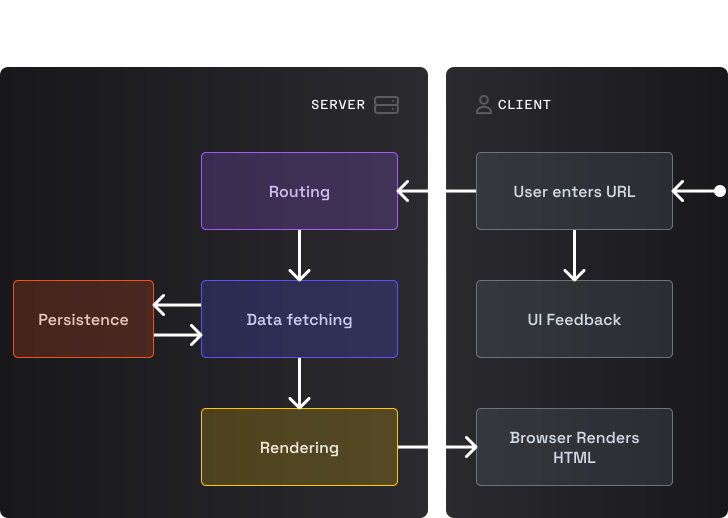
Когда пользователь вводит URL в адресной строке, браузер отправляет запрос на сервер. Логика маршрутизации вызывает функцию для получения данных, которая взаимодейс�твует с кодом хранилища для извлечения данных. Затем эти данные используются логикой рендеринга для определения страницы (HTML), которая будет отправлена в качестве ответа клиенту. Все это время браузер каким-то образом дает пользователю обратную связь о состоянии ожидания (pending state) (например, с помощью фавиконки).
Запрос на модификацию данных с перенаправлением
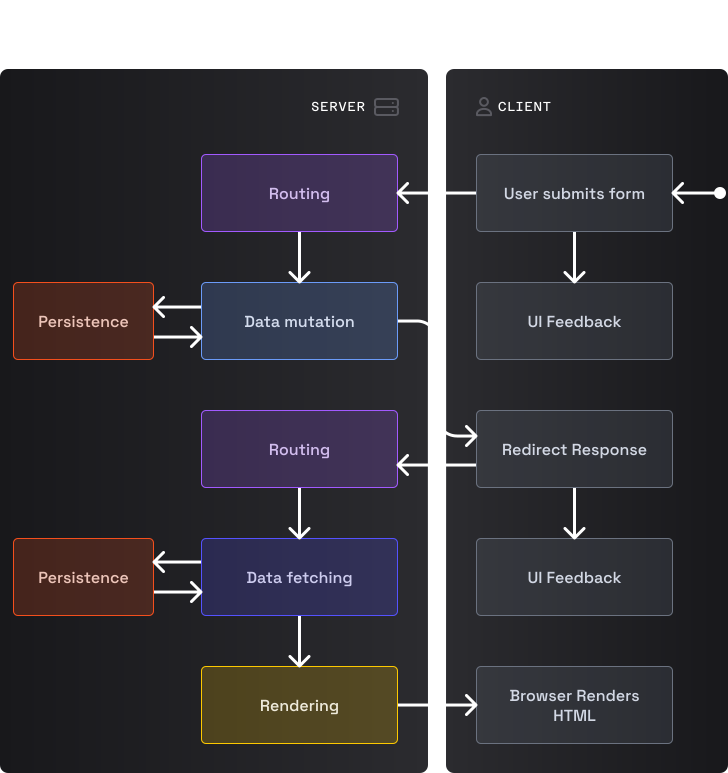
Когда пользователь отправляет форму, браузер сериализует (преобразует в формат JSON) данные формы, включает их в запрос и отправляет на сервер. Логика маршрутизации вызывает функцию для модификации данных, которая взаимодействует с кодом хранилища для обновления базы данных. Далее клиенту возвращается ответ с перенаправлением, на что браузер реагирует отправкой GET-запроса для получения свежего UI (это запускает процесс, аналогичный тому, что происходит при вводе пользователем URL). Снова браузер каким-то образом сообщает пользователю о состоянии ожидания.
Обратите внимание: важно, чтобы успешная мутация отправляла ответ с перенаправлением, а не новый HTML. В противном случае, в стек истории попадет POST-запрос и нажатие кнопки "Назад" в браузере приведет к повторному выполнению данного запроса.
Преимущества и недостатки MPA
Ментальная модель MPA является очень простой. Мы не ценили этого раньше. Несмотря на наличие некоторого состояния и сложных потоков данных, обрабатываемых преимущественно с помощью куки в запросах, большая часть всего происходила в цикле запрос-ответ.
Недостатки:
- Полная перезагрузка страницы затрудняет реализацию некоторых вещей (например, управление фокусом), делает другие вещи непрактичными (представьте полную перезагрузку при каждом лайке твита), а некоторые - вообще невозможными (например, анимированные переходы между страницами).
- Управление обратной связью
UI. Прикольно, что фавиконка превращается в спиннер, но часто лучший пользовательский опыт (User Experience, UX) означает �визуальную близость к той частиUI, с которой в данный момент взаимодействует пользователь. Это то, что любят кастомизировать дизайнеры в целях брендинга.
Следует отметить, что недавно представленный Page transitions API расширяет некоторые возможности MPA. Но для большинства приложений этого все равно будет недостаточно.
PEMPA
Прогрессивное улучшение - это идея о том, что веб-приложение должно быть функциональным и доступным во всех браузерах и использовать любые возможности для улучшения UX, предоставляемые конкретным браузером. Термин PEMPA был предложен Nick Finck и Steve Champeon в 2003 году. Говоря о возможностях браузера...
XMLHttpRequest был разработан командой Microsoft Outlook Web Access в 1998, а стандартизирован только в 2016 (можете в это поверить!?). Разумеется, это никогда не останавливало производителей браузеров и веб-разработчиков. AJAX обрел популярность в 2005, �и многие люди начали отправлять HTTP-запросы в браузере. Бизнес исходил из предположения, что нам требуется обращаться к серверу только за небольшой порцией данных для локального обновления UI. Это позволяло разрабатывать PEMPA.
PEMPA

"Погодите... - скажете вы. - Откуда взялся весь этот код?". Теперь мы отвечаем не только за UI в браузере, но также получили маршрутизацию, получение данных, модификацию данных и логику рендеринга на клиенте в дополнение к тому, что у нас имеется на сервере. "Что это дает?".
Дело вот в чем. Сутью прогрессивного улучшения является то, что приложение всегда должно оставаться функциональным. В начале 2000-х мы не могли гарантировать, что пользователь будет использовать браузер, понимающий AJAX, или что скорость сети пользователя позволит загрузить JS до взаимодействия пользователя с приложением. Поэтому нам нужно сохранить существующую архитектуру MPA и использовать JS для улучшения UX.
В зависимости от уровня улучшения, может потребоваться писать ко�д почти во всех категориях, за исключением хранилища (до тех пор, пока мы не захотим реализовать поддержку оффлайн-режима, что здорово, но не является стандартной практикой в индустрии).
Кроме того, необходимо дополнить код на сервере для поддержки AJAX-запросов, отправляемых клиентом.
Это эпоха jQuery, MooTools и т.д.
Архитектурные особенности PEMPA
Запрос документа
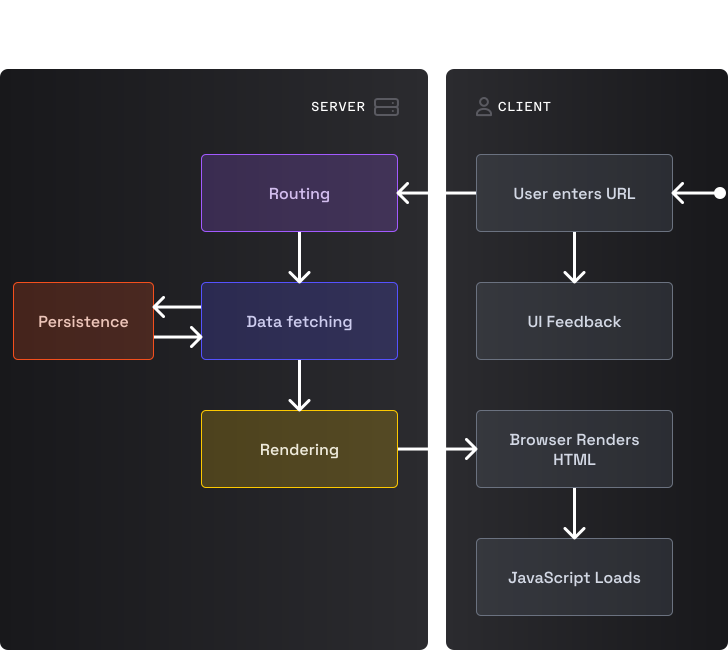
Здесь происходит тоже самое, что при запросе документа в MPA. Однако PEMPA также загружает клиентский JS, используемый для прогрессивных возможностей, посредством добавления на страницу тегов <script>.
Маршрутизация на стороне клиента
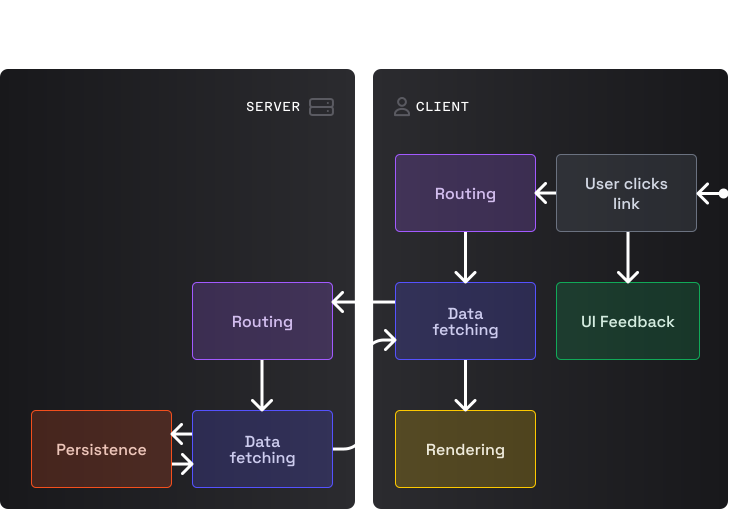
Когда пользователь кликает по ссылке, клиентский код получения данных предотвращает дефолтную перезагрузку страницы и использует JS для обновления URL. Затем клиентская логика рендеринга определяет, какие части UI нуждаются в обновлении и вручную выполняет эти обновления, включая любые состояния ожидания (обратная связь UI). В это время библиотека для получения данных выполняет сетевой запрос к конечной точке на сервере. Серверная логика маршрутизации вызывает код получения данных для извлечения данных из хранилища и отправляет их в качестве ответа (как XML или JSON, у нас есть выбор:)). Наконец, полученные от сервера данные используются клиентской логикой рендеринга для выполнения финального обновления UI.
Обычный запрос на модификацию данных

Запрос на модификацию данных с перенаправлением
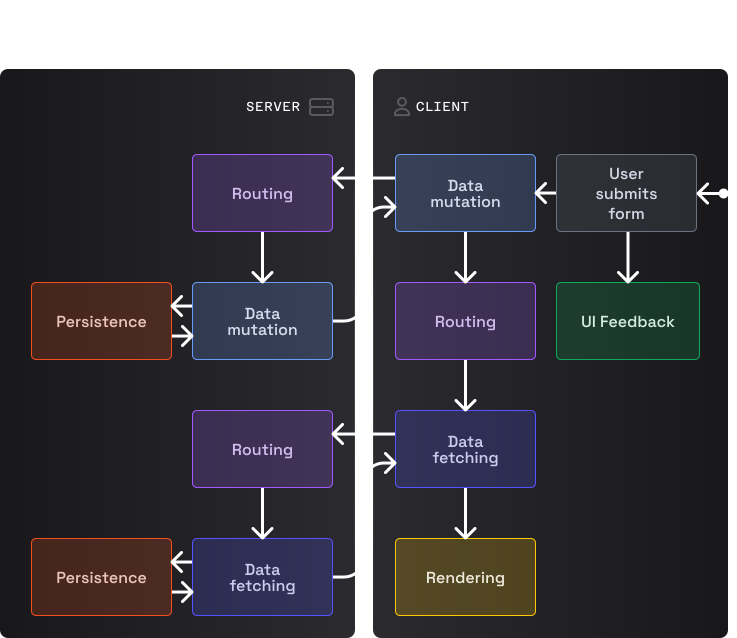
Когда пользователь отправляет форму, клиентская логика модификации данных предотвращает дефолтное поведение браузера (перезагрузку страницы и отправку формы методом POST) и использует JS для сериализации формы и отправки данных на сервер. Серверная логика маршрутизации вызывает функцию модификации данных, которая взаимодействует с кодом хранилища для выполнения мутации и отвечает клиенту обновленными данными. Клиентская логика рендеринга использует новые данные для обновления UI при необходимости. В некоторых случаях клиентская логика рендеринга отправляет пользователя в другое место, что запускает процесс, аналогичный тому, который происходит при маршрутизации на стороне клиента.
Преимущества и недостатки PEMPA
PEMPA определенно решили многие проблемы MPA, расширив возможности клиентского кода. Мы получили больше контроля и могли обеспечивать лучший UX.
К сожалению, для этого приходилось работать над маршрутизацией, получением данных, их модификацией и логикой рендеринга. С этим были связаны такие проблемы, как:
- Предотвращение дефолтного поведение браузера. С маршрутизацией и отправкой формы мы справляемся не так хорошо, ка�к это делает браузер. Раньше обеспечение актуальности данных на странице не являлось проблемой, теперь половина клиентского кода занималась решением этой задачи. Более того, гонка условий, повторная отправка формы и обработка ошибок стали хорошими местами для скрытых багов.
- Кастомный код. Кода стало намного больше, а чем больше кода, тем больше ошибок.
- Дублирование кода. Большое количество кода дублируется в логике рендеринга. Клиентский код должен обновлять
UIпо аналогии с тем, как серверный код рендерит каждое возможное состояние после мутации или маршрутизации. Поэтому одинаковые частиUIхранятся как на сервере, так и на клиенте. Чаще всего код сервера и код клиента написаны на разных языках, что делает совместное или повторное использование кода невозможным. И речь идет не только о шаблонах (templates), но также о логике. Задача формулируется следующим образом: "выполни взаимодействие на стороне клиента, а затем убедись в том, что результат идентичен полной перезагрузке страницы". Эту задачу удивительно сложно решить. - Организация кода. В
PEMPA- это сложная задача. �При отсутствии централизованного места для хранения данных или рендерингаUI, код обновленияDOMимеет локальный характер. С таким кодом сложно работать, что снижает скорость разработки. - Тесная связь между сервером и клиентом. Между роутами
APIи клиентским кодом получения и модификации данных существует тесная связь. Изменения на одной стороне влекут необходимость изменений на другой стороне. Становится сложно гарантировать, что ничего не сломалось без просмотра множества файлов. Сеть стала барьером, породившим эту проблему, подобно тому, как лиса использует реку для того, чтобы сбить гончих со следа.
К слову, именно в это время я пришел в веб-разработку. Воспоминания об этом времени вызывают во мне одновременно глубокую ностальгию и дрожь по всему телу.
SPA
Потребовалось совсем немного времени для осознания того, что мы можем удалить дублирующийся код, если просто удалим код UI на сервере. И вот к чему мы пришли:
SPA

Этот график почти идентичен графику PEMPA. Единственное отличие - в логике рендеринга. Также стало меньше кода маршрутизации, поскольку нам больше не требуются роуты для UI. У нас остались только роуты API. Это эпоха Backbone, Knockout, Angular, Ember, React, Vue, Svelte и др. Это стратегия, которая используется сегодня большей частью индустрии.
Архитектурные особенности SPA
Запрос документа
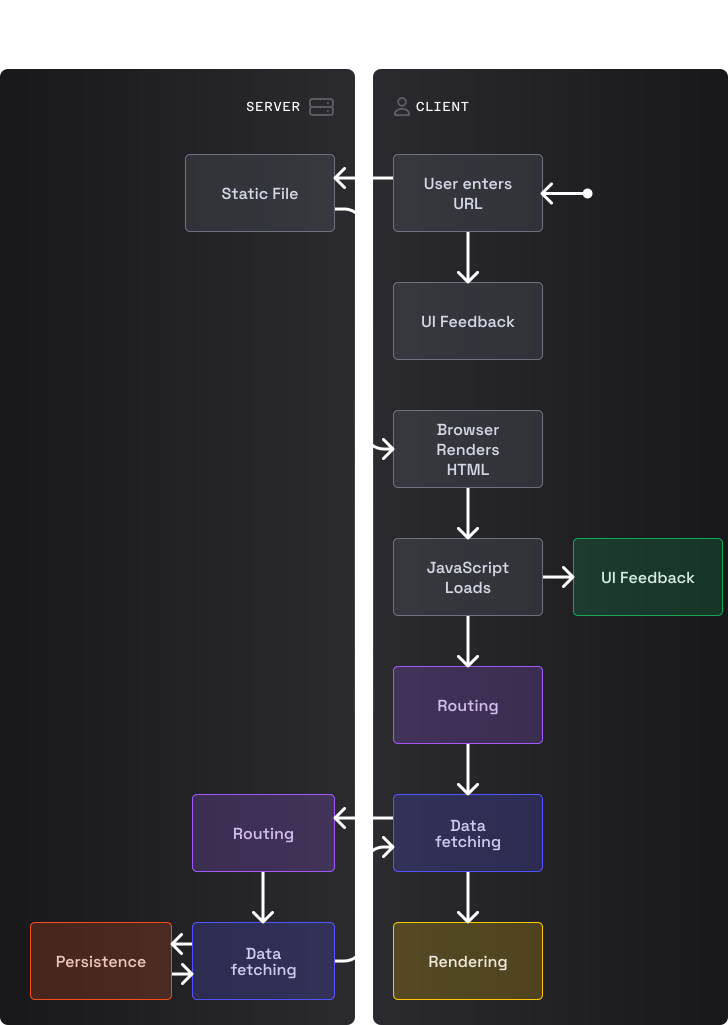
Поскольку на сервере больше нет логики рендеринга, все запросы документов (первый запрос пользователь делает, когда вводит URL) обслуживаются сервером статических файлов (обычно сетью доставки контента, Content Delivery Network, CDN). В начале появления SPA документ HTML почти всегда представлял собой почти пустой файл HTML с <div id="root"></div> в <body>, который используется для "монтирования" приложения. Однако в настоящее время фреймворки позволяют предварительно рендерить любое количество страниц, известных во время сборки, с помощью техники под названием "Статическая генерация контента" (Static Site Generation, SSG).
Маршрутизация на стороне клиента
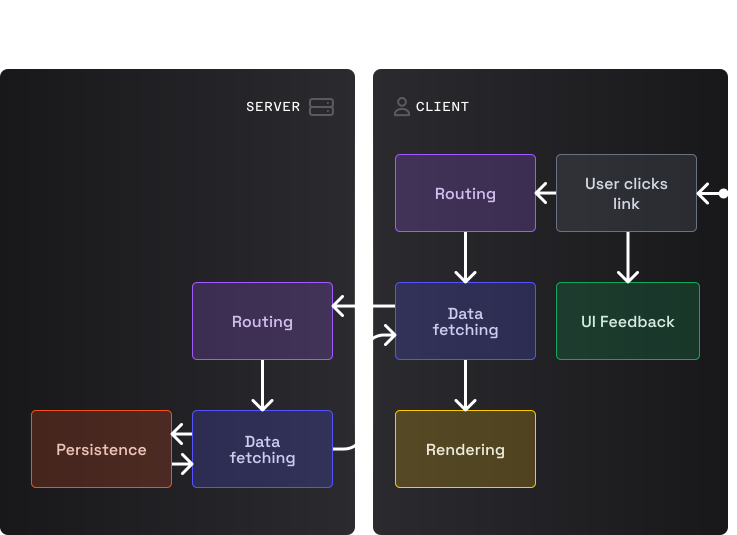
Обычный запрос на модификацию данных
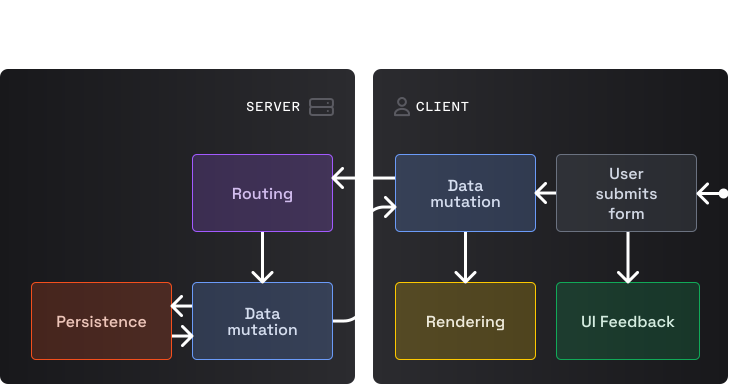
Запрос на модификацию данных с перенаправлением

Это похоже на PEMPA, только вместо XMLHttpRequest в основном используется fetch.
Преимущества и недостатки
Что интересно, единственная разница между SPA и PEMPA с точки зрения архитектуры заключается в том, что запрос документа стал хуже. Так зачем нам SPA?
Основным преимуществом SPA является опыт разработки (Developer Experience, DX). Это было основной дв�ижущей силой перехода от PEMPA к SPA. Отсутствие дублирующегося кода - другое большое преимущество. Мы оправдывали это изменение различными способами (в конце концов, DX - это вход в UX). К сожалению, улучшение DX - это все, что в действительности дали нам SPA.
Лично я долгое время был убежден, что архитектура SPA помогает улучшить производительность, поскольку CDN отвечают документом HTML быстрее, чем сервер генерирует его, но в реальном мире это никогда не имело особого значения (и современная инфраструктура делает это утверждение еще менее правдоподобным). Печальная истина состоит в том, что SPA имеют те же проблемы, что и PEMPA, хотя современные инструменты сильно облегчают работу.
Кроме того, SPA имеют собственные недостатки, такие как:
- Размер сборки. Это своего рода взрыв. Подробнее о влиянии
JSна производительность веб-страницы можно почитать здесь. - Водопады. Поскольку весь код для получения данных живет в сборке
JS, нам приходится ждать его загрузки перед началом получения данных. Это приводит к необходимости разделения кода и ленивой загрузки. В результате мы получаем ситуацию критической зависимости, например:document→app.js→page.js→component.js→data.json→image.png. Это не круто и выливается в худшийUX. Для статического контента многое из этого не актуально, но существует целый ряд проблем и ограничений, над которыми работают разработчики стратегийSSG. - Производительность времени выполнения. Такое количество клиентского
JSдля выполнения является серьезной проблемой для некоторых устройств с низким энергопотреблением (см. Стоимость JavaScript). То, что раньше выполнялось на наших мощных серверах, теперь должно выполняться на мини-компьютерах пользователей. - Управление состоянием. Это стало огромной проблемой. Для того, чтобы убедиться в правдивости моих слов, достаточно взглянуть на количество доступных библиотек для решения этой проблемы. Раньше
MPAрендерил состояние вDOM, а мы просто ссылались на него или модифицировали его. Теперь мы получаемJSONи должны не только сообщать серверу об изменении данных, но и обеспечивать актуальность состояния в памяти. Это имеет все признаки проблем кэширования (потому что так и есть), что является одной из самых сложных проблем в разработке программного обеспечения. В типичномSPAуправление состоянием представляет 30-50% кода, над которым работают люди.
Было разработано большое количество библиотек для решениях этих проблем или уменьшения их влияния. Фактически это стало стандартом разработки веб-приложений в середине 2010-х. Сейчас мы находимся в 2020-х, и на горизонте появились некоторые новые идеи.
Прогрессивно улучшенные одностраничные приложения (Progressively Enhanced Single Page Apps, PESPA)
MPA имеют простую ментальную модель. SPA предоставляют более широкие возможности. Коллеги, которые прошли через MPA и работают с SPA сетуют на утрату простоты за последнее десятилетие. Это очень интересно, учитывая то обстоятельство, что основной мотивацией для создания архитектуры SPA было улучшение DX по сравнению с PEMPA. Если бы мы каким-то образом могли объединить SPA и MPA в единую архитектуру, мы получили бы лучшее от обеих архитектур, т.е. мы получили бы нечто простое, но вместе с тем обладающее широкими возможностями. Это то, чем является PEMPA.
В основе прогрессивного улучшения лежит идея о том, что приложение должно оставаться функциональным даже без клиентского JS. Если ключевым принципом нашего фреймворка является прогрессивное улучшение, то архитектура нашего приложения соответствует простой ментальной модели MPA. Речь идет о ментальной модели представления о вещах в контексте цикла запрос-ответ. Это позволяет существенно уменьшить количество проблем, характерных для SPA.
Обратите внимание: основное преимущество прогрессивного улучшения состоит не в том, что приложение работает без JS, а в том, что ментальная модель становится гораздо проще.
Для достижения этой цели PESPA должны имитировать поведение браузера при отключении его дефолтного поведения. Серверный код работает одинаково, независимо от того, выполняется ли запрос браузером или с помощью основанного на JS fetch. Это позволяет сохранить простую ментальную модель в остальной части нашего кода. Важным моментом является то, что PESPA имитирует поведение браузера при повторной валидации данных на странице после выполнения мутаций для обеспечения их актуальности. В MPA это обеспечивается за счет полной перезагрузки страницы. В PESPA эта ревалидация выполняется с помощью запросов fetch.
Серьезной проблемой PEMPA является дублирование кода. PESPA решает эту проблему за счет того, что серверный и клиентский код UI являются идентичными. Используя библиотеку UI, способную выполнять рендеринг на сервере и интерактивные обновления/обработку на клиенте, мы решаем проблему дублирования кода.
PESPA
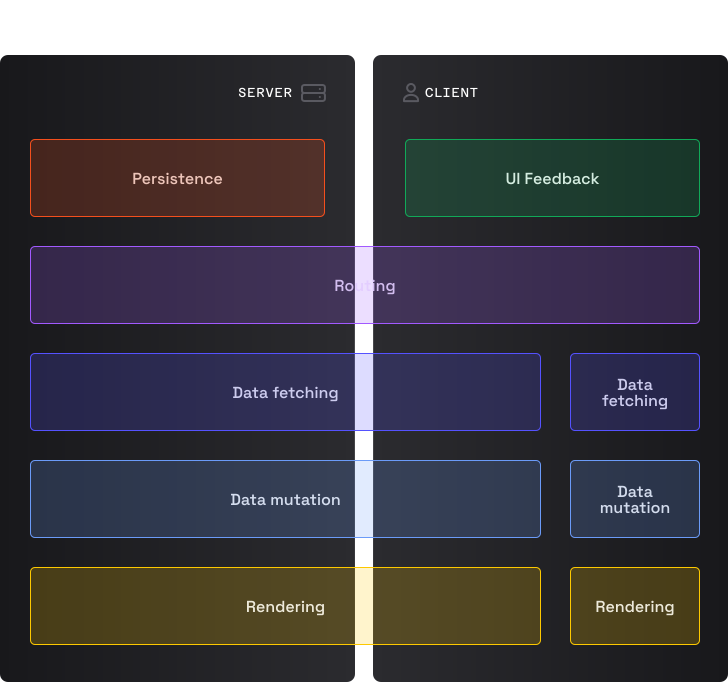
Обратите внимание на маленькие прямоугольники для получения данных, их модификации и рендеринга. Эти части предназначены для прогрессивного улучшения. Например, состоянию ожидания, оптимистическому UI и т.д. не место на сервере, поэтому соответствующий код выполняется только на клиенте. Но даже с учетом этого предоставляемая современными библиотека UI возможность колокации (совместного размещения состояния) делает наличие данных частей вполне приемлемым.
Архитектурные особенности PESPA
Запрос документа

Запрос документа в PESPA идентичен запросу документа в PEMPA. Начальный HTML "прилетает" от сервера, а JS подгружается для улучшения UX.
Маршрутизация на стороне клиента

Когда пользователь кликает по ссылке, мы предотвращаем дефолтное поведение браузера. Наш роутер определяет данные и UI для нового маршрута, получает данные и рендерит UI.
Обычный запрос на модификацию данных
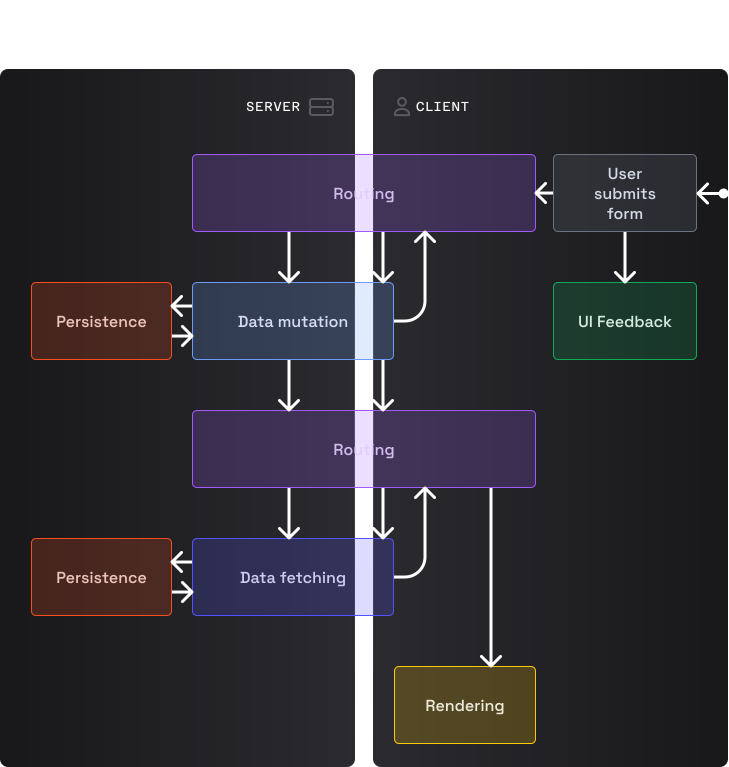
Запрос на модификацию данных с перенаправлением
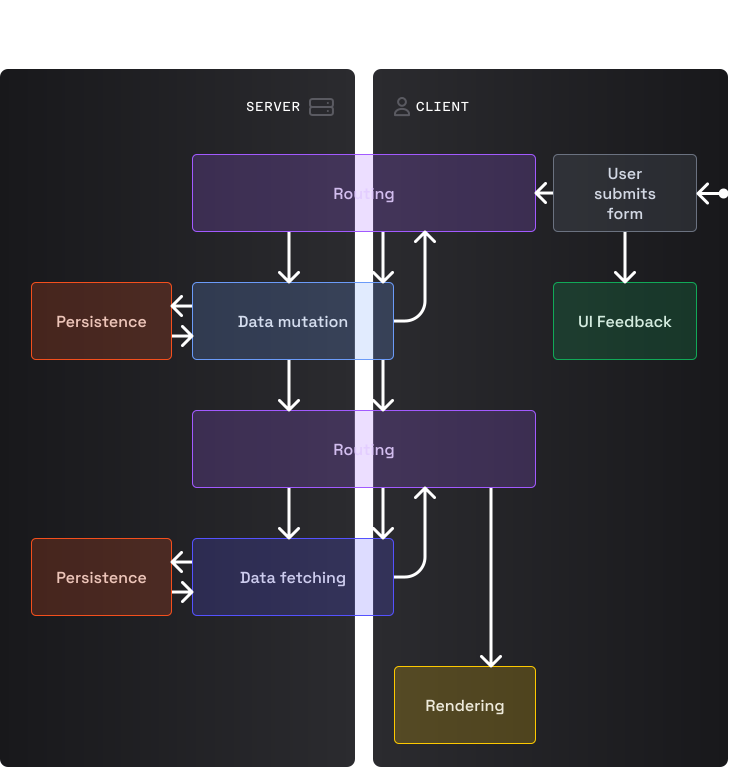
Заметили, что два последних графика одинаковые? Да! Это не ошибка! Мутации в PESPA выполняются с помощью отправки форм. Больше никаких бессмысленных onClick + fetch (однако императивные мутации хорошо подходят для прогрессивного улучшения, такого как перенаправление на страницу авторизации при окончании сессии пользователя). При отправке формы пользователем, мы предотвращаем поведение по умолчанию. Код мутации сериализует форму и отправляет запрос роуту, указанному в атрибуте action формы (по умолчанию таким роутом является текущий URL). Логика маршрутизации на сервере обращается к коду операции, который взаимодействует с кодом хранилища для выполнения обновления и возвращает успешный ответ (например, при лайке твита) или ответ с перенаправлением (например, при создании нового GitHub-репозитория). В случае перенаправления роутер загружает код/данные/ресурсы для данного маршрута (параллельно) и запускает процесс рендеринга. В противном случае, роутер ревалидирует данные для текущего UI и запускает процесс рендеринга для обновления UI. Независимо от того, о какой мутации идет речь, обычной или с перенаправлением, участие роутера обеспечивает одну и ту же ментальную модель для обоих типов.
Преимущества и недостатки PESPA
PESPA решает многие проблемы предшествующих архитектур. Рассмотрим их по порядку.
Проблемы MPA:
- Перезагрузка всей страницы.
PESPAпредотвращает дефолтное поведение браузера и использует клиентскийJSдля имитации этого поведения. С точки зрения кода, который мы пишем, это не отличается отMPA, но с точки зрения пользователя, это сильно улучшает опыт использования приложения. - Управление обратной связью
UI.PESPAпозволяют полностью контролировать процесс выполнения сетевых запросов, поскольку мы предотвращаем дефолтное поведение и выполняемfetch-запросы. Это позволяет давать пользователям такую обратную связь, которая лучше всего подходит для нашегоUI.
Проблемы PEMPA:
- Предотвращение поведения по умолчанию. Ключевым аспектом
PESPAявляется подражание браузеру как в части маршрутизации, так и в части обработки отправки формы. Это обеспечивает сохранение ментальной моделиMPA. Отмена запросов на повторную отправку формы, обработка ответов, приходящих в неправильном порядке, и устранение ошибок, приводящих к вечным спиннерам - все это является неотъемлемой частьюPESPA. В этом заключается реальная помощь фреймворка. - Кастомный код. Распределение кода между клиентом и сервером и наличие правильных абстракций для эмуляции поведения браузера приводит к существенному уменьшению количества кода, который нужно писать самостоя�тельно.
- Дублирование кода. Одной из основных идей
PESPAявляется то, что код логики рендеринга на сервере и клиенте должен быть одинаковым. Другими словами, в этой части отсутствует дублирование. Вызов "обновиUIна клиенте и убедись в том, что результат идентичен полной перезагрузке страницы" вPESPAне существует. - Организация кода. Благодаря ментальной модели
PESPAэто больше не является проблемой. Поскольку логика рендеринга является одинаковой по обе стороны сети, случайные мутацииDOMпрактически исключены. - Несогласованность клиента и сервера.
PESPAимитирует поведение браузера. Это означает, что код сервера и клиента хорошо согласуется между собой, что, в свою очередь, делает нас гораздо более продуктивными.
Проблемы SPA
- Размер сборки. Переход на
PESPAтребует наличия сервера. Это означает, что мы можем перенести тонну нашего кода на сервер. Все, что требуется на клиенте - это небольшая библиотекаUI, которая может запускаться как на клиенте, так и на сервере, чуть-чуть кода для обработки взаимодействия пользователя сUIи ответной реакцииUIна действия пользователя и код компонентов. Благодаря разделению кода на основе роутов мы можем наконец-то сказать прощай тысячам КбJS. Благодаря прогрессивному улучшению большая часть приложения должна работать до окончания загрузкиJS. Более того, сейчас ведется активная работа по уменьшению количестваJS, необходимого на клиенте. - Водопады. Важной частью
PESPAявляется то, что они могут знать о требованиях к коду, данным и ресурсам для данногоURLбез необходимости выполнения какого-либо кода. Это означает, что, в дополнение к разделению кода,PESPAмогут получать код, данные и ресурсы одновременно, а не последовательно. Это также означает, чтоPESPAмогут запрашивать эти вещи до того, как пользователь запустил процесс навигации, что делает переход на новую страницу почти мгновенным. Разумеется, это обеспечивает великолепныйUX. - Производительность времени выполнения.
PESPAрешает эту проблему двумя способами: 1) большое количество кода перемещается на сервер, поэтому меньше кода выполняется на устройстве пользователя; 2) благодаря прогрессивному улучшениюUIготов к использованию до полной загрузки и выполненияJS. - Управление состоянием. В контексте
PESPAэта проблема не стоит так остро, как вSPA. Это связано с тем, что большая часть приложения работает вообще безJS.PESPAавтоматически ревалидирует данные на странице после завершения мутации (вMPAэто решается за счет полной перезагрузки страницы).
Важно отметить, что в зависимости от наличия клиентского JS PESPA работает по-разному. Но это и не является целью прогрессивного улучшения. Просто большая часть приложения должна работать без JS. И дело не только в UX. Цель прогрессивного улучшения - существенное упрощение кода UI. Вы удивитесь, как далеко мы можем зайти без JS, но для некоторых приложений нет необходимости или практической значимости того, чтобы все работало без клиентского JS. Но даже если некоторые элементы нашего UI требуют некоторый код JS, мы все еще можем пожинать основные преимущества, предоставляемые PESPA.
Основные особенности PESPA:
- функциональность является основой -
JSиспользуется для улучшения; - ленивая загрузка + умное предварительное получение данных (больше, чем просто
JS-код); - перемещение кода на сервер;
- отсутствие дублирования кода
UI(как вPEMPA); - прозрачная имитация поведения браузера (#useThePlatform).
Что касается недостатков, то они не столь очевидны. Вот некоторые мысли на этот счет.
Многим людям, использующим SPA и SSG, не понравится, что код приложения выполняется на сервере. Однако ни одно реальное приложение не обходится без серверного кода. Разумеется, в некоторых случаях мы можем разработать сайт и разместить его в CDN, но большинство приложений, над которыми мы работаем, не попадают в эту категорию.
Есть люди, которые выражают беспокойство относительно цены сервера. Суть в том, что SSG позволяет создать сборку приложения и обслуживать ее через CDN для любого количества пользователей по очень низкой цене. Здесь существует два недочета. 1) Наше приложение, скорее всего, будет взаимодействовать с API, поэтом�у дорогой серверный код все равно будет выполняться при каждом посещении пользователя. 2) CDN поддерживают механизмы кэширования, поэтому если у нас есть возможность использовать SSG, мы можем воспользоваться этим и получить как быстрые ответы, так и небольшой объем работы, выполняемой сервером для рендеринга приложения.
Другой проблемой, с которой сталкиваются разработчики SPA, является необходимость реализации рендеринга на сервере. Это определенно другая модель для людей, запускающих код только на клиенте, но существуют инструменты, которые в значительной степени облегчают выполнение этой задачи. Без соответствующих инструментов это может быть серьезным вызовом, но существуют разумные обходные пути, чтобы оставить определенный код на клиенте во время миграции.
Как я отметил, мы все еще работает над выявлением недостатков PESPA, но с уверенностью можно сказать, что преимуществ гораздо больше.
Реализация PESPA: Remix
Ведущим инструментом для разработки PESPA является Remix, веб-фреймворк с акцентом на веб-стандартах и современном UX. Remix - первый фреймворк, предоставляющий все необходимое для разработки PESPA. Другие фреймворки могут или уже адаптируются к правилам игры, введенным Remix. Речь идет, в первую очередь, о SvelteKit и SolidStart, команды которых работают над внедрением принципов PESPA. Я предполагаю, что это только начало. Вот как выглядит архитектура PESPA в Remix:

В данном случае Remix - это мост через сеть. Без Remix этот мост придется возводить самостоятельно. Маршрутизация в Remix основана на соглашениях и конфигурациях. Remix также помогает с частями, предназначенными для прогрессивного улучшения, такими как получение данных и их модификация (например, лайк твита), а также обратная связь UI (например, состояние ожидания и оптимистическое обновлен�ие UI).
Благодаря встроенной в Remix вложенной маршрутизации, мы также получаем лучшую организацию кода (нечто похожее имеется в Next.js). Несмотря на то, что вложенный роутинг не является обязательным в PESPA, разделение кода на основе маршрутов является очень важной частью. Вложенный роутинг позволяет разделять код на еще меньшие части, что тоже является важным аспектом.
Remix показывает себя очень хорошо в разработке приложений, следующих архитектуре PESPA. Вот один из примеров:

Согласитесь, что результаты выглядят впечатляюще?
Заключение
Лично я полностью за переход к новому этапу. Получение лучшего UX и DX в одно и тоже время - это сплошная выгода. В качестве вознаграждения для тех, кто дочитал эту статью до конца, вот репозиторий с кодом TodoMVC для всех рассмотренных архитектур.
Благодарю за внимание и happy coding!