RegExp
Регулярное выражение (далее также - регулярка) - это последовательность специальных символов, формирующих паттерн или шаблон (pattern), который сопоставляется со строкой.
Цель такого сопоставления может состоять либо в поиске подстроки в строке, например, для замены подстроки, либо в определении соответствия строки шаблону для валидации строки.
В данном туториале мы сосредоточимся на валидации.
Что конкретно мы будем делать? Мы возьмем несколько регулярок из validator.js (наиболее популярной библиотеки для валидации данных с помощью регулярных выражений) и произведем их подробный разбор. Также мы рассмотрим несколько дополнительных регулярок и один алгоритм.
Здесь можно получить общую информацию о регулярных выражениях, а здесь - более подробные сведения. Рекомендую ознакомиться с указанными материалами - так вам будет легче воспринимать дальнейшую информацию.
Еще парочка полезных ссылок:
- Интерактивный редактор (песочница) для создания и тестирования регулярных выражений. Одной из особенностей данной песочницы является автоматически генерируемое объяснение регулярных выражений, что бывает очень полезным
- Библиотека для создания сложных регулярок с помощью декларативного синтаксиса, например:
// Валидация `URL` с протоколом `http(s)`
const regexp = VerEx()
// начало строки
.startOfLine()
// затем `http`
.then('http')
// затем, возможно, `s`
.maybe('s')
// затем `://`
.then('://')
// затем, возможно, `www.`
.maybe('www.')
// затем любой символ, кроме пробела
.anythingBut(' ')
// конец строки
.endOfLine()
const isURL = (str) => regexp.test(str)
console.log(isURL('https://www.google.com')) // true
Для того, чтобы размять мозги, начнем с двух "валидаторов", в которых регулярные выражения не используются.
Является ли строка пустой?
Функция:
const isEmpty = (str) => str.trim().length === 0
console.log(isEmpty('not empty')) // false
console.log(isEmpty(' ')) // true
Метод trim() удаляет пробелы в начале и конце строки. Свойство length содержит количество символов, из которых состоит строка. Если строка не содержит символов, значит, ее свойство length имеет значение 0. В этом случае выражение str.length === 0 возвращает true. В противном случае, возвращается false.
Данную функцию можно переписать так:
const isEmpty = (str) => !str.trim().length
// `0` - ложное значение, `1` и больше - истинное значение,
// `!` - логическое НЕ, выполняет преобразование значения в логическое и меняет его на противоположное
// получается `!false`, или `true`
// или так
const _isEmpty = (str) => str.trim() === ''
Является ли значение "логическим"?
Функция:
const isBoolean = (str) => ['true', 'false', '1', '0'].indexOf(str) >= 0
console.log(isBoolean('true')) // true
console.log(isBoolean(false)) // false (см. ниже)
Метод indexOf() возвращает индекс элемента или -1 при отсутствии элемента в массиве. Если элемент в массиве есть, его индекс будет равным 0 или больше (в пределах длины массива - 1). В этом случае выражение arr.indexOf(str) >= 0 возвращает true. Иначе, возвращается false.
Обратите внимание: в данном случае логическими считаются не только значения true и false, но также 1 (обозначающее истину) и 0 (обозначающее ложь). Также обратите внимание, что функция принимает только строку (как и функции, которые будут рассматриваться в дальнейшем), поэтому второй вызов функции isBoolean() с логическим значением false возвращает false.
Данную функцию можно переписать так:
const bools = ['true', 'false', '1', '0']
const isBoolean = (str) => bools.indexOf(str) !== -1
// или так
const _isBoolean = (str) => bools.indexOf(str) > -1
Размялись? Отлично. Переходим к регуляркам.
Состоит ли строка только из букв?
Функция:
// для латиницы
const isAlpha = /^[A-Z]+$/i.test(str)
// для кириллицы
const _isAlpha = /^[А-ЯЁ]+$/i.test(str)
// для латиницы и криллицы
const __isAlpha = /^[A-ZА-ЯЁ]+$/i.test(str)
Посимвольный разбор:
^и$- символы начала и конца строки, соответственно (границы)[]- набор символов, перечисление (символ строки должен совпадать хотя бы с одним из вариантов)A-ZилиА-ЯЁ- диапазон букв (например,А-ЯЁ— это все буквы кириллицы отАдоЯ+ букваЁ, которая стоит особняком)
Обратите внимание: A-Z - это не то же самое, что символьный класс \w. \w означает любая буква латиницы ИЛИ любая цифра ИЛИ символ нижнего подчеркивания.
+- один или более предшествующий символ, т.е. символ, находящийся перед+(квантификатор)i- регистронезависимый поиск, т.е. поиск осуществляется без учета того, из больших или маленьких букв состоит строка (флаг)
Читаем регулярку: строка ДОЛЖНА состоять хотя бы из одной (одной или более) буквы, независимо от регистра.
Состоит ли строка только из букв и/или целых чисел?
Функция:
// для латиницы
const isAlphaNumeric = (str) => /^[0-9A-Z]+$/i.test(str)
// для кириллицы
const _isAlphaNumeric = (str) => /^[0-9А-ЯЁ]+$/i.test(str)
// для латиницы и кириллицы
const __isAlphaNumeric = (str) => /^[0-9A-ZА-ЯЁ]+$/i.test(str)
Разбор: такие же спецсимволы, что и в предыдущем примере +
0-9- диапазон цифр от0до9; данный диапазон можно заменить символьным классом\d, означающим любое число, для латиницы получится/^[\dA-Z]+$/i
Обратите внимание: здесь мы также не можем использовать \w из-за нижнего подчеркивания. Впрочем, мы можем исключить его из проверки, написав что-то вроде /^[^\W_]$/i, где [^] означает любой символ, кроме указанных в наборе (одним из таких символов является _), \W - НЕ буква латиницы, НЕ число и НЕ нижнее подчеркивание. Таким образом, [^\W_] означает любой символ, который НЕ является нижним подчеркиванием, а также не относится к буквам латиницы ИЛИ цифрам. Или в переводе на человеческий язык - любой символ, который является буквой латиницы или числом.
Читаем регулярку: строка ДОЛЖНА состоять хотя бы из одной буквы И/ИЛИ (арабского - в дальнейшем предполагается) числа, без учета регистра
Является ли значение почтовым индексом?
Функция:
const isPostalCode = (str) => /^\d{6}$/.test(str)
Разбор:
{6}- точно6вхождений предшествующего символа, т.е. символ перед{должен повторяться6раз, поскольку почтовый индекс (для России) состоит из6цифр (квантификатор)
Обратите внимание: в большинстве случаев при валидации предполагается, что строка прошла предварительную очистку от пробелов и других символов, которых в ней быть не должно (см. ниже).
Читаем: значение ДОЛЖНО состоять (точно - в дальнейшем предполагается) из 6 цифр.
Является ли значение номером паспорта?
Функция:
// оригинал из `validator.js`
const passportNumber = /^\d{2}\d{2}\d{6}$/
// можно упростить
const _passportNumber = /^\d{10}$/
const removeSpaces = (str) => str.replace(/\s+/g, '')
const isPassportNumber = (str) => _passportNumber.test(removeSpaces(str))
Разбор:
- в самом регулярном выражении нет ничего нового - 10 цифр (или 2 цифры + 2 цифры + 6 цифр - в оригинале)
removeSpaces()- утилита для удаления из строки пробелов, поскольку номер паспорта может выглядеть как12 34 567890,1234 567890и т.д.\sозначает пробельный символ: пробел, табуляция, перенос строки и т.д. (символьный класс)g- глобальный поиск, т.е. будут обнаружены все пробелы, имеющиеся в строке, а не только первый (флаг)
Читаем: значение ДОЛЖНО состоять из 10 цифр.
Является ли значение числом (целым или с плавающей точкой/запятой)?
Функция:
const numeric = (delimiter = '.') =>
new RegExp(`^[+-]?([0-9]*\\${delimiter})?[0-9]+$`)
const isNumeric = (str, delimiter) => numeric(delimiter).test(str)
Разбор:
numeric- функция, возвращающая регулярное выражение с указанным разделителем (delimiter), которым по умолчанию является символ.; это один из тех немногих случаев, когда для создания регулярки используется объектRegExp, позволяющий создавать регулярное выражение динамически, в отличие от//, создающего статический шаблон
Обратите внимание: символ . необходимо экранировать с помощью \ или, в данном случае, с помощью \\ (чтобы не экранировать $). Экранирование превращает . в обычную точку, в противном случае, этот символ будет иметь специальное значение - любой символ. Мы также экранируем любой другой символ, переданный в функцию isNumeric() в качестве разделителя (побочный эффект), но это не страшно.
-
?- НОЛЬ или ОДИН предшествующий символ (квантификатор); по сути, применение этого квантификатора делает предшествующий символ опциональным (необязательным) -
*- НОЛЬ или БОЛЕЕ предшествующих символов (квантификатор); этот квантификатор также делает предшествующий символ необязательным -
[+-]?- необязательный+или- -
([0-9]*\.)?- необязательная группа, которая МОЖЕТ состоять из числа и точки ИЛИ только из точки (или другого разделителя) -
[0-9]+- хотя бы одна цифра
Читаем: значение ДОЛЖНО состоять хотя бы из одной цифры и МОЖЕТ включать знак + или - в начале строки, за которым МОЖЕТ следовать любое количество цифр и разделитель ИЛИ только разделитель
Является ли строка цветом в шестнадцатеричном формате?
Функция:
const hexColor = /^#?([0-9A-F]{3}|[0-9A-F]{4}|[0-9A-F]{6}|[0-9A-F]{8})$/i
const isHexColor = (str) => hexColor.test(str)
Разбор:
- длина регулярки может испугать, но это всего лишь повторяющийся шаблон
#?- необязательный символ#[0-9A-F]{n}-nлюбых чисел ИЛИ букв латиницы отAдоF(без учета регистра)|- альтерация, ИЛИ (строка должна совпадать с одним из вариантов - наборов)
Читаем: строка ДОЛЖНА состоять ЛИБО из 3, ЛИБО из 4, ЛИБО из 6, ЛИБО из 8 букв латиницы от A до F (без учета регистра) И/ИЛИ цифр и МОЖЕТ включать символ # в начале
Является ли строка цветом в формате RGB или RGBA?
// RGB без альфа-канала - прозрачности
const rgbColorRegexp =
/^rgb\((([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5]),){2}([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\)$/
// RGBA с прозрачностью
const rgbaColorRegexp =
/^rgba\((([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5]),){3}(0?\.\d|1(\.0)?|0(\.0)?)\)$/
// RGB в процентах
const rgbColorPercentRegexp =
/^rgb\((([0-9]%|[1-9][0-9]%|100%),){2}([0-9]%|[1-9][0-9]%|100%)\)/
// RGBA в процентах
const rgbaColorPercentRegexp =
/^rgba\((([0-9]%|[1-9][0-9]%|100%),){3}(0?\.\d|1(\.0)?|0(\.0)?)\)/
// строка должна совпадать хотя бы с одним вариантом
const isRgbColor = (str) =>
rgbColorRegexp.test(str) ||
rgbaColorRegexp.test(str) ||
rgbColorPercentRegexp.test(str) ||
rgbaColorPercentRegexp.test(str)
Двигаемся дальше.
Является ли значение номером сотового телефона?
Функция (для России):
const mobilePhoneRegexp = /^(\+?7|8)?9\d{9}$/
const removeNonDigits = (str) => replace(/\D+/g, '')
const isMobilePhone = (str) => mobilePhoneRegexp.test(removeNonDigits(str))
Разбор:
\+?- опциональный символ+; обратите внимание на экранирование(\+?7|8)?- опциональная группа, которая МОЖЕТ состоять из символа+и числа7или8ИЛИ только из числа7или8removeNonDigits()- утилита для удаления всех символов, которые не являются числом (\D)
Читаем: строка ДОЛЖНА состоять из 10 цифр, первым из которых ДОЛЖНО БЫТЬ число 9, и МОЖЕТ включать символ + и число 7 или 8 ИЛИ только число 7 или 8 в начале
Лирическое отступление
Перед тем, как переходить к самой сложной части, поиграем с редко используемыми, но от того не менее интересными возможностями регулярных выражений.
// Определяем, является ли строка названием изображения в формате PNG, JPG, JPEG или SVG с помощью опережающей проверки
// Строка ДОЛЖНА состоять из одного и более (любого) символа, включать точку и заканчиваться на `png`, `jpg`, `jpeg` или `svg` (без учета регистра)
const isImage = (str) => /.+\.(?=png|jpe?g|gif|svg)/i.test(str)
// Определяем, что строка НЕ является названием изображения в формате WebP или AVIF с помощью негативной опережающей проверки
// ПОСЛЕ строки, состоящей из одного или более символа, НЕ ДОЛЖНО быть слова `webp` или `avif` (без учета регистра)
const isNotWebpOrAvif = (str) => /.+\.(?!webp|avif)/i.test(str)
// Что касается ретроспективной проверки, то я не смог придумать достойного примера - такого, который бы имел какие-то преимущества по сравнению с использованием метода `startsWith()`
// Определяем, что значение является долларами США с помощью ретроспективной проверки
// ПЕРЕД хотя бы одной цифрой ДОЛЖЕН быть символ `$`
const isUSD = (str) => /(?<=\$)\d+/.test(str)
// Определяем, что значение НЕ является евро с помощью негативной ретроспективной проверки
// ПЕРЕД хотя бы одной цифрой НЕ ДОЛЖНО быть символа `€`
const isNotEUR = (str) => /(?<!€)\d+/.test(str)
// Определяем, является ли строка эмодзи (или эмоджи)
// Флаг `u` и класс `\p{...}` - тема для отдельного разговора, however...
const isEmoji = (str) => /\p{So}/u.test(str)
// Универсальная функция для поиска символов на любом языке
const languageAgnostic = /[\p{Alpha}\p{M}\p{Nd}\p{Pc}\p{Join_C}]/u
const isLanguageAgnosticSymbol = (str) => languageAgnostic.test(str)
Еще парочка полезных утилит
// Определяем, является ли строка HTML-тегом
// [^>] - означает любой символ, кроме `>`
// ([^>]+) - один или более таких символов
const isHTMLTag = (str) => /(^<([^>]+)>$)/i.test(str)
const tag =
'<p id="myID" class="my-class" data-type="my_type" style="color: green;">'
console.log(isHTMLTag(tag)) // true
// Находим слова в одинарных или двойных (парных) кавычках
// обратите внимание: в данном случае мы не учитываем, что кавычки могут быть экранированы
const quotes = /(["'])([^"'])*\1/g
const getQuottedWords = (str) => str.match(quotes)
const str = `some string with "double quotes" and 'single quotes'`
console.log(getQuottedWords(str).join('\n'))
/*
"double quotes"
'single quotes'
*/
// или так (короче, но также без учета экранирования)
const _quotes = /(["']).*\1/g
// или так (с учетом экранирования)
const __quotes = /(["'])([^"'\\])*\1/g
const _getQuottedWords = (str) => str.match(__quotes)
const str = "some string with \"escaped double quotes\""
console.log(..._getQuottedWords(str)) // "escaped double quotes"
// Определяем, является ли строка временем в формате ЧЧ:ММ:СС
// Строка ДОЛЖНА начинаться с 1 с ведущим 0 или без него и любым числом (01-19) ИЛИ
// 2 и любым числом в диапазоне от 0 до 3 (20-23) - часы,
// затем ДОЛЖНЫ следовать две группы, состоящие из двоеточия и любого двухзначного числа,
// первая цифра которого ДОЛЖНА находиться в диапазоне от 0 до 5 (01-59) - часы и минуты
const isTime = (str) => /([01]\d|2[0-3])(:[0-5]\d){2}$/.test(str)
console.log(isTime('12:00')) // false
console.log(isTime('12:00:00')) // true
Функция для удаления из строки ВСЕХ пробелов
const str = ' some string with crazy spaces '
const formatted = str
.replace(/\s{2,}/g, ' ')
.trim()
.replace('crazy', 'normal')
console.log(formatted) // 'some string with normal spaces'
Функция для форматирования даты
// В таком формате возвращается дата из `<input type="date">`
const str = '2021-06-29'
// допустим, что мы хотим преобразовать ее в привычный для нас формат - `ДД.ММ.ГГГГ`
// С помощью обычных скобочных групп
// определяем скобочные группы 1, 2 и 3
const regexp = /(\d{4})-(\d{2})-(\d{2})/
// производим замену
const formatted = str.replace(regexp, '$3.$2.$1')
console.log(formatted) // 29.06.2021
// С помощью именованных групп захвата
// определяем группы `year`, `month` и `day`,
// чтобы не запоминать (считать) номера групп (количество скобок)
const _regexp = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/
// производим замену
const _formatted = str.replace(_regexp, '$<day>.$<month>.$<year>')
console.log(_formatted) // 29.06.2021
// С помощью функции-заменителя
// это не имеет особого смысла, просто для примера
const regexp = /(\d{4})-(\d{2})-(\d{2})/
const result = str.replace(
regexp,
// первый аргумент, который нам не нужен - это объект совпадения `match`
(_, year, month, day) => `${day}.${month}.${year}`
)
console.log(result) // 29.06.2021
Теперь поговорим о строках, к содержанию которых предъявляются особые требования. Под такими строками я подразумеваю URL (или, если угодно, URI) и email. В принципе, сюда же можно отнести пароли, требования к которым предъявляются не нормативными документами (RFC), а клиентами/заказчиками/разработчиками.
URL
URL (Uniform Resource Locator - унифицированный указатель ресурса) - система унифицированных адресов электронных ресурсов, или единообразный определитель местонахождения ресурса.
Он состоит из следующих частей:
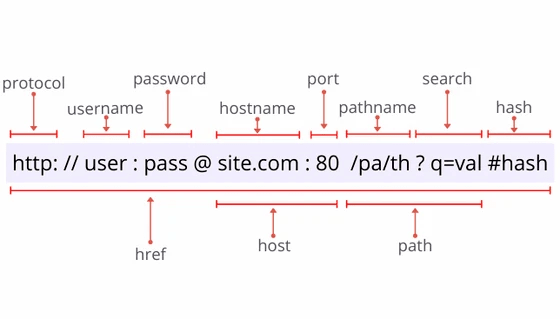
Требования, предъявляемые к "урлам", содержатся, в основном, в RFC 3986. Согласно этому документу URL может содержать следующие символы:
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-._~:/?#[]@!$&'()*+,;=
Однако, при этом не уточняется, в какой части URL какие символы могут использоваться.
Также в названном документе приводится регулярка для разбора урлов (приложение B), которая выглядит так (числа - это номера групп):
^(([^:/?#]+):)?(//([^/?#]*))?([^?#]*)(\?([^#]*))?(#(.*))?
12 3 4 5 6 7 8 9
Попробуем ее применить:
const url = /^(([^:\/?#]+):)?(\/\/([^\/?#]*))?([^?#]*)(\?([^#]*))?(#(.*))?/
const str = 'https://example.com/main?search#hash'
const result = str.match(url)
console.log(result)
/*
[
0: "https://example.com/main?search#hash"
1: "https:"
2: "https"
3: "//example.com"
4: "example.com"
5: "/main"
6: "?search"
7: "search"
8: "#hash"
9: "hash"
// ...
]
*/
Данная регулярка отлично подходит для простых URL (как в приведенном примере), но в более сложных случаях лучше использовать конструктор URL():
const str = 'https://user:pwd@example.com:80/main?query#anchor'
const result = new URL(str)
console.log(result)
/*
{
hash: "#anchor"
host: "example.com:80"
hostname: "example.com"
href: "https://user:pwd@example.com:80/main?query#anchor"
origin: "https://example.com:80"
password: "pwd"
pathname: "/main"
port: "80"
protocol: "https:"
search: "?query"
}
*/
Вот один из возможных вариантов регулярки для проверки URL с учетом протокола http(s), а также без учета некоторых символов:
/
https?:\/\/ - `http` с необязательным `s`
(www\.)? - опциональные `www` и `.`
[-\w@:%\.\+~#=]{1,256} - любые символы из набора в количестве 1-256
\. - точка
[a-z0-9()]{2,} - домен размером от 2 символов
\b - граница строки
([-\w()@:%\.\+~#=//?&]*) - поддомен, строка запроса, якорь и т.д.
/i
Тестируем:
const url =
/https?:\/\/(www\.)?[-\w@:%\.\+~#=]{1,256}\.[a-z0-9()]{1,6}\b([-\w()@:%\.\+~#=//?&]*)/i
const urls = [
'http://www.example.ru',
'https://www.example.ru',
'http://example.ru',
'http://www.example.ru/main',
'htt://example.ru',
'www.example.ru',
'www.mp3.com',
'www.e.org',
'http://e.org',
'http://www.e.org',
'https://www.e.org',
'www.ab.com',
'http://ab.com',
'http://www.ab.com',
'https://www.ab.com',
'www.example',
'www.example-.ru',
'www.-example.ru',
'example.ru',
'http://www.example',
'http://example',
'www.mp3#.com'
]
urls.forEach((u) => {
if (url.test(u)) {
console.log(`%cCorrect: ${u}`, 'color: green;')
} else {
console.info(`%cWrong: ${u}`, 'color: red;')
}
})
/*
Correct: http://www.example.ru
Correct: https://www.example.ru
Correct: http://example.ru
Correct: http://www.example.ru/main
Wrong: htt://example.ru
Wrong: www.example.ru
Wrong: www.mp3.com
Wrong: www.e.org
Correct: http://e.org
Correct: http://www.e.org
Correct: https://www.e.org
Wrong: www.ab.com
Correct: http://ab.com
Correct: http://www.ab.com
Correct: https://www.ab.com
Wrong: www.example
Wrong: www.example-.ru
Wrong: www.-example.ru
Wrong: example.ru
Wrong: http://www.example
Wrong: http://example
Wrong: www.mp3#.com
*/
Электронная почта - технология и служба по пересылке и получению электронных сообщений между пользователями компьютерной сети.
Адрес электронной почты (email) состоит из из следующих частей:
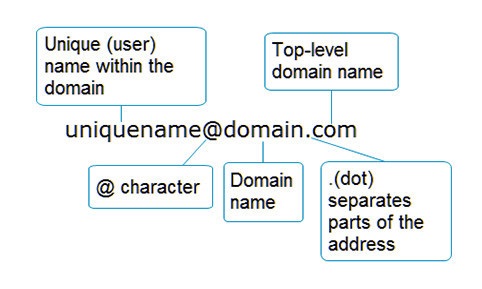
Что касается символов, которые могут использоваться в адресе электронной почты, то здесь ситуация довольно неоднозначная, поскольку существует большое количество RFC, по-разному регламентирующих этот вопрос. Относительно полный список этих RFC можно найти здесь.
В простейшем случае, регулярное выражение для определения того, является ли значение email, может выглядеть так:
// (хотя бы один (любой) символ)@(хотя бы один символ).(хотя бы один символ)
const isEmail = (str) => /^(.+)@(.+)\.(.+)$/.test(str)
Или можно обойтись вообще без регулярки:
// преобразуем строку в массив
const isEmail = ([...str]) =>
// проверяем, что в массиве есть символ `@`, он находится, как минимум, на второй позиции
str.indexOf('@') > 0 &&
// и является единственным
str.indexOf('@') === str.lastIndexOf('@') &&
// проверяем, что в массиве есть точка,
str.indexOf('.') > 0 &&
// она стоит после символа `@`
str.indexOf('@') < str.indexOf('.') &&
// и не является последним символом
str.indexOf('.') < str.length - 1
Однако, любой символ - это как any в TypeScript - обуславливает ненадежность регулярного выражения. Но, с повышением точности регулярки, ее сложность растет в геометрической прогрессии.
Вот гораздо более продвинутый (надежный) пример:
/^
(
(
[^<>()[\]\\.,;:\s@"]+ - один или более символ, кроме указанных
(\. - точка
[^<>()[\]\\.,;:\s@"]+ - один или более символ, кроме указанных
)
* - ноль или более
)
| - ИЛИ
(".+") - один или более символ в двойных кавычках
)
@ - символ `@`
(
(
\[ - открывающая квадратная скобка
[0-9]{1,3} - от 1 до 3 цифр
\. - точка
[0-9]{1,3}
\.
[0-9]{1,3}
\.
[0-9]{1,3}
\] - закрывающая квадратная скобка
)
| - ИЛИ
(
(
[-a-z0-9]+ - одна или более буква латиницы, цифра или символ `-`
\. - точка
)+ - один или более
[a-z]{2,} - хотя бы `2` буквы латиницы
)
)
$/i - без учета регистра
Функция:
const email =
/^(([^<>()[\]\\.,;:\s@"]+(\.[^<>()[\]\\.,;:\s@"]+)*)|(".+"))@((\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\])|(([a-z\-0-9]+\.)+[a-z]{2,}))$/i
const isEmail = (str) => email.test(str)
// тестируем
// вместо `@`, написали `_`
console.log(isEmail('my_mail.com')) // false
// пропустили `.`
console.log(isEmail('my@mailcom')) // false
// пропустили начало
console.log(isEmail('@mail.com')) // false
// ок
console.log(isEmail('my@mail.com')) // true
Пароль
К паролю могут предъявляться самые разные требования. Как правило, среди таких требований значится следующее:
- определенная длина или диапазон пароля, т.е. ограничение минимального ИЛИ минимального и максимального количества символов
- минимум одна большая буква
- минимум одна маленькая буква
- минимум одна цифра
- минимум один спецсимвол
Эти требования можно комбинировать. Переведем их на язык регулярных выражений:
{8,} // от 8 символов
{8,20} // от 8 до 20 символов
(?=.*\d) // минимум одна цифра
(?=.*[a-z]) // минимум одна буква в нижнем регистре
(?=.*[A-Z]) // минимум одна буква в верхнем регистре
(?=.*[-#!$@%^&*_+~=:;?\/]) // минимум один символ из набора
Функция:
const password =
/^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])(?=.*[-#!$@%^&*_+~=:;?\/])[-\w#!$@%^&*+~=:;?\/]{8,}$/
const isPassword = (str) => password.test(str)
// буквы в верхнем и нижнем регистре
console.log(isPassword('Password')) // false
// + число
console.log(isPassword('Passw0rd')) // false
// + спецсимвол, но недостаточная длина
console.log(isPassword('Pas_w0r')) // false
// ok
console.log(isPassword('Pas$_W0rd')) // true
Не забывайте модифицировать [-\w#!$@%^&*+~=:;?\/] при добавлении/удалении групп.
Номер карты
Напоследок, рассмотрим один интересный алгоритм - алгоритм Луна, который используется для вычисления контрольной цифры номера пластиковой карты в соответствии со стандартом ISO/IEC 7812 с целью ее (номера) валидации.
В упрощенном виде этот алгорит включает следующие шаги:
- Цифры проверяемой последовательности нумеруются справа налево.
- Цифры, оказавшиеся на нечетных местах, остаются без изменений.
- Цифры, стоящие на четных местах, умножаются на 2.
Обратите внимание: речь идет не о "четности" числа, а о четности его позиции в строке.
- Если в результате такого умножения возникает число больше 9, оно заменяется суммой цифр получившегося произведения — однозначным числом, то есть цифрой.
- Все полученные в результате преобразования цифры складываются. Если сумма кратна 10, то исходные данные верны.
Реализация алгоритма из Википедии:
function luhnAlgorithm(value) {
value = value.replace(/\D/g, '')
// контрольная сумма
let nCheck = 0
// индикатор "четности" позиции числа
let bEven = false
// перебираем числа в обратном порядке
for (let n = value.length - 1; n >= 0; n--) {
// извлекаем число из строки
// позиция первого извлеченного числа является нечетной
let nDigit = parseInt(value.charAt(n), 10)
// если позиция числа четная и при умножении на 2 число становится больше 9,
// вычитаем из числа 9
// результат будет таким же, как при сложении цифр, из которых состоит число
// например, `6 * 2 = 12`, `1 + 2 = 3` и `12 - 9 = 3`
if (bEven && (nDigit *= 2) > 9) {
nDigit -= 9
}
// прибавляем число к сумме
nCheck += nDigit
// инвертируем индикатор
bEven = !bEven
}
// если контрольная сумма делится на 10 без остатка,
// значит, номер карты является валидным
return nCheck % 10 == 0
}
validator.js предлагает такой вариант рассматриваемого алгоритма:
const creditCard =
/^(?:4[0-9]{12}(?:[0-9]{3,6})?|5[1-5][0-9]{14}|(222[1-9]|22[3-9][0-9]|2[3-6][0-9]{2}|27[01][0-9]|2720)[0-9]{12}|6(?:011|5[0-9][0-9])[0-9]{12,15}|3[47][0-9]{13}|3(?:0[0-5]|[68][0-9])[0-9]{11}|(?:2131|1800|35\d{3})\d{11}|6[27][0-9]{14})$/
function isCreditCard(str) {
const sanitized = str.replace(/[- ]+/g, '')
if (!creditCard.test(sanitized)) {
return false
}
let sum = 0
let digit
let tmpNum
let shouldDouble
for (let i = sanitized.length - 1; i >= 0; i--) {
digit = sanitized.substring(i, i + 1)
tmpNum = parseInt(digit, 10)
if (shouldDouble) {
tmpNum *= 2
if (tmpNum >= 10) {
sum += (tmpNum % 10) + 1
} else {
sum += tmpNum
}
} else {
sum += tmpNum
}
shouldDouble = !shouldDouble
}
return !!(sum % 10 === 0 ? sanitized : false)
}
Попробуем реализовать этот алгоритм в одну строку:
// функция принимает строку
const isCreditCard = (str) =>
// строка не должна быть пустой
// можно воспользоваться нашей функцией `!isEmpty()` или
str.trim().length !== 0 &&
str
// удаляем из строки все НЕ числа
.replace(/\D/g, '')
// преобразуем строку в массив
.split('')
// меняем порядок следования элементов массива на противоположный
.reverse()
// s - контрольная сумма
// c - текущий символ строки, начиная с последнего
// i - индекс элемента
.reduce(
(s, c, i) =>
(s +=
// если индекс элемента - нечетное число (1, 3 и т.д.),
// значит, число находится на четной позиции, умножаем его на 2
// если при этом число становится больше 9, вычитаем из него 9
// преобразуем результат в число с помощью `+`
+(i % 2 !== 0 && (c *= 2) > 9 ? (c -= 9) : c)),
0) // начальная контрольная сумма
// если контрольная сумма делится на 10 без остатка,
// значит, номер карты является валидным
% 10 === 0
console.log(isCreditCard('1234 5678 9009 8765')) // false
console.log(isCreditCard('5555 5555 5555 4444')) // true
Обратите внимание: регулярные выражения предоставляют широкий простор для творчества, поэтому приведенные в статье паттерны можно реализовать совершенно по-разному, главный вопрос в том, решает ли регулярное выражение поставленную перед ней задачу и насколько хорошо она это делает, т.е. насколько регулярка является надежной и как сильно ее использование влияет на производительность (часто это влияние оказывается критичным даже в случае с простыми шаблонами).
Подборка функций:
const isEmpty = (str) => !str.trim().length
const isBoolean = (str) => ['true', 'false', '1', '0'].indexOf(str) > -1
const isAlpha = /^[A-ZА-ЯЁ]+$/i.test(str)
const isAlphaNumeric = (str) => /^[0-9A-ZА-ЯЁ]+$/i.test(str)
const numeric = (delimiter = '.') =>
new RegExp(`^[+-]?([0-9]*\\${delimiter})?[0-9]+$`)
const isNumeric = (str, delimiter) => numeric(delimiter).test(str)
const isPostalCode = (str) => /^\d{6}$/.test(str)
const isPassportNumber = (str) => /^\d{10}$/.test(str)
const isMobilePhone = (str) => /^(\+?7|8)?9\d{9}$/.test(str)
const isURL = (str) => /https?:\/\/(www\.)?[-\w@:%\.\+~#=]{1,256}\.[a-z0-9()]{1,6}\b([-\w()@:%\.\+~#=//?&]*)/i.test(str)
const isEmail = (str) => /^(([^<>()[\]\\.,;:\s@"]+(\.[^<>()[\]\\.,;:\s@"]+)*)|(".+"))@((\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\])|(([a-z\-0-9]+\.)+[a-z]{2,}))$/i.test(str)
const isStrongPassword = (str) => /^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])(?=.*[-#!$@%^&*_+~=:;?\/])[-\w#!$@%^&*+~=:;?\/]{8,}$/.test(str)
const isCreditCard = (str) =>
str.trim().length !== 0 &&
str
.replace(/\D/g, '')
.split('')
.reverse()
.reduce((s, c, i) =>
(s += +(i % 2 !== 0 && (c *= 2) > 9 ? (c -= 9) : c)), 0) % 10 === 0