Фильтр Блума
Описание
Фильтр Блума (Bloom filter) - это пространственно-эффективная вероятностная структура данных, предназначенная для определения наличия элемента во множестве. С одной стороны, эта структура является очень быстрой и использует минимальный объем памяти, с другой стороны, возможны ложноположительные (false positive) результаты. Ложноотрицательные (false negative) результаты невозможны. Другими словами, фильтр возвращает либо "элемент МОЖЕТ содержаться во множестве", либо "элемент ТОЧНО НЕ содержится во множестве". Фильтр Блума может использовать любое количество памяти, но, как правило, чем больше памяти, тем ниже вероятность ложноположительных результатов.
Блум предложил эту технику для применения в областях, где количество исходных данных потребовало бы непрактично много памяти в случае применения условно безошибочных техник хеширования.
Описание алгоритма
Пустой фильтр Блума представлен массивом из m битов, установленных в 0. Должно быть определено k независимых хеш-функций, отображающих каждый элемент множества в одну из m позиций массива, генерируя единообразное случайное распределение. Обычно k задается константой, которая намного меньше m и пропорциональна количеству добавляемых элементов. Точный выбор k и постоянной пропорциональности m определяются уровнем ложных срабатываний фильтра.
Вот пример фильтра Блума, представляющего множество {x, y, z}. Цветные стрелки показывают позиции (индексы) битового массива, соответствующие элементам множества. Элемент w не содержится во множестве {x, y, z}, потому что он привязан к позиции массива, равной 0. В данном случае m = 18, а k = 3.
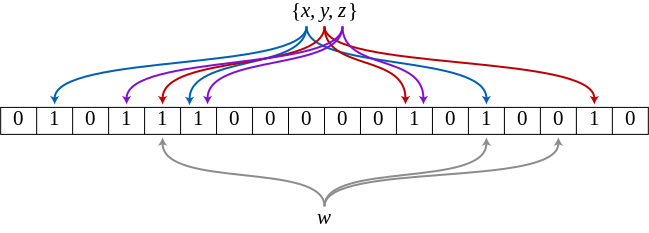
Для добавления в фильтр элемента e необходимо записать 1 в каждую позицию h1(e), ..., hk(e) (хеш-функции) битового массива.
Для определения наличия элемента e во множестве необходимо проверить состояние битов h1(e), ..., hk(e). Если хотя бы один бит имеет значение 0, элемент отсутствует. Если все биты имеют значение 1, структура сообщает, что элемент присутствует. При этом, может возникнуть две ситуации: либо элемент действительно содержится во множестве, либо все биты оказались установлены случайно при добавлении других элементов. Второй случай является источником ложноположительных результатов.
Операции
Фильтр Блума позволяет выполнять две основные операции: вставка и поиск элемента. Поиск может завершаться ложноположительными результатами. Удаление элементов возможно, но проблематично.
Другими словами, в фильтр можно добавлять элементы, а на вопрос о наличии элемента структура отвечает либо "нет", либо "возможно".
Операции вставки и поиска выполняются за время O(1).
Создание фильтра
При создании фильтра указывается его размер. Размер нашего фильтра составляет 100. Все элементы устанавливаются в false (по сути, тоже самое, что 0).
В процессе добавления генерируется хеш элемента с помощью трех хеш-функций. Эти функции возвращают индексы. Значение по каждому индексу обновляется на true.
В процессе поиска также генерируется хеш элемента. Затем проверяется, что все значения по индексам являются true. Если это так, то элемент может содержаться во множестве.
Однако мы не можем быть в этом уверены на 100%, поскольку биты могли быть установлены при добавлении других элементов.
Если хотя бы одно значение равняется false, элемент точно отсутствует во множестве.
Ложноположительные результаты
Вероятность ложноположительных срабатываний определяется тремя факторами: размером фильтра (m), количеством используемых хеш-функций (k) и количеством элементов, добавляемых в фильтр (n).
Формула выглядит следующим образом:
( 1 - e -kn/m ) k
Значения этих переменных выбираются, исходя из приемлемости ложноположительных результатов.
Применение
Фильтр Блума может использоваться в блогах. Он идеально подходит для определения статей, которые пользователь еще не читал, за счет добавления в фильтр статей, прочитанных им.
Некоторые статьи будут отфильтрованы по ошибке, но цена приемлема: пользователь не увидит нескольких статей, зато ему будут показываться новые статьи при каждом посещении сайта.
Подробнее о фильтре Блума можно почитать в этой статье.
Реализация
Приступаем к реализации фильтра Блума:
// data-structures/bloom-filter.js
export default class BloomFilter {
// Размер фильтра напрямую влияет на вероятность ложноположительных результатов.
// Как правило, чем больше размер, тем такая вероятность ниже
constructor(size = 100) {
// Размер фильтра
this.size = size
// Хранилище (по сути, сам фильтр)
this.storage = this.createStore(size)
}
}
Метод добавления элемента в фильтр:
// Добавляет элемент в фильтр
insert(item) {
// Вычисляем хеш элемента (индексы массива в количестве 3 штук)
const hashValues = this.getHashValues(item)
// Устанавливаем значение по каждому индексу в `true`
hashValues.forEach((v) => this.storage.setValue(v))
}
Метод определения наличия элемента в фильтре:
// Определяет наличие элемента в фильтре
mayContain(item) {
// Вычисляем хеш элемента
const hashValues = this.getHashValues(item)
// Перебираем индексы
for (const v of hashValues) {
// Если хотя бы одно значение равняется `false`
if (!this.storage.getValue(v)) {
// Элемент точно отсутствует
return false
}
}
// Элемент может присутствовать
return true
}
Метод создания хранилища (по сути, фильтра):
// Создает хранилище
createStore(size) {
// Хранилище - массив указанного размера, заполненный `false`
const storage = new Array(size).fill(false)
// Возвращается объект с "геттером" и "сеттером"
return {
getValue(i) {
return storage[i]
},
setValue(i) {
storage[i] = true
},
}
}
Хеш-функции (довольно примитивные, надо сказать):
// Хеш-функции
hash1(item) {
let hash = 0
for (let i = 0; i < item.length; i++) {
const char = item.charCodeAt(i)
hash = (hash << 5) + hash + char
hash &= hash // конвертируем значение в 32-битное целое число
hash = Math.abs(hash)
}
return hash % this.size
}
hash2(item) {
let hash = 5381
for (let i = 0; i < item.length; i++) {
const char = item.charCodeAt(i)
hash = (hash << 5) + hash + char // hash * 33 + char
}
return Math.abs(hash % this.size)
}
hash3(item) {
let hash = 0
for (let i = 0; i < item.length; i++) {
const char = item.charCodeAt(i)
hash = (hash << 5) - hash + char
hash &= hash // конвертируем значение в 32-битное целое число
}
return Math.abs(hash % this.size)
}
Наконец, метод генерации хеша:
// Генерирует хеш элемента.
// Возвращает массив из трех индексов
getHashValues(item) {
return [this.hash1(item), this.hash2(item), this.hash3(item)]
}
Полный код фильтра Блума
Тесты
Запускаем тесты:
npm run test ./data-structures/__tests__/bloom-filter
