Rust
Hello world!
Данное руководство основано на Comprehensive Rust - руководстве по Rust от команды Android в Google и рассчитано на людей, которые уверенно владеют любым современным языком программирования. Еще раз: это руководство не рассчитано на тех, кто только начинает кодить 😉
Материалы для дальнейшего изучения Rust:
- Большая шпаргалка по Rust (на русском языке)
- Книга/учебник по Rust (на русском)
- rustlings
- Rust на примерах (на русском)
- Rust by practice
- Шикарный курс по Rust
Hello, World
Что такое Rust?
Rust - это новый язык программирования, релиз первой версии которого состоялся в 2015 году:
Rust- это статический компилируемый язык (какC++)rustc(компиляторRust) использует LLVM в качестве бэкэнда
Rustподдерживает множество платформ и архитектур- x86, ARM, WebAssembly...
- Linux, Mac, Windows...
Rustиспользуется для программирования широкого диапазона устройств- прошивки (firmware) и загрузчики (boot loaders)
- умные телевизоры
- мобильные телефоны
- настольные компьютеры
- серверы
Некоторые преимущества Rust:
- высокая гибкость
- высокий уровень контроля
- может использоваться для программирования очень низкоуровневых устройств, таких как микроконтроллеры
- не имеет среды выполнения или сборки мусора
- фокус на надежности и безопасности без ущерба для производительности
Hello, World
Рассмотрим простейшую программу на Rust:
fn main() {
println!("Привет 🌍!");
}
Вот что мы здесь видим:
- функции определяются с помощью
fn - блоки кода выделяются фигурными скобками
- функция
main()- это входная точка программы Rustимеет гигиенические макросы, такие какprintln!()- строки в
Rustкодируются в UTF-8 и могут содержать любой символ Юникода
Ремарки:
Rustочень похож на такие языки, какC/C++/Java. Он является императивным и не изобретает "велосипеды" без крайней необходимостиRustявляется современным: полностью поддерживает такие вещи, как Юникод (Unicode)Rustиспользует макросы (macros) для ситуаций, когда функция принимает разное количество параметров (не путать с перегрузкой функции (function overloading))- макросы являются "гигиеническими" - они не перехватывают случайно идентификаторы из области видимости, в которой используются. На самом деле, макросы
Rustтолько частично являются гигиеническими Rustявляется мультипарадигменным языком. Он имеет мощные возможности ООП и включает перечень функциональных концепций
Преимущества Rust
Некоторые уникальные особенности Rust:
- безопасность памяти во время компиляции - весь класс проблем с памятью предотвращается во время компиляции
- неинициализированные переменные
- двойное освобождение (double-frees)
- использование после освобождения (use-after-free)
- нулевые указатели (
NULLpointers) - забытые заблокированные мьютексы (mutexes)
- гонки данных между потоками (threads)
- инвалидация итератора
- отсутствие неопределенного поведения во время выполнения - то, что делает инструкция
Rust, никогда не остается неопределенным- проверяются границы доступа (index boundaries) к массиву
- переполнение (overflowing) целых чисел приводит к панике или оборачиванию (wrapping)
- современные возможности - столь же выразительные и эргономичные, как в высокоуровневых языках
- перечисления и сопоставление с образцом (matching)
- дженерики (generics)
- интерфейс внешних функций (foreign function interface, FFI) без накладных расходов
- бесплатные абстракции
- отличные ошибки компилятора
- встроенное управление зависимостями
- встроенная поддержка тестирования
- превосходная поддержка протокола языкового сервера (Language Server Protocol)
Песочница
Песочница Rust предоставляет легкий способ быстро запускать короткие программы Rust.
Типы и значения
Переменные
Безопасность типов в Rust обеспечивается за счет статической типизации. Привязки переменных (variable bindings) выполняются с помощью let:
fn main() {
let x: i32 = 10;
println!("x: {x}");
// x = 20;
// println!("x: {x}");
}
- Раскомментируйте
x = 20, чтобы увидеть, что переменные по умолчанию являются иммутабельными (неизменными/неизменяемыми). Добавьте ключевое словоmutпослеlet, чтобы сделать переменную мутабельной i32- это тип переменной. Тип переменной должен быть известен во время компиляции, но выведение типов (рассматриваемое позже) позволяет разработчикам опускать типы во многих случаях
Значения
Вот некоторые базовые встроенные типы и синтаксис литеральных значений каждого типа:
| Типы | Литералы | |
|---|---|---|
| Целые числа со знаком | i8, i16, i32, i64, i128, isize | -10, 0, 1_000, 123_i64 |
| Целые числа без знака | u8, u16, u32, u64, u128, usize | 0, 123, 10_u16 |
| Числа с плавающей точкой | f32, f64 | 3.14, -10.0e20, 2_f32 |
| Скалярные значения Юникода | char | 'a', 'α', '∞' |
| Логические значения | bool | true,false |
Типы имеют следующие размеры:
-
iN,uNиfN-Nбит -
isizeиusize- размер указателя -
char- 32 бита -
bool- 8 бит -
Нижние подчеркивания предназначены для улучшения читаемости, поэтому их можно не писать, т.е.
1_000можно записать как1000(или10_00), а123_i64можно записать как123i64
Арифметика
fn interproduct(a: i32, b: i32, c: i32) -> i32 {
return a * b + b * c + c * a;
}
fn main() {
println!("результат: {}", interproduct(120, 100, 248));
}
В арифметике Rust нет ничего особенного по сравнению с другими языками программирования, за исключением определения поведения при переполнении целых чисел: при сборке для разработки программа запаникует, а при релизной сборке переполнение будет обернуто (wrapped). Кроме переполнения, существует также насыщение (saturating) и каррирование (carrying), которые обеспечиваются соответствующими методами, например, (a * b).saturating_add(b * c).saturating_add(c * a).
Строки
В Rust существует 2 типа для представления строк, оба будут подробно рассмотрены позже. Оба типа всегда хранят закодированные в UTF-8 строки.
String- модифицируемая, собственная (owned) строка&str- строка, доступная только для чтения. Строковые литералы имеют этот тип
fn main() {
let greeting: &str = "Привет";
let planet: &str = "🪐";
let mut sentence = String::new();
sentence.push_str(greeting);
sentence.push_str(", ");
sentence.push_str(planet);
println!("итоговое предложение: {}", sentence);
println!("{:?}", &sentence[0..5]);
//println!("{:?}", &sentence[12..13]);
}
Ремарки:
- поведение при наличии в строке невалидных символов
UTF-8вRustявляется неопределенным, поэтому использование таких символов может привести к панике String- это пользовательский тип с конструктором (::new()) и методами вродеpush_str()&в&strявляется индикатором того, что это ссылка. Мы поговорим о ссылках позже, пока думайте о&strкак о строках, доступных только для чтения- закомментированная строка представляет собой индексирование строки по позициям байт.
12..13не попадают в границы (boundaries) символа, поэтому программа паникует. Измените диапазон на основе сообщения об ошибке - сырые (raw) строки позволяют создавать
&strс автоматическим экранированием специальных символов:r"\n" == "\\n". Двойные кавычки можно вставить, обернув строку в одинаковое количество#с обеих сторон:
fn main() {
// Сырая строка
println!(r#"<a href="link.html">ссылка</a>"#); // "<a href="link.html">ссылка</a>"
// Экранирование
println!("<a href=\"link.html\">ссылка</a>"); // <a href="link.html">ссылка</a>
}
Выведение типов
Для определения/выведения типа переменной Rust "смотрит" на то, как она используется:
fn takes_u32(x: u32) {
println!("u32: {x}");
}
fn takes_i8(y: i8) {
println!("i8: {y}");
}
fn main() {
let x = 10;
let y = 20;
takes_u32(x);
takes_i8(y);
// takes_u32(y);
}
Дефолтным целочисленным типом является i32 ({integer} в сообщениях об ошибках), а дефолтным "плавающим" типом - f64 ({float} в сообщениях об ошибках).
fn main() {
let x = 3.14;
let y = 20;
assert_eq!(x, y);
// ERROR: no implementation for `{float} == {integer}`
// Целые числа и числа с плавающей точкой по умолчанию сравнивать между собой нельзя
}
Упражнение: Фибоначчи
Первое и второе числа Фибоначчи - 1. Для n > 2 nth (итое) число Фибоначчи вычисляется рекурсивно как сумма n - 1 и n - 2 чисел Фибоначчи.
Напишите функцию fib(n), которая вычисляет nth-число Фибоначчи.
fn fib(n: u32) -> u32 {
if n <= 2 {
// Базовый случай
todo!("реализуй меня")
} else {
// Рекурсия
todo!("реализуй меня")
}
}
fn main() {
let n = 20;
println!("fib(n) = {}", fib(n));
// Макрос для проверки двух выражений на равенство.
// Неравенство вызывает панику
assert_eq!(fib(n), 6765);
}
Решение:
Поток управления
Условия
Большая часть синтаксиса потока управления Rust похожа на C, C++ или Java:
- блоки разделяются фигурными скобками
- строчные комментарии начинаются с
//, блочные - разделяются/* ... */ - ключевые слова
ifиwhileработают, как ожидается - значения переменным присваиваются с помощью
=, сравнения выполняются с помощью==
Выражения if
Выражения if используются в точности, как в других языках:
fn main() {
let x = 10;
if x < 20 {
println!("маленькое");
} else if x < 100 {
println!("больше");
} else {
println!("огромное");
}
}
Кроме того, if можно использовать как выражение, возвращающее значение. Последнее выражение каждого блока становится значением выражения if:
fn main() {
let x = 10;
let size = if x < 20 { "маленькое" } else { "большое" };
println!("размер числа: {}", size);
}
Поскольку if является выражением и должно иметь определенный тип, значения обоих блоков должны быть одного типа. Попробуйте добавить ; после маленькое во втором примере.
При использовании if в качестве выражения, оно должно заканчиваться ; для его отделения от следующей инструкции. Попробуйте удалить ; перед println!().
Циклы
Rust предоставляет 3 ключевых слова для создания циклов: while, loop и for.
while
Ключевое слово while работает, как в других языках - тело цикла выполняется, пока условие является истинным:
fn main() {
let mut x = 200;
while x >= 10 {
x = x / 2;
}
println!("итоговое значение x: {x}");
}
for
Цикл for перебирает диапазон значений:
fn main() {
for x in 1..5 {
println!("x: {x}");
}
}
loop
Цикл loop продолжается до прерывания с помощью break:
fn main() {
let mut i = 0;
loop {
i += 1;
println!("{i}");
if i > 100 {
break;
}
}
}
- Мы подробно обсудим итераторы позже
- обратите внимание, что цикл
forитерируется до 4. Для "включающего" диапазона используется синтаксис1..=5
break и continue
Ключевое слово break используется для раннего выхода (early exit) из цикла. Для loop break может принимать опциональное выражение, которое становится значением выражения loop.
Для незамедлительного перехода к следующей итерации используется ключевое слово continue.
fn main() {
let (mut a, mut b) = (100, 52);
let result = loop {
if a == b {
break a;
}
if a < b {
b -= a;
} else {
a -= b;
}
};
println!("{result}");
}
continue и break могут помечаться метками (labels):
fn main() {
'outer: for x in 1..5 {
println!("x: {x}");
let mut i = 0;
while i < x {
println!("x: {x}, i: {i}");
i += 1;
if i == 3 {
break 'outer;
}
}
}
}
В примере мы прерываем внешний цикл после 3 итераций внутреннего цикла.
Обратите внимание, что только loop может возвращать значения. Это связано с тем, что цикл loop гарантировано выполняется хотя бы раз (в отличие от циклов while и for).
Блоки и области видимости
Блоки
Блок в Rust содержит последовательность выражений. У каждого блока есть значение и тип, соответствующие последнему выражению блока:
fn main() {
let z = 13;
let x = {
let y = 10;
println!("y: {y}");
z - y
};
println!("x: {x}");
}
Если последнее выражение заканчивается ;, результирующим значением и типом является () (пустой тип/кортеж - unit type).
Области видимости и затенение
Областью видимости (scope) переменной является ближайший к ней блок.
Переменные можно затенять/переопределять (shadow), как внешние, так и из той же области видимости:
fn main() {
let a = 10;
println!("перед: {a}");
{
let a = "привет";
println!("внутренняя область видимости: {a}");
let a = true;
println!("затенение во внутренней области видимости: {a}");
}
println!("после: {a}");
}
- Для того, чтобы убедиться в том, что область видимости переменной ограничена фигурными скобками, добавьте переменную
bво внутреннюю область видимости и попробуйте получить к ней доступ во внешней области видимости - затенение отличается от мутации, поскольку после затенения обе локации памяти переменной существуют в одно время. Обе доступны под одним названием в зависимости от использования в коде
- затеняемая переменная может иметь другой тип
- поначалу затенение выглядит неясным, но оно удобно для сохранения значений после
unwrap()(распаковки)
Функции
fn gcd(a: u32, b: u32) -> u32 {
if b > 0 {
gcd(b, a % b)
} else {
a
}
}
fn main() {
println!("наибольший общий делитель: {}", gcd(143, 52));
}
- Типы определяются как для параметров, так и для возвращаемого значения
- последнее выражение в теле функции становится возвращаемым значением (после него не должно быть
;). Для раннего возврата может использоваться ключевое словоreturn - дефолтным типом, возвращаемым функцией, является
()(это справедливо также для функций, которые ничего не возвращают явно) - перегрузка функций в
Rustне поддерживается- число параметров всегда является фиксированным. Параметры по умолчанию не поддерживаются. Для создания функций с переменным количеством параметров используются макросы (macros)
- параметры имеют типы. Эти типы могут быть общими (дженериками - generics). Мы обсудим это позже
Макросы
Макросы раскрываются (expanded) в коде в процессе компиляции и могут принимать переменное количество параметров. Они обозначаются с помощью ! в конце. Стандартная библиотека Rust включает несколько полезных макросов:
println!(format, ..)- печатает строку в стандартный вывод, применяя форматирование, описанное в std::fmtformat!(format, ..)- работает какprintln!(), но возвращает строкуdbg!(expression)- выводит значение выражения в терминал и возвращает егоtodo!()- помечает код как еще не реализованный. Выполнение этого кода приводит к панике программыunreachable!()- помечает код как недостижимый. Выполнение этого кода приводит к панике программы
fn factorial(n: u32) -> u32 {
let mut product = 1;
for i in 1..=n {
product *= dbg!(i);
}
product
}
fn fizzbuzz(n: u32) -> u32 {
todo!("реализуй меня")
}
fn main() {
let n = 13;
println!("{n}! = {}", factorial(4));
}
Упражнение: гипотеза Коллатца
Для объяснения сути гипотезы Коллатца рассмотрим следующую последовательность чисел, называемую сиракузской последовательностью. Берем любое натуральное число n. Если оно четное, то делим его на 2, а если нечетное, то умножаем на 3 и прибавляем 1 (получаем 3n + 1). Над полученным числом выполняем те же самые действия, и так далее. Последовательность прерывается на ni, если ni равняется 1.
Например, для числа 3 получаем:
- 3 - нечетное, 3*3 + 1 = 10
- 10 - четное, 10:2 = 5
- 5 - нечетное, 5*3 + 1 = 16
- 16 - четное, 16/2 = 8
- 8 - четное, 8/2 = 4
- 4 - четное, 4/2 = 2
- 2 - четное, 2/2 = 1
- 1 - нечетное (последовательность прерывается,
nравняется 8)
Напишите функцию для вычисления сиракузской последовательности для указанного числа n.
fn collatz_length(mut n: i32) -> u32 {
todo!("реализуй меня")
}
fn main() {
println!("длина последовательности: {}", collatz_length(11));
assert_eq!(collatz_length(11), 15);
}
Решение:
Кортежи и массивы
Кортежи и массивы
Кортежи (tuples) и массивы (arrays) - первые "составные" (compound) типы, которые мы изучим. Все элементы массива должны быть одного типа, элементы кортежа могут быть разных типов. И массивы, и кортежи имеют фиксированный размер.
| Типы | Литералы | |
|---|---|---|
| Массивы | [T; N] | [20, 30, 40], [0; 3] |
| Кортежи | (), (T,), (T1, T2) | (), ('x',), ('x', 1.2) |
Определение массива и доступ к его элементам:
fn main() {
let mut a: [i8; 10] = [42; 10];
a[5] = 0;
println!("a: {a:?}");
}
Определение кортежа и доступ к его элементам:
fn main() {
let t: (i8, bool) = (7, true);
println!("t.0: {}", t.0);
println!("t.1: {}", t.1);
}
Массивы:
- значением массива типа
[T; N]являетсяN(константа времени компиляции) элементов типаT. Обратите внимание, что длина массива является частью его типа, поэтому[u8; 3]и[u8; 4]считаются двумя разными типами. Срезы (slices), длина которых определяется во время выполнения, мы рассмотрим позже - попробуйте получить доступ к элементу за пределами границ массива. Доступ к элементам массива проверяется во время выполнения.
Rustобычно выполняет различные оптимизации такой проверки, а в небезопасномRustее можно отключить - для присвоения значения массиву можно использовать литералы
- поскольку массивы имеют реализацию только отладочного вывода, они форматируются с помощью
{:?}или{:#?}
Кортежи:
- как и массивы, кортежи имеют фиксированный размер
- кортежи группируют значения разных типов в один составной тип
- доступ к полям кортежа можно получить с помощью точки и индекса, например,
t.0,t.1 - пустой кортеж
()также называется "единичным/пустым типом" (unit type). Это и тип, и его единственное валидное значение. Пустой тип является индикатором того, что функция или выражение ничего не возвращают (в этом смысле пустой тип похож наvoidв других языках)
Перебор массива
Для перебора массива (но не кортежа) может использоваться цикл for:
fn main() {
let primes = [2, 3, 5, 7, 11, 13, 17, 19];
for prime in primes {
for i in 2..prime {
assert_ne!(prime % i, 0);
}
}
}
Возможность перебора массива в цикле for обеспечивается трейтом IntoIterator, о котором мы поговорим позже.
В примере мы видим новый макрос assert_ne!. Существуют также макросы assert_eq! и assert!. Эти макросы проверяются всегда, в отличие от их аналогов для отладки debug_assert! и др., которые удаляются из производственной сборки.
Сопоставление с образцом
Ключевое слово match позволяет сопоставлять значение с одним или более паттернами/шаблонами. Сравнение выполняется сверху вниз, побеждает первое совпадение.
match похож на switch из других языков:
#[rustfmt::skip]
fn main() {
let input = 'x';
match input {
'q' => println!("выход"),
'a' | 's' | 'w' | 'd' => println!("движение"),
'0'..='9' => println!("число"),
key if key.is_lowercase() => println!("буква в нижнем регистре: {key}"),
_ => println!("другое"),
}
}
Паттерн _ - это шаблон подстановочного знака (wildcard pattern), который соответствует любому значению. Сопоставления должны быть исчерпывающими, т.е. охватывать все возможные случаи, поэтому _ часто используется как финальный перехватчик.
Сопоставление может использоваться как выражение. Как и в случае с if, блоки match должны иметь одинаковый тип. Типом является последнее выражение в блоке, если таковое имеется. В примере типом является ().
Переменная в паттерне (key в примере) создает привязку, которая может использоваться в блоке.
Защитник сопоставления (match guard - if ...) допускает совпадение только при удовлетворении условия.
Ремарки:
- вы могли заметить некоторые специальные символы, которые используются в шаблонах:
|- этоor(или)..- распаковка значения1..=5- включающий диапазон_- подстановочный знак
- защита сопоставления важна и необходима, когда мы хотим кратко выразить более сложные идеи, чем позволяют одни только шаблоны
- защита сопоставление и использование
ifвнутри блокаmatch- разные вещи - условие, определенное в защитнике сопоставления, применяется ко всем выражениям паттерна, определенного с помощью
|
Деструктуризация
Деструктуризация - это способ извлечения данных из структуры данных с помощью шаблона, совпадающего со структурой данных. Это способ привязки к субкомпонентам (subcomponents) структуры данных.
Кортежи
fn main() {
describe_point((1, 0));
}
fn describe_point(point: (i32, i32)) {
match point {
(0, _) => println!("на оси Y"),
(_, 0) => println!("на оси X"),
(x, _) if x < 0 => println!("слева от оси Y"),
(_, y) if y < 0 => println!("ниже оси X"),
_ => println!("первый квадрант"),
}
}
Массивы
#[rustfmt::skip]
fn main() {
let triple = [0, -2, 3];
println!("расскажи мне о {triple:?}");
match triple {
[0, y, z] => println!("первый элемент - это 0, y = {y} и z = {z}"),
[1, ..] => println!("первый элемент - это 1, остальные элементы игнорируются"),
_ => println!("все элементы игнорируются"),
}
}
- Создайте новый шаблон массива, используя
_для представления элемента - добавьте в массив больше значений
- обратите внимание, как
..расширяется (expand) до разного количества элементов - покажите сопоставление с хвостом (tail) с помощью шаблонов
[.., b]и[a@.., b]
Упражнение: вложенные массивы
Массивы могут содержать другие массивы:
let matrix3x3 = [[1, 2, 3], [4, 5, 6], [7, 8, 9]];
Каков тип этой переменной?
Напишите функцию transpose(), которая транспонирует матрицу 3х3 (превращает строки в колонки).
fn transpose(matrix: [[i32; 3]; 3]) -> [[i32; 3]; 3] {
todo!("реализуй меня")
}
fn main() {
let matrix = [
[101, 102, 103], // <-- комментарий не дает `rustfmt` форматировать `matrix` в одну строку
[201, 202, 203],
[301, 302, 303],
];
let transposed = transpose(matrix);
println!("транспонированная матрица: {:#?}", transposed);
assert_eq!(
transposed,
[
[101, 201, 301], //
[102, 202, 302],
[103, 203, 303],
]
);
}
Решение:
Ссылки
Общие ссылки
Ссылка (reference) - это способ получить доступ к значению без принятия его во владение, т.е. без заимствования (borrowing) этого значения. Общие/распределенные (shared) ссылки доступны только для чтения: ссылочные данные не могут модифицироваться.
fn main() {
let a = 'A';
let b = 'B';
let mut r: &char = &a;
println!("r: {}", *r);
r = &b;
println!("r: {}", *r);
}
Общая ссылка на тип T имеет тип &T. Оператор & указывает на то, что это ссылка. Оператор * используется для разыменования (dereferencing) ссылки - получения ссылочного значения.
Rust запрещает висящие ссылки (dangling references):
fn x_axis(x: i32) -> &(i32, i32) {
let point = (x, 0);
return &point;
}
Ремарки:
- ссылка "заимствует" значение, на которое она ссылается. Код может использовать ссылку для доступа к значению, но его "владельцем" (owner) будет оригинальная переменная. Мы подробно поговорим о владении в 3 части
- ссылки реализованы как указатели (pointers) в
CилиC++, ключевым преимуществом которых является то, что они могут быть намного меньше, чем вещи, на которые они указывают. Позже мы будем говорить о том, какRustобеспечивает безопасную работу с памятью, предотвращая баги, связанные с сырыми (raw) указателями Rustне создает ссылки автоматически- в некоторых случаях
Rustвыполняет разыменование автоматически, например, при вызове методов (r.count_ones()) - в первом примере переменная
rявляется мутабельной, поэтому ее значение можно менять (r = &b). Это повторно привязываетr, теперь она указывает на что-то другое. Это отличается отC++, где присвоение значения ссылке меняет ссылочное значение - общая ссылка не позволяет модифицировать значение, на которое она ссылается, даже если это значение является мутабельным (попробуйте
*r = 'X') Rustотслеживает времена жизни (lifetimes) всех ссылок, чтобы убедиться, что они живут достаточно долго. В безопасномRustне может быть висящих ссылок (dangling pointers).x_axis()возвращает ссылку наpoint, ноpointуничтожается (выделенная память освобождается - deallocate) после выполнения кода функции, и код не компилируется
Эксклюзивные ссылки
Эксклюзивные ссылки (exclusive references), также известные как мутабельные ссылки (mutable references), позволяют менять значение, на которое они ссылаются. Они имеют тип &mut T:
fn main() {
let mut point = (1, 2);
let x_coord = &mut point.0;
*x_coord = 20;
println!("point: {point:?}");
}
Ремарки:
- "эксклюзивный" означает, что только эта ссылка может использоваться для доступа к значению. Других ссылок (общих или эксклюзивных) существовать не должно. Ссылочное значение недоступно, пока существует эксклюзивная ссылка. Попробуйте получить доступ к
&point.0или изменитьpoint.0, пока живаx_coord - убедитесь в том, что понимаете разницу между
let mut x_coord: &i32иlet x_coord: &mut i32. Первая переменная - это общая ссылка, которая может быть привязана к разным значениям, вторая - эксклюзивная ссылка на мутабельную переменную
Упражнение: геометрия
Ваша задача - создать несколько вспомогательных функций для трехмерной геометрии, представляющей точку как [f64; 3].
// Функция для вычисления магнитуды вектора: суммируем квадраты координат вектора
// и извлекаем из этой суммы квадратный корень.
// Метод для извлечения квадратного корня - `sqrt()` (`v.sqrt()`)
fn magnitude(...) -> f64 {
todo!("реализуй меня")
}
// Функция нормализации вектора: вычисляем магнитуду вектора
// и делим на нее все координаты вектора
fn normalize(...) {
todo!("реализуй меня")
}
fn main() {
println!("магнитуда единичного вектора: {}", magnitude(&[0.0, 1.0, 0.0]));
let mut v = [1.0, 2.0, 9.0];
println!("магнитуда {v:?}: {}", magnitude(&v));
normalize(&mut v);
println!("магнитуда {v:?} после нормализации: {}", magnitude(&v));
}
Решение:
Пользовательские типы
Именованные структуры
Rust поддерживает кастомные структуры:
struct Person {
name: String,
age: u8,
}
fn describe(person: &Person) {
println!("{} is {} years old", person.name, person.age);
}
fn main() {
let mut peter = Person { name: String::from("Peter"), age: 27 };
describe(&peter);
peter.age = 28;
describe(&peter);
let name = String::from("Avery");
let age = 39;
let avery = Person { name, age };
describe(&avery);
let jackie = Person { name: String::from("Jackie"), ..avery };
describe(&jackie);
}
Ремарки:
- тип структуры отдельно определять не нужно
- структуры не могут наследовать друг другу
- для реализации трейта на типе, в котором не нужно хранить никаких значений, можно использовать структуру нулевого размера (zero-sized), например,
struct Foo; - если название переменной совпадает с названием поля, то, например,
name: nameможно сократить доname - синтаксис
..averyпозволяет копировать большую часть полей старой структуры в новую структуру. Он должен быть последним элементом
Кортежные структуры
Если названия полей неважны, можно использовать кортежную структуру:
struct Point(i32, i32);
fn main() {
let p = Point(17, 23);
println!("({}, {})", p.0, p.1);
}
Это часто используется для оберток единичных полей (single-field wrappers), которые называются newtypes (новыми типами):
struct PoundsOfForce(f64);
struct Newtons(f64);
fn compute_thruster_force() -> PoundsOfForce {
todo!("Ask a rocket scientist at NASA")
}
fn set_thruster_force(force: Newtons) {
// ...
}
fn main() {
let force = compute_thruster_force();
set_thruster_force(force);
}
Ремарки:
newtype- отличный способ закодировать дополнительную информацию о значении в примитивном типе, например:- число измеряется в определенных единицах (
Newtons) - при создании значение проходит определенную валидацию, которую не нужно каждый раз выполнять вручную:
PhoneNumber(String)илиOddNumber(u32)
- число измеряется в определенных единицах (
- пример является тонкой отсылкой к провалу Mars Climate Orbiter
Перечисления
Ключевое слово enum позволяет создать тип, который имеет несколько вариантов:
#[derive(Debug)]
enum Direction {
Left,
Right,
}
#[derive(Debug)]
enum PlayerMove {
Pass, // простой вариант
Run(Direction), // кортежный вариант
Teleport { x: u32, y: u32 }, // структурный вариант
}
fn main() {
let m: PlayerMove = PlayerMove::Run(Direction::Left);
println!("On this turn: {:?}", m);
}
Ремарки:
- перечисление позволяет собрать набор значений в один тип
Direction- это тип с двумя вариантами:Direction::LeftиDirection::RightPlayerMove- это тип с тремя вариантами. В дополнение к полезным нагрузкам (payloads)Rustбудет хранить дискриминант, чтобы во время выполнения знать, какой вариант находится в значенииPlayerMoveRustиспользует минимальное пространство для хранения дискриминанта- при необходимости сохраняется целое число наименьшего требуемого размера
- если разрешенные значения варианта не охватывают все битовые комбинации, для кодирования дискриминанта будут использоваться недопустимые битовые комбинации ("нишевые оптимизации" (niche optimization)). Например,
Option<&u8>хранит либо указатель на целое число, либоNULLдля вариантаNone - при необходимости дискриминантом можно управлять (например, для обеспечения совместимости с
C):
#[repr(u32)]
enum Bar {
A, // 0
B = 10000,
C, // 10001
}
fn main() {
println!("A: {}", Bar::A as u32);
println!("B: {}", Bar::B as u32);
println!("C: {}", Bar::C as u32);
}
Без repr тип дискриминанта занимает 2 байта, поскольку 10001 соответствует двум байтам.
Статики и константы
Статичные (static) и константные (constant) переменные - это 2 способа создания значений с глобальной областью видимости, которые не могут быть перемещены или перераспределены при выполнении программы.
const
Константные значения оцениваются во время компиляции и их значения встраиваются при использовании (inlined upon use):
const DIGEST_SIZE: usize = 3;
const ZERO: Option<u8> = Some(42);
fn compute_digest(text: &str) -> [u8; DIGEST_SIZE] {
let mut digest = [ZERO.unwrap_or(0); DIGEST_SIZE];
for (idx, &b) in text.as_bytes().iter().enumerate() {
digest[idx % DIGEST_SIZE] = digest[idx % DIGEST_SIZE].wrapping_add(b);
}
digest
}
fn main() {
let digest = compute_digest("hello");
println!("digest: {digest:?}");
}
Только функции, помеченные с помощью const, могут вызываться во время компиляции для генерации значений const. Но такие функции могут вызываться и во время выполнения.
static
Статичные переменные живут на протяжении всего жизненного цикла программы и не могут перемещаться:
static BANNER: &str = "welcome";
fn main() {
println!("{BANNER}");
}
Значения статичных переменных не встраиваются при использовании и имеют фиксированные локации в памяти. Это может быть полезным для небезопасного и встроенного кода (FFI), но для создания глобальных переменных рекомендуется использовать const.
Ремарки:
staticобеспечивает идентичность объекта (object identity): адрес в памяти и состояние, как того требуют типы с внутренней изменчивостью, такие какMutex<T>- константы, которые оцениваются во время выполнения, требуются нечасто, но иногда они могут оказаться полезными, и их использование безопаснее, чем использование статик
Синонимы типов
Синоним типа (type alias) создает название для другого типа. Два типа могут использоваться взаимозаменяемо:
enum CarryableConcreteItem {
Left,
Right,
}
type Item = CarryableConcreteItem;
// Синонимы особенно полезны для длинных, сложных типов
use std::cell::RefCell;
use std::sync::{Arc, RwLock};
type PlayerInventory = RwLock<Vec<Arc<RefCell<Item>>>>;
Упражнение: события в лифте
Ваша задача состоит в том, чтобы создать структуру данных для представления событий в системе управления лифтом. Вам необходимо определить типы и функции для создания различных событий. Используйте #[derive(Debug)], чтобы разрешить форматирование типов с помощью {:?}.
Это упражнение требует только создания и заполнения структур данных, чтобы функция main() работала без ошибок.
#[derive(Debug)]
/// Событие, на которое должен реагировать контроллер
enum Event {
todo!("Добавить необходимые варианты")
}
/// Направление движения
#[derive(Debug)]
enum Direction {
Up,
Down,
}
/// Лифт прибыл на определенный этаж
fn car_arrived(floor: i32) -> Event {
todo!("реализуй меня")
}
/// Двери лифта открылись
fn car_door_opened() -> Event {
todo!("реализуй меня")
}
/// Двери лифта закрылись
fn car_door_closed() -> Event {
todo!("реализуй меня")
}
/// В вестибюле лифта на определенном этаже была нажата кнопка направления
fn lobby_call_button_pressed(floor: i32, dir: Direction) -> Event {
todo!("реализуй меня")
}
/// В кабине лифта была нажата кнопка этажа
fn car_floor_button_pressed(floor: i32) -> Event {
todo!("реализуй меня")
}
fn main() {
println!(
"Пассажир первого этажа нажал кнопку вверх: {:?}",
lobby_call_button_pressed(0, Direction::Up)
);
println!("Лифт прибыл на первый этаж: {:?}", car_arrived(0));
println!("Двери лифта открылись: {:?}", car_door_opened());
println!(
"Пассажир нажал на кнопку третьего этажа: {:?}",
car_floor_button_pressed(3)
);
println!("Двери лифта закрылись: {:?}", car_door_closed());
println!("Лифт прибыл на третий этаж: {:?}", car_arrived(3));
}
Решение:
Сопоставление с образцом
Деструктуризация
Как и кортежи (tuples), структуры (structs) и перечисления (enums) также могут деструктурироваться (destructure) сопоставлением:
Структуры
struct Foo {
x: (u32, u32),
y: u32,
}
// Запрещаем форматирование
#[rustfmt::skip]
fn main() {
let foo = Foo { x: (1, 2), y: 3 };
match foo {
Foo { x: (1, b), y } => println!("x.0 = 1, b = {b}, y = {y}"),
Foo { y: 2, x: i } => println!("y = 2, x = {i:?}"),
Foo { y, .. } => println!("y = {y}, другие поля игнорируются"),
}
}
Перечисления
Шаблоны (patterns) могут использоваться для привязки переменных к частям значений. Это, помимо прочего, позволяет исследовать структуру типов. Начнем с определения простого enum:
enum Result {
Ok(i32),
Err(String),
}
fn divide_in_two(n: i32) -> Result {
if n % 2 == 0 {
Result::Ok(n / 2)
} else {
Result::Err(format!("нельзя разделить {n} на 2 равные части"))
}
}
fn main() {
let n = 100;
match divide_in_two(n) {
Result::Ok(half) => println!("{n}, деленное на 2: {half}"),
Result::Err(msg) => println!("возникла ошибка: {msg}"),
}
}
Здесь для деструктуризации Result используется 2 блока (руки/рукава - arms). В первом блоке half привязывается к значению внутри варианта Ok. Во втором блоке msg привязывается к сообщению об ошибке (внутри варианта Err).
Структуры:
- измените литеральные значения в
fooдля совпадения с другими шаблонами - добавьте новое поле в
Fooи модифицируйте шаблон соответствующим образом
Перечисления:
- выражение
if-elseвозвращает перечисление, которое распаковывается с помощьюmatch - добавьте третий вариант в перечисление и изучите сообщение об ошибке
- доступ к значениям в вариантах перечисления возможен только после сопоставления с шаблоном
- изучите ошибки, связанные с тем, что сопоставление не является исчерпывающим
Поток управления let
Rust предоставляет несколько конструкций управления потоком выполнения программы, которых нет в других языках программирования и которые используются для сопоставления с шаблоном:
if letwhile letmatch
if let
Выражение if-let позволяет выполнять код в зависимости от совпадения значения с шаблоном:
fn sleep_for(secs: f32) {
let dur = if let Ok(dur) = std::time::Duration::try_from_secs_f32(secs) {
dur
} else {
std::time::Duration::from_millis(500)
};
std::thread::sleep(dur);
println!("спал в течение {:?}", dur);
}
fn main() {
// Выполнится код блока `else`
sleep_for(-10.0);
// Выполнится код блока `if`
sleep_for(0.8);
}
let-else
Для обычного случая сопоставления с шаблоном и возврата из функции следует использовать let-else. Код блока else должен прерывать поток выполнения программы (return, break, panic! и т.п.).
fn hex_or_die_trying(maybe_string: Option<String>) -> Result<u32, String> {
let s = if let Some(s) = maybe_string {
s
} else {
return Err(String::from("получено `None`"));
};
let first_byte_char = if let Some(first_byte_char) = s.chars().next() {
first_byte_char
} else {
return Err(String::from("получена пустая строка"));
};
if let Some(digit) = first_byte_char.to_digit(16) {
Ok(digit)
} else {
Err(String::from("не шестнадцатеричное число"))
}
}
fn main() {
println!("результат: {:?}", hex_or_die_trying(Some(String::from("foo")))); // 15 - байтовое представление символа `f`
}
Выражение while-let повторно проверяет соответствие значения шаблону:
fn main() {
let mut name = String::from("Comprehensive Rust 🦀");
while let Some(c) = name.pop() {
println!("символ: {c}");
}
// Существуют более эффективные способы 😉
}
Здесь String::pop() возвращает Some(c) до тех пор, пока строка не окажется пустой, после чего возвращается None. while-let позволяет перебирать все элементы.
if-let:
- в отличие от
match,if-letне должно охватывать все случаи. Поэтому его использование может быть менее многословным, чем использованиеmatch - обычным способом использования
if-letявляется обработкаSomeпри работе сOption - в отличие от
match,if-letне поддерживает защитников сопоставления (match guards)
let-else:
let-elseподдерживает распаковку (flattening) вложенного кода. Перепишем пример следующим образом:
fn hex_or_die_trying(maybe_string: Option<String>) -> Result<u32, String> {
let Some(s) = maybe_string else {
return Err(String::from("получено `None`"));
};
let Some(first_byte_char) = s.chars().next() else {
return Err(String::from("получена пустая строка"));
};
let Some(digit) = first_byte_char.to_digit(16) else {
return Err(String::from("не шестнадцатеричное число"));
};
return Ok(digit);
}
while-let:
- цикл
while-letповторяется, пока значение совпадает с шаблоном - цикл
while-letв примере можно сделать бесконечным с инструкциейifвнутри, которая прерывает цикл, когдаname.pop()ничего не возвращает
Упражнение: оценка выражения
Напишем простой рекурсивный вычислитель арифметических выражений.
Тип Box представляет собой умный указатель (smart pointer), который мы подробно рассмотрим позже. Выражение можно "упаковать" с помощью Box::new(), как показано в тестах. Для вычисления упакованного выражения, следует использовать оператор разыменования (*): eval(*boxed_expr).
Некоторые выражения не могут быть вычислены и возвращают ошибку. Стандартный тип Result<Value, String> - это перечисление, которое представляет успешное значение (Ok(Value)) или ошибку (Err(String)). Мы подробно рассмотрим этот тип позже.
// Операция, выполняемая над двумя подвыражениями
#[derive(Debug)]
enum Operation {
Add,
Sub,
Mul,
Div,
}
// Выражение в форме дерева
#[derive(Debug)]
enum Expression {
// Операция над двумя подвыражениями
Op {
op: Operation,
left: Box<Expression>,
right: Box<Expression>,
},
// Литеральное значение
Value(i64),
}
// Рекурсивный вычислитель арифметических выражений
fn eval(e: Expression) -> Result<i64, String> {
todo!("реализуй меня")
}
fn main() {
let expr = Expression::Op {
op: Operation::Sub,
left: Box::new(Expression::Value(20)),
right: Box::new(Expression::Value(10)),
};
println!("выражение: {:?}", expr);
println!("результат: {:?}", eval(expr));
}
// Модуль с тестами - код компилируется только при запуске тестов с помощью команды `cargo test`
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_value() {
assert_eq!(eval(Expression::Value(19)), Ok(19));
}
#[test]
fn test_sum() {
assert_eq!(
eval(Expression::Op {
op: Operation::Add,
left: Box::new(Expression::Value(10)),
right: Box::new(Expression::Value(20)),
}),
Ok(30)
);
}
#[test]
fn test_recursion() {
let term1 = Expression::Op {
op: Operation::Mul,
left: Box::new(Expression::Value(10)),
right: Box::new(Expression::Value(9)),
};
let term2 = Expression::Op {
op: Operation::Mul,
left: Box::new(Expression::Op {
op: Operation::Sub,
left: Box::new(Expression::Value(3)),
right: Box::new(Expression::Value(4)),
}),
right: Box::new(Expression::Value(5)),
};
assert_eq!(
eval(Expression::Op {
op: Operation::Add,
left: Box::new(term1),
right: Box::new(term2),
}),
Ok(85)
);
}
#[test]
fn test_error() {
assert_eq!(
eval(Expression::Op {
op: Operation::Div,
left: Box::new(Expression::Value(99)),
right: Box::new(Expression::Value(0)),
}),
Err(String::from("деление на ноль"))
);
}
}
Решение:
Методы и трейты
Методы
Rust позволяет привязывать функции к типам (такие функции называются ассоциированными - методы экземпляров в других языках). Это делается с помощью блока impl:
#[derive(Debug)]
struct Race {
name: String,
laps: Vec<i32>,
}
impl Race {
// Нет получателя, статичный метод
fn new(name: &str) -> Self {
Self { name: String::from(name), laps: Vec::new() }
}
// Эксклюзивное заимствование (exclusive borrowing), допускающее чтение и запись в `self`
fn add_lap(&mut self, lap: i32) {
self.laps.push(lap);
}
// Общее, доступное только для чтение заимствование (shared borrowing) `self`
fn print_laps(&self) {
println!("Записано время {} кругов для {}:", self.laps.len(), self.name);
for (idx, lap) in self.laps.iter().enumerate() {
println!("Круг {idx}: {lap} секунд");
}
}
// Эксклюзивное владение (exclusive ownership) `self`
fn finish(self) {
let total: i32 = self.laps.iter().sum();
println!("Гонка {} закончена, общее время: {}", self.name, total);
}
}
fn main() {
let mut race = Race::new("Monaco Grand Prix");
race.add_lap(70);
race.add_lap(68);
race.print_laps();
race.add_lap(71);
race.print_laps();
race.finish();
// race.add_lap(42);
}
Аргументы self определяют "получателя" (receiver) - объект, на котором реализуется метод. Получатели могут быть следующими:
&self- заимствует объект у вызывающего с помощью общей иммутабельной ссылки. После этого объект может быть повторно использован&mut self- заимствует объект у вызывающего с помощью уникальной мутабельной ссылки. После этого объект может быть повторно использованself- принимает владение объектом и перемещает его от вызывающего. Метод становится владельцем объекта. Объект удаляется (освобождается) после того, как метод вернул значение. Полное владение не означает автоматической мутабельностиmut self- аналогичноself, но метод может модифицировать объект- нет получателя - такой метод становится статичным. Обычно используется для создания конструкторов, которые по соглашению вызываются с помощью
new()
Ремарки:
- методы отличаются от функций следующим:
- методы вызываются на экземпляре типа (такого как структура или перечисление), их первый параметр - сам экземпляр (
self) - методы позволяют держать код реализации функционала в одном месте, что способствует лучшей организации кода
- методы вызываются на экземпляре типа (такого как структура или перечисление), их первый параметр - сам экземпляр (
- особенности использования ключевого слова
self:selfявляется сокращением дляself: Self, вместоSelfможет использоваться название структуры, например,Race- таким образом,
Self- это синоним реализуемого (impl) типа и может быть использован в любом месте внутри блока selfиспользуется как другие структуры, для доступа к его отдельным полям может использоваться точечная нотация- для демонстрации разницы между
&selfиselfпопробуйте запуститьfinish()дважды - существуют также специальные обертки типов, которые могут использоваться в качестве типов получателя, например,
Box<Self>
Трейты
Rust позволяет создавать абстрактные типы с помощью трейтов (traits). Они похожи на интерфейсы в других языках программирования:
struct Dog {
name: String,
age: i8,
}
struct Cat {
lives: i8,
}
trait Pet {
fn talk(&self) -> String;
fn greet(&self) {
println!("Какая милаха! Как тебя зовут? {}", self.talk());
}
}
impl Pet for Dog {
fn talk(&self) -> String {
format!("Гав, меня зовут {}!", self.name)
}
}
impl Pet for Cat {
fn talk(&self) -> String {
String::from("Мау!")
}
}
fn main() {
let captain_floof = Cat { lives: 9 };
let fido = Dog { name: String::from("Фидо"), age: 5 };
captain_floof.greet();
fido.greet();
}
Ремарки:
- трейт определяет методы, которые должен предоставлять тип для реализации этого трейта
- трейты реализуются в блоке
impl <trait> for <type> { .. } - трейты могут определять как дефолтные методы, так и методы, которые пользователь должен реализовать самостоятельно. Дефолтные методы могут полагаться на пользовательские:
greet()имеет реализацию по умолчанию и зависит отtalk()
Автоматическая реализация трейтов
Встроенные/стандартные трейты могут быть реализованы на кастомных типах автоматически:
#[derive(Debug, Clone, Default)]
struct Player {
name: String,
strength: u8,
hit_points: u8,
}
fn main() {
let p1 = Player::default(); // трейт `Default` добавляет конструктор `default()`.
let mut p2 = p1.clone(); // трейт `Clone` добавляет метод `clone()`
p2.name = String::from("EldurScrollz");
// Трейт `Debug` добавляет поддержку вывода в терминал с помощью `{:?}`.
println!("{:?} vs. {:?}", p1, p2);
}
Автоматическая реализация выполняется с помощью макросов, многие крейты предоставляют макросы для добавления полезного функционала. Например, крейт serde предоставляет автоматическую реализацию сериализации с помощью #[derive(Serialize)].
Трейт-объекты
Трейт-объекты (trait objects) позволяют хранить значения разных типов, например, в коллекции:
struct Dog {
name: String,
age: i8,
}
struct Cat {
lives: i8,
}
trait Pet {
fn talk(&self) -> String;
}
impl Pet for Dog {
fn talk(&self) -> String {
format!("Гав, меня зовут {}!", self.name)
}
}
impl Pet for Cat {
fn talk(&self) -> String {
String::from("Мау!")
}
}
fn main() {
// Трейт-объект, который может содержать значение любого типа, реализующего трейт `Pet`
let pets: Vec<Box<dyn Pet>> = vec![
Box::new(Cat { lives: 9 }),
Box::new(Dog { name: String::from("Фидо"), age: 5 }),
];
for pet in pets {
println!("Привет, кто ты? {}", pet.talk());
}
}
Память после выделения pets:
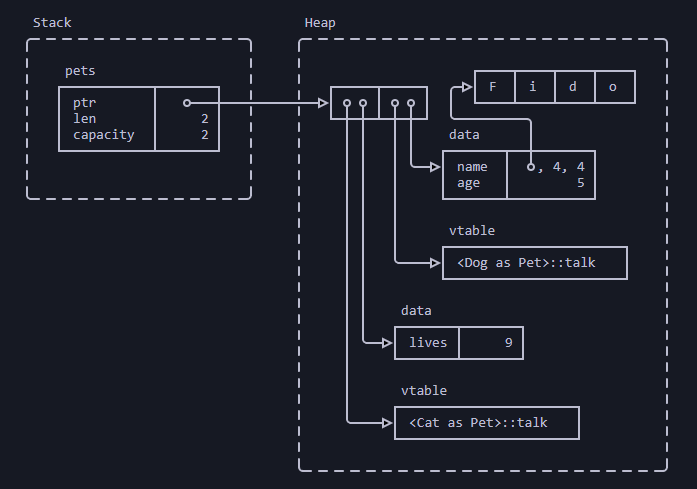
Ремарки:
- типы, реализующие определенный трейт, могут иметь разный размер. Это делает возможным такие вещи, как
Vec<dyn Pet>в примере dyn Pet- это способ сообщить компилятору о типе динамического размера, который реализуетPet- в примере
petsвыделяются в стеке (stack), а вектор - в куче (heap). 2 элемента вектора являются жирными указателями (fat pointers):- жирный указатель - это указатель двойной ширины. Он состоит из двух компонентов: указателя на реальный объект и указателя на таблицу виртуальных методов (vtable) для реализации
Petэтого конкретного объекта - данными для
Dogявляютсяnameиage.Catимеет полеlives
- жирный указатель - это указатель двойной ширины. Он состоит из двух компонентов: указателя на реальный объект и указателя на таблицу виртуальных методов (vtable) для реализации
- сравните эти выводы:
println!("{} {}", std::mem::size_of::<Dog>(), std::mem::size_of::<Cat>());
println!("{} {}", std::mem::size_of::<&Dog>(), std::mem::size_of::<&Cat>());
println!("{}", std::mem::size_of::<&dyn Pet>());
println!("{}", std::mem::size_of::<Box<dyn Pet>>());
Упражнение: библиотека GUI
Спроектируем классическую библиотеку GUI (graphical user interface - графический пользовательский интерфейс). Для простоты реализуем только его рисование - вывод в терминал в виде текста.
В нашей библиотеке будет несколько виджетов:
Window- имеетtitleи содержит другие виджетыButton- имеетlabel. В реальной библиотеке кнопка также будет принимать обработчик ее нажатияLabel- имеетlabel
Виджеты реализуют трейт Widget.
Напишите методы draw_into() для реализации трейта Widget.
pub trait Widget {
// Натуральная ширина `self`.
fn width(&self) -> usize;
// Рисуем/записываем виджет в буфер
fn draw_into(&self, buffer: &mut dyn std::fmt::Write);
// Рисуем виджет в стандартный вывод
fn draw(&self) {
let mut buffer = String::new();
self.draw_into(&mut buffer);
println!("{buffer}");
}
}
// Подпись может состоять из нескольких строк
pub struct Label {
label: String,
}
impl Label {
// Конструктор подписи
fn new(label: &str) -> Label {
Label { label: label.to_owned() }
}
}
pub struct Button {
label: Label,
}
impl Button {
// Конструктор кнопки
fn new(label: &str) -> Button {
Button { label: Label::new(label) }
}
}
pub struct Window {
title: String,
widgets: Vec<Box<dyn Widget>>,
}
impl Window {
// Конструктор окна
fn new(title: &str) -> Window {
Window { title: title.to_owned(), widgets: Vec::new() }
}
// Метод добавления виджета
fn add_widget(&mut self, widget: Box<dyn Widget>) {
self.widgets.push(widget);
}
// Метод получения максимальной ширины
fn inner_width(&self) -> usize {
std::cmp::max(
self.title.chars().count(),
self.widgets.iter().map(|w| w.width()).max().unwrap_or(0),
)
}
}
impl Widget for Window {
todo!("реализуй меня")
}
impl Widget for Button {
todo!("реализуй меня")
}
impl Widget for Label {
todo!("реализуй меня")
}
fn main() {
let mut window = Window::new("Rust GUI Demo 1.23");
window.add_widget(Box::new(Label::new("This is a small text GUI demo.")));
window.add_widget(Box::new(Button::new("Click me!")));
window.draw();
}
Вывод программы может быть очень простым:
========
Rust GUI Demo 1.23
========
This is a small text GUI demo.
| Click me! |
Или же можно воспользоваться операторами форматирования заполнения/выравнивания для выравнивания текста. Вот как можно управлять выравниванием текста с помощью разных символов (например, /):
fn main() {
let width = 10;
println!("слева: |{:/<width$}|", "foo");
println!("по центру: |{:/^width$}|", "foo");
println!("справа: |{:/>width$}|", "foo");
}
Эти приемы позволяют сделать вывод программы таким:
+--------------------------------+
| Rust GUI Demo 1.23 |
+================================+
| This is a small text GUI demo. |
| +-------------+ |
| | Click me! | |
| +-------------+ |
+--------------------------------+
Решение:
Дженерики
Общие функции
Rust поддерживает дженерики (generics), которые позволяют абстрагировать алгоритмы или структуры данных (например, сортировку или двоичное дерево) по используемым или хранимым типам:
// Функция возвращает `even` или `odd` в зависимости от значения `n`.
// Здесь `T` - это параметр типа (type parameter), индикатор дженерика
fn pick<T>(n: i32, even: T, odd: T) -> T {
if n % 2 == 0 {
even
} else {
odd
}
}
fn main() {
println!("возвращенное число: {:?}", pick(97, 222, 333));
println!("возвращенный кортеж: {:?}", pick(28, ("dog", 1), ("cat", 2)));
}
Ремарки:
Rustвыводит типы дляTна основе типов аргументов и типа возвращаемого значения- это похоже на шаблоны (templates)
C++, ноRustчастично компилирует универсальную функцию сразу, поэтому эта функция должна быть допустимой для всех типов, соответствующих ограничениям. Например, попробуйте изменить функциюpick()так, чтобы она возвращалаeven + odd, еслиn == 0. Даже если используется только реализацияpick()с целыми числами,Rustвсе равно считает ее недействительной.C++позволит вам это сделать - общий код преобразуется в обычный (необобщенный) код на основе того, как код вызывается. Это абстракция с нулевой стоимостью: мы получаем точно такой же результат, как если бы вручную закодировали структуры данных без абстракции
Общие структуры
Дженерики могут использоваться для абстрагирования типов полей структур:
#[derive(Debug)]
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
fn coords(&self) -> (&T, &T) {
(&self.x, &self.y)
}
// fn set_x(&mut self, x: T)
}
fn main() {
let integer = Point { x: 5, y: 10 };
let float = Point { x: 1.0, y: 4.0 };
println!("{integer:?} и {float:?}");
println!("координаты: {:?}", integer.coords());
}
- Почему
Tопределен дважды вimpl<T> Point<T>? Потому что:- это общая реализация общего типа - разные дженерики
- эти методы определяются для любого
T - можно написать
impl Point<u32>, тогда:Pointпо-прежнему будет дженериком, и мы сможем использоватьPoint<f64>, но методы в этом блоке будут доступны только дляPoint<u32>
- определите новую переменную
let p = Point { x: 5, y: 10.0 };и обновите код, чтобы он работал с разными типами - для этого потребуется 2 переменные типа, например,TиU
Ограничение трейтом
При работе с дженериками часто требуется, чтобы типы реализовывали какой-то трейт, чтобы можно было вызывать его методы.
Это делается с помощью T: Trait или impl Trait:
fn duplicate<T: Clone>(a: T) -> (T, T) {
(a.clone(), a.clone())
}
// struct NotClonable;
fn main() {
let foo = String::from("foo");
let pair = duplicate(foo);
println!("{pair:?}");
}
- Попробуйте создать
NotClonableи передать ее вduplicate() - для реализации нескольких трейтов можно использовать
+для их объединения - третьим вариантом реализации трейта является использование ключевого слова
where:
fn duplicate<T>(a: T) -> (T, T)
where
T: Clone,
{
(a.clone(), a.clone())
}
where"очищает" сигнатуру функции, если у нее много параметров.whereпредоставляет дополнительные функции, что делает его более мощным:- тип слева от
:может быть опциональным (Option<T>)
- тип слева от
- обратите внимание, что
Rust(пока) не поддерживает специализацию (перегрузку функции). Например, учитывая исходнуюduplicate(), невозможно добавить специализированнуюduplicate(a: u32)
impl Trait
По аналогии с ограничением типа трейтом, синтаксис impl Trait можно использовать в параметрах и возвращаемом значении функции:
// Синтаксический сахар для:
// fn add_42_millions<T: Into<i32>>(x: T) -> i32 {
fn add_42_millions(x: impl Into<i32>) -> i32 {
x.into() + 42_000_000
}
fn pair_of(x: u32) -> impl std::fmt::Debug {
(x + 1, x - 1)
}
fn main() {
let many = add_42_millions(42_i8);
println!("{many}");
let many_more = add_42_millions(10_000_000);
println!("{many_more}");
let debuggable = pair_of(27);
println!("отлаживаемый: {debuggable:?}");
}
impl Traitпозволяет работать с безымянными типами. Значениеimpl Traitзависит от места его использования:- для параметра
impl Traitпохож на анонимный общий параметр с ограничением трейтом - для возвращаемого типа это означает, что он - это некий конкретный тип, реализующий признак, без указания типа. Это может быть полезным, если мы не хотим раскрывать конкретный тип в общедоступном API
- для параметра
- каков тип
debuggable? Напишитеlet debuggable: () = ..и изучите сообщение об ошибке
Упражнение: определение минимального значение с помощью дженерика
В этом небольшом упражнении мы с помощью трейта LessThan реализуем общую функцию min(), которая определяет наименьшее из двух значений.
trait LessThan {
// Возвращаем `true`, если `self` меньше чем `other`
fn less_than(&self, other: &Self) -> bool;
}
#[derive(Debug, PartialEq, Eq, Clone, Copy)]
struct Citation {
author: &'static str,
year: u32,
}
impl LessThan for Citation {
fn less_than(&self, other: &Self) -> bool {
if self.author < other.author {
true
} else if self.author > other.author {
false
} else {
self.year < other.year
}
}
}
fn min() {
todo!("реализуй меня")
}
fn main() {
let cit1 = Citation { author: "Shapiro", year: 2011 };
let cit2 = Citation { author: "Baumann", year: 2010 };
let cit3 = Citation { author: "Baumann", year: 2019 };
// Отладочная версия `assert_eq!`, которая удаляется из производственных сборок
debug_assert_eq!(min(cit1, cit2), cit2);
debug_assert_eq!(min(cit2, cit3), cit2);
debug_assert_eq!(min(cit1, cit3), cit3);
}
Решение:
Типы, предоставляемые стандартной библиотекой Rust
Rust поставляется со стандартной библиотекой, которая помогает определить набор общих типов, используемых библиотеками и программами Rust. Таким образом, две библиотеки могут беспрепятственно работать вместе, поскольку обе они используют один и тот же тип String, например.
На самом деле Rust содержит несколько слоев стандартной библиотеки: core, alloc и std:
coreсодержит самые основные типы и функции, которые не зависят отlibc, распределителя (allocator) или даже наличия операционной системыallocвключает типы, для которых требуется глобальный распределитель кучи, напримерVec,BoxиArc- встраиваемые приложения, написанные на
Rust, часто используют толькоcoreи иногдаalloc
Документация
Rust предоставляет замечательную документацию, например:
- описание всех подробностей циклов
- описание примитивных типов, вроде u8
- описание типов стандартной библиотеки, таких как Option или BinaryHeap
Мы можем документировать собственный код:
/// Функция определяет, можно ли первый аргумент делить на второй
///
/// Если вторым аргументом является 0, результатом является `false`
fn is_divisible_by(lhs: u32, rhs: u32) -> bool {
if rhs == 0 {
return false;
}
lhs % rhs == 0
}
Содержимое рассматривается как Markdown. Все опубликованные библиотечные крейты (crates) Rust автоматически документируются на docs.rs с помощью инструмента rusdoc.
Чтобы документировать элемент внутри другого элемента (например, внутри модуля), используйте //! или /*! .. */, называемые "внутренними комментариями документа":
//! Этот модель содержит функционал, связанный с делением целых чисел
- Взгляните на документацию крейта rand
Option
Мы уже несколько раз встречались с Option. Он хранит либо некоторое значение Some(T), либо индикатор отсутствия значения None. Например, String::find() возвращает Option<usize>:
fn main() {
let name = "Löwe 老虎 Léopard Gepardi";
let mut position: Option<usize> = name.find('é');
println!("find вернул {position:?}");
assert_eq!(position.unwrap(), 14);
position = name.find('Z');
println!("find вернул {position:?}");
assert_eq!(position.expect("символ не найден"), 0);
}
Ремарки:
Optionшироко используется, не только в стандартной библиотекеunwrap()либо возвращает значениеSome, либо паникует.expect()похож наunwrap(), но принимает сообщение об ошибке- мы можем паниковать на
None, но мы также можем "случайно" забыть проверитьNone unwrap()/expect()обычно используются для распаковкиSomeв местах, где мы относительно уверены в корректной работе кода. Как правило, в реальных программахNoneобрабатывается лучшим способом
- мы можем паниковать на
- оптимизация ниши (niche optimization) означает, что
Option<T>часто занимает столько же памяти, сколькоT
Result
Result похож на Option, но является индикатором успеха или провала операции, каждый со своим типом. В дженерике Result<T, E> T используется в варианте Ok, а E - в варианте Err.
use std::fs::File;
use std::io::Read;
fn main() {
let file: Result<File, std::io::Error> = File::open("diary.txt");
match file {
Ok(mut file) => {
let mut contents = String::new();
if let Ok(bytes) = file.read_to_string(&mut contents) {
println!("{contents}\n({bytes} байт)");
} else {
println!("Невозможно прочитать файл");
}
}
Err(err) => {
println!("Невозможно открыть дневник: {err}");
}
}
}
Ремарки:
- как и в случае с
Option, значениеResultможет быть извлечено с помощьюunwrap()/expect() Resultсодержит большое количество полезных методов, поэтому рекомендуется ознакомиться с его документациейResult- это стандартный способ обработки ошибок, о чем мы поговорим в третьей части руководства- при работе с вводом/выводом тип
Result<T, std::io::Error>является настолько распространенным, чтоstd::ioпредоставляет специальныйResult, позволяющий указывать только тип значенияOk:
use std::fs::File;
use std::io::{Read, Result};
// `main()` тоже может возвращать `Result`
fn main() -> Result<()> {
// Оператор `?` либо распаковывает значение `Ok`, либо распространяет ошибку (возвращает ее вызывающему)
let mut file = File::open("diary.txt")?;
let mut contents = String::new();
let bytes = file.read_to_string(&mut contents)?;
println!("{contents}\n({bytes} байт)");
Ok(())
}
String
String - это стандартный выделяемый в куче (heap-allocated) расширяемый (growable) UTF-8 строковый буфер:
fn main() {
let mut s1 = String::new();
s1.push_str("привет");
println!("s1: длина = {}, емкость = {}", s1.len(), s1.capacity());
let mut s2 = String::with_capacity(s1.len() + 1);
s2.push_str(&s1);
s2.push('!');
println!("s2: длина = {}, емкость = {}", s2.len(), s2.capacity());
let s3 = String::from("🇨🇭");
println!("s3: длина = {}, количество символов = {}", s3.len(), s3.chars().count());
}
String реализует Deref<Target = str>: мы можем вызывать все методы str на String.
Ремарки:
String::new()возвращает новую пустую строку. Когда заранее известен размер строки, можно использоватьString::with_capacity()String::len()возвращает размерStringв байтах (который может отличаться от количества символов)String::chars()возвращает итератор по настоящим символам. Обратите внимание, чтоcharможет отличаться от того, что мы привыкли считать "символом", согласно кластерам графем (grapheme clusters)- когда мы говорим о строках, мы говорим о
&strилиString - когда тип реализует
Deref<Target = T>, компилятор позволяет прозрачно вызывать методыTStringреализуетDeref<Target = str>, что предоставляет ей доступ к методамstr- напишите и сравните
let s3 = s1.deref();иlet s3 = &*s1;
Stringреализован как обертка над вектором байт, многие методы вектора поддерживаютсяString, но с некоторыми ограничениями (гарантиями)- сравните разные способы индексирования
String:- извлечение символа с помощью
s3.chars().nth(i).unwrap(), гдеiнаходится в границах строки и за их пределами - извлечение подстроки (среза - slice) с помощью
s3[0..4], где диапазон находится в границах символов (character boundaries) и за их пределами
- извлечение символа с помощью
Vec
Vec - это стандартный расширяемый (resizable) буфер, выделяемый в куче:
fn main() {
let mut v1 = Vec::new();
v1.push(42);
println!("v1: длина = {}, емкость = {}", v1.len(), v1.capacity());
let mut v2 = Vec::with_capacity(v1.len() + 1);
v2.extend(v1.iter());
v2.push(9999);
println!("v2: длина = {}, емкость = {}", v2.len(), v2.capacity());
// Канонический макрос для инициализации вектора с элементами
let mut v3 = vec![0, 0, 1, 2, 3, 4];
// Сохраняем только четные элементы
v3.retain(|x| x % 2 == 0);
println!("{v3:?}");
// Удаляем последовательные дубликаты
v3.dedup();
println!("{v3:?}");
}
Vec реализует Deref<Target = [T]>: мы можем вызывать методы срезов на Vec.
Ремарки:
Vec- это тип коллекции, наряду сStringиHashMap. Данные, которые он содержит, хранятся в куче. Это означает, что размер данных может быть неизвестен во время компиляции. Он может увеличиваться и уменьшаться во время выполнения- обратите внимание, что
Vec<T>- это дженерик, но нам не нужно явно определятьT.Rustсамостоятельно выводит тип вектора после первого вызоваpush() vec![..]- это канонический макрос, позволяющий создавать векторы по аналогии сVec::new(), но с начальными элементами- для индексации вектора можно использовать
[], но при выходе за пределы вектора, программа запаникует. Более безопасным доступом к элементам вектора являетсяget(), возвращающийOption. Методpop()удаляет последний элемент вектора Vecимеет доступ ко всем методов срезов, о которых мы поговорим в третьей части руководства
HashMap
Стандартная хеш-карта с защитой от HashDoS-атак:
use std::collections::HashMap;
fn main() {
let mut page_counts = HashMap::new();
page_counts.insert("Adventures of Huckleberry Finn".to_string(), 207);
page_counts.insert("Grimms' Fairy Tales".to_string(), 751);
page_counts.insert("Pride and Prejudice".to_string(), 303);
if !page_counts.contains_key("Les Misérables") {
println!(
"We know about {} books, but not Les Misérables.",
page_counts.len()
);
}
for book in ["Pride and Prejudice", "Alice's Adventure in Wonderland"] {
match page_counts.get(book) {
Some(count) => println!("{book}: {count} pages"),
None => println!("{book} is unknown."),
}
}
// Метод `entry()` позволяет вставлять значения отсутствующих ключей
for book in ["Pride and Prejudice", "Alice's Adventure in Wonderland"] {
let page_count: &mut i32 = page_counts.entry(book.to_string()).or_insert(0);
*page_count += 1;
}
println!("{page_counts:#?}");
}
Ремарки:
HashMapне содержится в прелюдии (prelude) и должна импортироваться явно- попробуйте следующий код. Первая строка проверяет, содержится ли книга в карте и возвращает альтернативное значение при ее отсутствии. Вторая строка вставляет альтернативное значение, если книга не найдена в карте:
let pc1 = page_counts
.get("Harry Potter and the Sorcerer's Stone")
.unwrap_or(&336);
let pc2 = page_counts
.entry("The Hunger Games".to_string())
.or_insert(374);
- в отличие от
vec!,Rust, к сожалению, не предоставляет макросhashmap!- однако, начиная с
Rust 1.56,HashMapреализуетFrom<[(K, V); N]>, позволяющий инициализировать хэш-карту с помощью литерального массива:
- однако, начиная с
let page_counts = HashMap::from([
("Harry Potter and the Sorcerer's Stone".to_string(), 336),
("The Hunger Games".to_string(), 374),
]);
HashMapможет создаваться из любогоIterator, возвращающего кортежи(ключ, значение)- в примерах мы избегаем использования
&strв качестве ключей хэш-карт для простоты. Это возможно, но может привести к проблемам с заимствованием - рекомендуется внимательно ознакомиться с документацией
HashMap
Упражнение: счетчик
В этом упражнении мы возьмем очень простую структуру данных и сделаем ее универсальной. Она использует HashMap для отслеживания того, какие значения были просмотрены и сколько раз появлялось каждое из них.
Первоначальная версия Counter жестко запрограммирована для работы только со значениями u32. Сделайте структуру и ее методы универсальными для типа отслеживаемого значения, чтобы Counter мог работать с любым типом.
Если задание покажется вам слишком легким и вы быстро с ним справитесь, попробуйте использовать метод entry(), чтобы вдвое сократить количество поисков хеша, необходимых для реализации метода подсчета.
use std::collections::HashMap;
// `Counter` считает, сколько раз встретилось каждое значение типа `T`
struct Counter {
values: HashMap<u32, u64>,
}
impl Counter {
// Статичный метод создания нового `Counter`
fn new() -> Self {
Counter {
values: HashMap::new(),
}
}
// Метод подсчета появлений определенного значения
fn count(&mut self, value: u32) {
if self.values.contains_key(&value) {
*self.values.get_mut(&value).unwrap() += 1;
} else {
self.values.insert(value, 1);
}
}
// Метод возврата количества появлений определенного значения
fn times_seen(&self, value: u32) -> u64 {
self.values.get(&value).copied().unwrap_or_default()
}
}
fn main() {
let mut ctr = Counter::new();
ctr.count(13);
ctr.count(14);
ctr.count(16);
ctr.count(14);
ctr.count(14);
ctr.count(11);
for i in 10..20 {
println!("saw {} values equal to {}", ctr.times_seen(i), i);
}
let mut strctr = Counter::new();
strctr.count("apple");
strctr.count("orange");
strctr.count("apple");
println!("got {} apples", strctr.times_seen("apple"));
}
Подсказки:
- общим должен быть только тип ключа
- приступите к реализации
struct Counter<T>и внимательно изучите подсказку компилятора - общий тип должен реализовывать 2 встроенных типа: один из прелюдии, другой из
std::hash
Решение:
Трейты, предоставляемые стандартной библиотекой Rust
Рекомендуется внимательно ознакомиться с документацией каждого трейта.
Сравнения
Эти трейты поддерживают сравнение между значениями. Они могут реализовываться на типах, содержащих поля, которые реализуют эти трейты.
PartialEq и Eq
PartialEq - это отношение частичной эквивалентности (partial equivalence relation), с требуемым методом eq() и предоставляемым методом ne(). Эти методы вызываются операторами == и !=.
struct Key {
id: u32,
metadata: Option<String>,
}
impl PartialEq for Key {
fn eq(&self, other: &Self) -> bool {
self.id == other.id
}
}
Eq - это отношение полной эквивалентности (рефлексивное, симметричное и транзитивное), реализующее PartialEq. Функции, требующие полную эквивалентность, используют Eq как ограничивающий трейт (trait bound).
PartialEq может быть реализован для разных типов, а Eq нет, поскольку он является рефлексивным:
struct Key {
id: u32,
metadata: Option<String>,
}
impl PartialEq<u32> for Key {
fn eq(&self, other: &u32) -> bool {
self.id == *other
}
}
PartialOrd и Ord
PartialOrd определяет частичный порядок (partial ordering), с методом partial_cmp(). Этот метод используется для реализации операторов <, <=, >= и >.
use std::cmp::Ordering;
#[derive(Eq, PartialEq)]
struct Citation {
author: String,
year: u32,
}
impl PartialOrd for Citation {
fn partial_cmp(&self, other: &Self) -> Option<Ordering> {
match self.author.partial_cmp(&other.author) {
Some(Ordering::Equal) => self.year.partial_cmp(&other.year),
author_ord => author_ord,
}
}
}
Ord - это тотальный (total) порядок, с методом cmp(), возвращающим Ordering.
На практике эти трейты чаще реализуются автоматически (derive), чем вручную.
Операторы
Перегрузка операторов реализуется с помощью трейта std::ops:
#[derive(Debug, Copy, Clone)]
struct Point {
x: i32,
y: i32,
}
impl std::ops::Add for Point {
type Output = Self;
fn add(self, other: Self) -> Self {
Self { x: self.x + other.x, y: self.y + other.y }
}
}
fn main() {
let p1 = Point { x: 10, y: 20 };
let p2 = Point { x: 100, y: 200 };
println!("{:?} + {:?} = {:?}", p1, p2, p1 + p2);
}
- Мы можем реализовать
Addдля&Point. В каких случаях это может быть полезным?- Ответ:
Add::add()потребляетself. Если типT, для которого перегружается оператор, не являетсяCopy(копируемым), мы должны реализовать перегрузку оператора для&T. Это позволяет избежать необходимости явного клонирования при вызове
- Ответ:
- Почему
Outputявляется ассоциированным типом? Можем ли мы сделать его параметром типа или метода?- Короткий ответ: параметры типа функции контролируются вызывающим, а ассоциированные типы (
Output) - тем, кто реализует трейт
- Короткий ответ: параметры типа функции контролируются вызывающим, а ассоциированные типы (
- Мы можем реализовать
Addдля двух разных типов, например,impl Add<(i32, i32)> for Pointдобавит кортеж вPoint
From и Into
Типы, реализующие трейты From и Into, могут преобразовываться в другие типы:
fn main() {
let s = String::from("hello");
let addr = std::net::Ipv4Addr::from([127, 0, 0, 1]);
let one = i16::from(true);
let bigger = i32::from(123_i16);
println!("{s}, {addr}, {one}, {bigger}");
}
Into автоматически реализуется при реализации From:
fn main() {
let s: String = "hello".into();
let addr: std::net::Ipv4Addr = [127, 0, 0, 1].into();
let one: i16 = true.into();
let bigger: i32 = 123_i16.into();
println!("{s}, {addr}, {one}, {bigger}");
}
Приведение типов
Rust поддерживает как неявное приведение (преобразование) типов (casting), так и явное с помощью as:
fn main() {
let value: i64 = 1000;
println!("as u16: {}", value as u16);
println!("as i16: {}", value as i16);
println!("as u8: {}", value as u8);
}
Результаты as всегда определяются в Rust, поэтому являются согласованными на разных платформах. Это может не соответствовать нашему интуитивному мнению об изменении знака или приведении к меньшему типу.
Приведение типов с помощью as - это относительно сложный инструмент, который легко использовать неправильно и который может стать источником мелких ошибок, поскольку используемые типы или диапазоны значений в них могут легко измениться. Приведение лучше всего использовать тогда, когда целью является указать безусловное усечение (unconditional truncation) (например, выбор нижних 32 битов u64 с помощью as u32, независимо от того, что было в старших битах).
Для приведения, которое всегда можно выполнить успешно (например, из u32 в u64), предпочтительнее использовать From или Into. Для приведения, которое в некоторых случаях выполнить невозможно, доступны TryFrom и TryInto, которые позволяют по-разному обрабатывать случаи возможности и невозможности приведения одного типа к другому.
Read и Write
Read и BufRead позволяют абстрагироваться от источников (sources) u8:
use std::io::{BufRead, BufReader, Read, Result};
fn count_lines<R: Read>(reader: R) -> usize {
let buf_reader = BufReader::new(reader);
buf_reader.lines().count()
}
// Здесь `Result<T>` из `std::io` == `Result<T, std::io::Error>`
fn main() -> Result<()> {
let slice: &[u8] = b"foo\nbar\nbaz\n";
println!("строк в срезе: {}", count_lines(slice));
let file = std::fs::File::open(std::env::current_exe()?)?;
println!("строк в файле: {}", count_lines(file));
Ok(())
}
Write, в свою очередь, позволяет абстрагироваться от приемников (sinks) u8:
use std::io::{Result, Write};
fn log<W: Write>(writer: &mut W, msg: &str) -> Result<()> {
writer.write_all(msg.as_bytes())?;
writer.write_all("\n".as_bytes())
}
fn main() -> Result<()> {
let mut buffer = Vec::new();
log(&mut buffer, "Hello")?;
log(&mut buffer, "World")?;
println!("{:?}", buffer);
Ok(())
}
Трейт Default
Трейт Default генерирует дефолтное значение типа:
#[derive(Debug, Default)]
struct Derived {
x: u32,
y: String,
z: Implemented,
}
#[derive(Debug)]
struct Implemented(String);
impl Default for Implemented {
fn default() -> Self {
Self("Иван Петров".into())
}
}
fn main() {
let default_struct = Derived::default();
println!("{default_struct:#?}");
let almost_default_struct =
Derived { y: "Y установлена!".into(), ..Derived::default() };
println!("{almost_default_struct:#?}");
let nothing: Option<Derived> = None;
println!("{:#?}", nothing.unwrap_or_default());
}
Ремарки:
Defaultможет быть реализован как вручную, так и с помощьюderive- автоматическая реализация создает значение, в котором для всех полей установлены значения по умолчанию
- это означает, что все поля структуры также должны реализовывать
Default
- это означает, что все поля структуры также должны реализовывать
- стандартные типы
Rustчасто реализуютDefaultс разумными значениями (0,""и т.д.) - частичная инициализация структуры хорошо работает с
Default - стандартная библиотека
Rustзнает, что типы могут реализовыватьDefault, и предоставляет удобные методы, которые его используют - синтаксис
..называется синтаксисом обновления структуры
Замыкания
Замыкания (closures) или лямбда-выражения имеют типы, которым нельзя дать имя. Однако они реализуют специальные трейты Fn, FnMut и FnOnce:
fn apply_with_log(func: impl FnOnce(i32) -> i32, input: i32) -> i32 {
println!("вызов функции на {input}");
func(input)
}
fn main() {
let add_3 = |x| x + 3;
println!("add_3: {}", apply_with_log(add_3, 10));
println!("add_3: {}", apply_with_log(add_3, 20));
let mut v = Vec::new();
let mut accumulate = |x: i32| {
v.push(x);
v.iter().sum::<i32>()
};
println!("accumulate: {}", apply_with_log(&mut accumulate, 4));
println!("accumulate: {}", apply_with_log(&mut accumulate, 5));
let multiply_sum = |x| x * v.into_iter().sum::<i32>();
println!("multiply_sum: {}", apply_with_log(multiply_sum, 3));
}
Ремарки:
Fn(например,add_3) не потребляет и не изменяет захваченные значения или, возможно, вообще ничего не захватывает. Ее можно вызывать несколько раз одновременноFnMut(например,accumulate) может менять захваченные значения. Ее можно вызывать несколько раз, но не одновременноFnOnce(например,multiply_sum) можно вызвать только один раз. Она может потреблять захваченные значенияFnMut- это подтип (подтрейт - subtrait)FnOnce.Fn- это подтипFnMutиFnOnce. Это означает, что мы можем использоватьFnMutтам, где ожидаетсяFnOnce, иFnтам, где ожидаетсяFnMutилиFnOnce- при определении функции, принимающей замыкание, мы должны сначала брать
FnOnce, затемFnMutи в концеFnкак наиболее гибкий тип - напротив, при определении замыкания мы начинаем с
Fn - по умолчанию замыкание захватывают значение по ссылке. Ключевое слово
moveпозволяет замыканию захватывать само значение
fn make_greeter(prefix: String) -> impl Fn(&str) {
return move |name| println!("{} {}", prefix, name);
}
fn main() {
let hi = make_greeter("привет".to_string());
hi("всем");
}
Упражнение: ROT13
В этом упражнении мы реализуем классический шифр "ROT13".
Меняйте только алфавитные символы ASCII, чтобы результат оставался валидным UTF-8.
use std::io::Read;
struct RotDecoder<R: Read> {
input: R,
rot: u8,
}
impl<R: Read> Read for RotDecoder<R> {
fn read(&mut self, buf: &mut [u8]) -> std::io::Result<usize> {
todo!("реализуй меня")
}
}
fn main() {
let mut rot =
RotDecoder { input: "Gb trg gb gur bgure fvqr!".as_bytes(), rot: 13 };
let mut result = String::new();
// `read_to_string()` вызывает `read()` под капотом и преобразует его результат в строку
rot.read_to_string(&mut result).unwrap();
println!("{}", result);
}
#[cfg(test)]
mod test {
use super::*;
#[test]
fn joke() {
let mut rot =
RotDecoder { input: "Gb trg gb gur bgure fvqr!".as_bytes(), rot: 13 };
let mut result = String::new();
rot.read_to_string(&mut result).unwrap();
assert_eq!(&result, "To get to the other side!");
}
#[test]
fn binary() {
let input: Vec<u8> = (0..=255u8).collect();
let mut rot = RotDecoder::<&[u8]> { input: input.as_ref(), rot: 13 };
let mut buf = [0u8; 256];
assert_eq!(rot.read(&mut buf).unwrap(), 256);
for i in 0..=255 {
if input[i] != buf[i] {
assert!(input[i].is_ascii_alphabetic());
assert!(buf[i].is_ascii_alphabetic());
}
}
}
}
Решение:
Управление памятью
Обзор памяти программы
Программы выделяют (allocate) память двумя способами:
- стек (stack): непрерывная область памяти для локальных переменных
- значения имеют фиксированный размер, известный во время компиляции
- очень быстрый: просто перемещаем указатель стека (stack pointer)
- легко управлять: следуем за вызовами функций
- отличная локализованность памяти (память находится в одном месте)
- куча (heap): хранилище значений за пределами вызовов функций
- значения имеют динамический размер, определяемый во время выполнения
- немного медленнее, чем стек: имеются некоторые накладные расходы
- нет гарантии локализованности памяти
Пример
Создание String помещает метаданные фиксированного размера в стек и данные динамического размера (настоящую строку) в кучу:
fn main() {
let s1 = String::from("Привет");
}
Мы можем исследовать память, но это совершенно небезопасно:
fn main() {
let mut s1 = String::from("Привет");
s1.push(' ');
s1.push_str("всем");
// Только для целей обучения.
// Это может привести к непредсказуемому поведению
unsafe {
let (ptr, capacity, len): (usize, usize, usize) = std::mem::transmute(s1);
println!("ptr = {ptr:#x}, len = {len}, capacity = {capacity}");
}
}
Подходы к управлению памятью
Традиционно, языки программирования делятся на 2 категории:
- полный контроль через ручное управление памятью: C, C++, Pascal и др.
- когда выделять и освобождать память в куче решает программист
- программист определяет, указывает ли указатель на валидную память
- опыт показывает, что программисты совершают ошибки
- полная безопасность через автоматическое управление памятью во время выполнения:
- система обеспечивает, что память не освобождается до тех пор, пока на нее имеются ссылки
- обычно реализуется с помощью подсчета ссылок (reference counting), сборку мусора (garbage collection) или RAII
Rust предлагает новый подход - полный контроль и безопасность во время компиляции обеспечивают правильное управление памятью.
Это делается с помощью владения (ownership).
- в
Cуправление памятью осуществляется с помощью функцийmallocиfree. Часто ошибки заключаются в не вызовеfree, ее многократном вызове или разыменовании указателя на освобожденный ресурс C++предоставляет инструменты, такие как умные указатели (unique_ptr,shared_ptr), которые автоматически вызывают деструкторы для освобождения памяти после возврата значения из функции. Однако это решает далеко не все проблемыCJava,Go,Python,JavaScriptи др. полагаются на сборщик мусора (garbage collector) в определении неиспользуемой памяти и ее освобождении. Это позволяет избежать багов, связанных с разыменованием указателей на освобожденные ресурсы и т.п. Однако GC имеет свою цену времени выполнения и его сложно настраивать
Модель владения и заимствования Rust позволяет добиться производительности C без свойственных ему проблем с безопасностью памяти. Rust также предоставляет умные указатели, похожие на умные указатели C++. Доступны и другие варианты, такие как подсчет ссылок. Существуют даже сторонние крейты, поддерживающие сборку мусора во время выполнения (мы не будем их рассматривать).
Владение
Все привязки переменных имеют свою область видимости (scope). Попытка использовать переменную за пределами ее области видимости приводит к ошибке:
struct Point(i32, i32);
fn main() {
{
let p = Point(3, 4);
println!("x: {}", p.0);
}
println!("y: {}", p.1);
}
Мы говорим, что переменная владеет (own) значением. Каждое значение может иметь только одного владельца.
В конце области видимости переменная уничтожается (dropped), а память освобождается (freed). Здесь может запускаться деструктор для освобождения ресурсов.
GC начинает с корневых узлов (roots) для обнаружения всех достижимых (reachable) объектов. Это похоже на принцип "одного владельца" в Rust.
Перемещение
Присвоение перемещает (move) владение значения между переменными:
fn main() {
let s1: String = String::from("Привет");
let s2: String = s1;
println!("s2: {s2}");
// println!("s1: {s1}");
}
- Присвоение
s1s2перемещает владение строкой"Привет" - когда
s1выходит за пределы области видимости, ничего не происходит, потому что эта переменная больше ничем не владеет - когда
s2выходит за пределы области видимости, данные строки освобождаются
Перед перемещением владения:
После:
Когда мы передаем значение в функцию, оно присваивается ее параметру, происходит перемещение владения:
fn say_hello(name: String) {
println!("Привет {name}")
}
fn main() {
let name = String::from("Алиса");
// Владение перемещается в `say_hello`
say_hello(name);
// say_hello(name);
}
- Вызывая функцию
say_hello, функцияmainпередает ей владение значениемname. После этогоnameбольше не может использоваться вmain - память, выделенная в куче для
name, будет освобождена после вызоваsay_hello mainможет сохранить владение значениемname, если передаст вsay_helloссылку на него (&name), и параметром, принимаемымsay_hello, будет ссылка (name: &String)- вторым вариантом является передача
say_helloкопии/клонаname(name.clone()) - в
Rust, в отличие отC++, копии значений чаще всего приходится создавать явно
Clone
Иногда нам нужно создать копию значения. Для этого предназначен трейт Clone:
#[derive(Default)]
struct Backends {
hostnames: Vec<String>,
weights: Vec<f64>,
}
impl Backends {
fn set_hostnames(&mut self, hostnames: &Vec<String>) {
// Вектор реализует трейт `Clone` по умолчанию
self.hostnames = hostnames.clone();
self.weights = hostnames.iter().map(|_| 1.0).collect();
}
}
Идея Clone заключается в том, чтобы облегчить определение места распределения кучи.
Клонирование часто используется для быстрого решения проблем, связанных с владением и заимствованием, с последующей оптимизацией за счет их удаления.
Копируемые типы
Хотя семантика перемещения используется по умолчанию, некоторые типы по умолчанию копируются:
fn main() {
let x = 42;
let y = x;
println!("x: {x}"); // переменная `x` не была бы доступной без копирования
println!("y: {y}");
}
Такие типы реализуют трейт Copy.
Мы можем сделать так, чтобы наши типы использовали семантику копирования:
#[derive(Copy, Clone, Debug)]
struct Point(i32, i32);
fn main() {
let p1 = Point(3, 4);
let p2 = p1;
println!("p1: {p1:?}");
println!("p2: {p2:?}");
}
- После присвоения
p1иp2владеют собственными данными - мы также можем использовать
p1.clone()для явного копирования данных
Копирование и клонирование - это разные вещи:
- копирование относится к побитовому копированию областей памяти и не работает с произвольными объектами
- копирование не позволяет использовать собственную логику (в отличие от конструкторов копирования в
C++) - клонирование - это более общая операция, которая также позволяет настраивать поведение путем реализации трейта
Clone - копирование не работает на типах, которые реализуют трейт
Drop
Попробуйте сделать следующее в примере:
- добавьте поле
Stringв структуруPoint. Пример не будет компилироваться, посколькуStringне является копируемым типом - удалите
Copyиз атрибутаderive. При попытке вывести значениеp1в терминал возникнет ошибка - попробуйте клонировать
p1явно
Трейт Drop
Значения, реализующие трейт Drop, могут определять код, который запускается при их выходе за пределы области видимости:
struct Droppable {
name: &'static str,
}
impl Drop for Droppable {
fn drop(&mut self) {
println!("уничтожение {}", self.name);
}
}
fn main() {
let a = Droppable { name: "a" };
{
let b = Droppable { name: "b" };
{
let c = Droppable { name: "c" };
let d = Droppable { name: "d" };
println!("выход из блока B");
}
println!("выход из блока A");
}
drop(a);
println!("выход из main");
}
Ремарки:
-
обратите внимание, что
std::mem::dropиstd::ops::Drop::drop- это разные вещи -
значения автоматически уничтожаются при выходе за пределы их области видимости
-
после уничтожения значения, вызывается его реализация
Drop::drop, если значение реализуетstd::ops::Drop -
все поля структуры также уничтожаются, независимо от того, реализуют они
Dropили нет -
std::mem::drop- это пустая функция, не принимающая никаких значений. Важно то, что она принимает владение значением, которое уничтожается после ее вызова. С помощью этой функции можно уничтожать значения до того, как они выйдут за пределы их области видимости- это может быть полезным для объектов, которые выполняют какую-то работу при уничтожении: снятие блокировки (releasing lock), закрытие файла (дескриптора) и др.
-
Почему
Drop::dropне принимаетself?- Короткий ответ: в этом случае
std::mem::dropбудет вызвана в конце блока, что приведет к другому вызовуDrop::dropи переполнению стека!
- Короткий ответ: в этом случае
-
Попробуйте заменить
drop(a)наa.drop()
Упражнение: тип "Строитель"
В этом упражнении мы реализуем сложный тип, который владеет всеми своими данными. Мы будем использовать "шаблон построителя" (builder patterm) для поэтапного построения нового значения с использованием удобных функций.
#[derive(Debug)]
enum Language {
Rust,
Java,
Perl,
}
#[derive(Clone, Debug)]
struct Dependency {
name: String,
version_expression: String,
}
// Представление пакета ПО
#[derive(Debug)]
struct Package {
name: String,
version: String,
authors: Vec<String>,
dependencies: Vec<Dependency>,
// Это поле является опциональным
language: Option<Language>,
}
impl Package {
// Метод для возврата представления пакета как зависимости
// для использования в создании других пакетов
fn as_dependency(&self) -> Dependency {
todo!("1")
}
}
// Строитель пакета. Для создания `Package` используется метод `build`
struct PackageBuilder(Package);
impl PackageBuilder {
fn new(name: impl Into<String>) -> Self {
todo!("2")
}
// Метод установки версии пакета
fn version(mut self, version: impl Into<String>) -> Self {
self.0.version = version.into();
self
}
// Метод установки автора пакета
fn authors(mut self, authors: Vec<String>) -> Self {
todo!("3")
}
// Метод добавления дополнительной зависимости
fn dependency(mut self, dependency: Dependency) -> Self {
todo!("4")
}
// Метод установки языка. Если не установлен, по умолчанию имеет значение `None`
fn language(mut self, language: Language) -> Self {
todo!("5")
}
fn build(self) -> Package {
self.0
}
}
fn main() {
let base64 = PackageBuilder::new("base64").version("0.13").build();
println!("base64: {base64:?}");
let log =
PackageBuilder::new("log").version("0.4").language(Language::Rust).build();
println!("log: {log:?}");
let serde = PackageBuilder::new("serde")
.authors(vec!["djmitche".into()])
.version(String::from("4.0"))
.dependency(base64.as_dependency())
.dependency(log.as_dependency())
.build();
println!("serde: {serde:?}");
}
Решение:
Умные указатели
Box<T>
Box - это собственный указатель на данные в куче:
fn main() {
let five = Box::new(5);
println!("пять: {}", *five);
}
Box<T> реализует Deref<Target = T>: мы можем вызывать методы T прямо на Box<T>.
Рекурсивные типы или типы динамического размера должны использовать Box:
#[derive(Debug)]
enum List<T> {
// Непустой список: первый элемент и остальная часть списка
Element(T, Box<List<T>>),
// Пустой список
Nil,
}
fn main() {
let list: List<i32> =
List::Element(1, Box::new(List::Element(2, Box::new(List::Nil))));
println!("{list:?}");
}
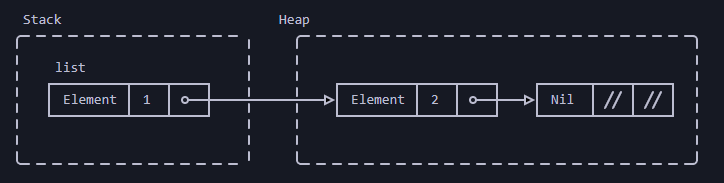
Ремарки:
Boxпохож наstd::unique_ptrвC++, за исключением того, что он не может иметь значениеNULLBoxможет быть полезным, когда- у нас есть тип, размер которого неизвестен во время компиляции, а компилятору
Rustнужен точный размер - мы хотим передать владение большого количества данных. Вместо копирования большого количества данных в стеке, мы храним данные в куче в
Boxи перемещаем только указатель
- у нас есть тип, размер которого неизвестен во время компиляции, а компилятору
- если мы попытаемся внедрить
Listпрямо вListбез использованияBox, компилятор не сможет вычислить точный размер структуры в памяти (Listбудет иметь бесконечный размер) Boxрешает эту проблему, поскольку он имеет такой же размер, что обычный указатель и просто указывает на следующий элемент списка в куче- удалите
Boxиз определенияListи изучите ошибку компилятора
Нишевая оптимизация
#[derive(Debug)]
enum List<T> {
Element(T, Box<List<T>>),
Nil,
}
fn main() {
let list: List<i32> =
List::Element(1, Box::new(List::Element(2, Box::new(List::Nil))));
println!("{list:?}");
}
Box не может быть пустым, поэтому указатель всегда является валидным и не может иметь значение NULL. Это позволяет компилятору оптимизировать слой памяти:

Rc
Rc - это общий указатель с подсчетом ссылок. Он используется, когда нужно сослаться на одни и те же данные из нескольких мест:
use std::rc::Rc;
fn main() {
let a = Rc::new(10);
let b = Rc::clone(&a);
println!("a: {a}");
println!("b: {b}");
}
- В многопоточных контекстах следует использовать Arc и Mutex
- мы можем понизить общий указатель до слабого указателя (Weak) для создания циклов, которые будут правильно уничтожены в свое время
Ремарки:
- счетчик
Rcгарантирует, что содержащееся в нем значение действительно до тех пор, пока существуют ссылки на него RcвRustпохож наstd::shared_ptrвC++Rc::cloneобходится дешево: он создает указатель на одно и то же место в памяти и увеличивает счетчик ссылок. Он не создает глубоких клонов, и его обычно можно игнорировать при поиске в коде проблем с производительностьюmake_mutфактически клонирует внутреннее значение при необходимости ("клонирование при записи" - clone-on-write) и возвращает изменяемую ссылкуRc::strong_countиспользуется для определения количества активных ссылокRc::downgrade(вероятно, в сочетании сRefCell) позволяет создавать объекты со слабым подсчетом ссылок для создания циклов, которые будут правильно удалены в будущем
Упражнение: двоичное дерево
Бинарное дерево (binary tree) - это древовидная структура данных, в которой каждый узел имеет 2 дочерних элемента (левый и правый). Мы создадим дерево, в котором каждый узел хранит значение. Для данного узла N все узлы в левом поддереве N содержат меньшие значения, а все узлы в правом поддереве N - большие значения.
Если задание покажется вам легким и вы быстро с ним справитесь, попробуйте реализовать итератор по дереву, который будет возвращать все значения по порядку.
// Узел дерева
#[derive(Debug)]
struct Node<T: Ord> {
value: T,
left: Subtree<T>,
right: Subtree<T>,
}
// Поддерево, которое может быть пустым
#[derive(Debug)]
struct Subtree<T: Ord>(Option<Box<Node<T>>>);
// Контейнер, хранящий набор значений с помощью двоичного дерева.
// Значение сохраняется только один раз, независимо от того, сколько раз оно добавляется
#[derive(Debug)]
pub struct BinaryTree<T: Ord> {
root: Subtree<T>,
}
impl<T: Ord> BinaryTree<T> {
fn new() -> Self {
todo!("реализуй меня")
}
fn insert(&mut self, value: T) {
todo!("реализуй меня")
}
fn has(&self, value: &T) -> bool {
todo!("реализуй меня")
}
fn len(&self) -> usize {
todo!("реализуй меня")
}
}
impl<T: Ord> Subtree<T> {
fn new() -> Self {
todo!("реализуй меня")
}
fn insert(&mut self, value: T) {
todo!("реализуй меня")
}
fn has(&self, value: &T) -> bool {
todo!("реализуй меня")
}
fn len(&self) -> usize {
todo!("реализуй меня")
}
}
impl<T: Ord> Node<T> {
fn new(value: T) -> Self {
todo!("реализуй меня")
}
}
fn main() {
let mut tree = BinaryTree::new();
tree.insert("foo");
assert_eq!(tree.len(), 1);
tree.insert("bar");
assert!(tree.has(&"foo"));
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn len() {
let mut tree = BinaryTree::new();
assert_eq!(tree.len(), 0);
tree.insert(2);
assert_eq!(tree.len(), 1);
tree.insert(1);
assert_eq!(tree.len(), 2);
tree.insert(2); // дубликат
assert_eq!(tree.len(), 2);
}
#[test]
fn has() {
let mut tree = BinaryTree::new();
fn check_has(tree: &BinaryTree<i32>, exp: &[bool]) {
let got: Vec<bool> =
(0..exp.len()).map(|i| tree.has(&(i as i32))).collect();
assert_eq!(&got, exp);
}
check_has(&tree, &[false, false, false, false, false]);
tree.insert(0);
check_has(&tree, &[true, false, false, false, false]);
tree.insert(4);
check_has(&tree, &[true, false, false, false, true]);
tree.insert(4);
check_has(&tree, &[true, false, false, false, true]);
tree.insert(3);
check_has(&tree, &[true, false, false, true, true]);
}
#[test]
fn unbalanced() {
let mut tree = BinaryTree::new();
for i in 0..100 {
tree.insert(i);
}
assert_eq!(tree.len(), 100);
assert!(tree.has(&50));
}
}
Подсказка: для сопоставления с шаблоном при сравнении значений следует использовать std::cmp::Ordering.
Решение:
Заимствование
Заимствование значения
Как мы знаем, вместо передачи владения (ownership) значением при вызове функции, можно позволить функции заимствовать (borrow) это значение:
#[derive(Debug)]
struct Point(i32, i32);
fn add(p1: &Point, p2: &Point) -> Point {
Point(p1.0 + p2.0, p1.1 + p2.1)
}
fn main() {
let p1 = Point(3, 4);
let p2 = Point(10, 20);
let p3 = add(&p1, &p2);
println!("{p1:?} + {p2:?} = {p3:?}");
}
- Функция
addзаимствует 2 точки (point) и возвращает новую точку - вызывающий (caller,
main) сохраняет владение точками
Ремарки:
- возврат значения из функции
addобходится дешево, поскольку компилятор может исключить операцию копирования - компилятор
Rustумеет выполнять оптимизацию возвращаемого значения (return value optimization - RVO) - в
C++исключение копирования должно быть определено в спецификации языка, поскольку конструкторы могут иметь побочные эффекты. ВRustэто не проблема. ЕслиRVOне произошло,Rustвыполняет простое и эффективное копированиеmemcpy
Проверка заимствований
Контроллер заимствований (borrow checker) ограничивает способы заимствования значений. Для определенного значения в любое время:
- мы можем иметь одну или более общие/распределенные (shared) ссылки на значение или
- мы можем иметь только одну эксклюзивную/исключительную (exclusive) ссылку на значение
fn main() {
let mut a: i32 = 10;
let b: &i32 = &a;
{
let c: &mut i32 = &mut a;
*c = 20;
}
println!("a: {a}");
println!("b: {b}");
}
Ремарки:
- обратите внимание: требование состоит в том, чтобы конфликтующие ссылки не существовали в одно время. Не имеет значения, где ссылка разыменовывается
- код примера не компилируется, поскольку
aзаимствуется как мутабельная (черезc) и как иммутабельная (черезb) одновременно - переместите
println!("b: {b}");перед областью видимостиc, чтобы скомпилировать код - после этого изменения компилятор понимает, что
bиспользуется только до нового мутабельного заимствованияa. Это особенность контроллера заимствований, которая называется "нелексическим временем жизни" (non-lexical lifetimes) - ограничение эксклюзивной ссылки является довольно строгим.
Rustиспользует его, чтобы гарантировать отсутствие гонок за данными (data races).Rustтакже использует это ограничение для оптимизации кода. Например, значение общей ссылки можно безопасно кэшировать в регистре на время ее существования - контроллер заимствований предназначен для использования многих распространенных шаблонов, таких как одновременное получение эксклюзивных ссылок на разные поля в структуре. Но в некоторых ситуациях он не понимает, что мы хотим сделать, и с ним приходится бороться
Внутренняя изменчивость
Rust предоставляет несколько безопасных способов изменения значения, используя только общую ссылку на это значение. Все они заменяют проверки во время компиляции проверками во время выполнения.
Cell и RefCell
Cell и RefCell реализуют то, что в Rust называется внутренней изменчивостью (interior mutability): мутацией значений в неизменяемом контексте.
Cell обычно используется для простых типов, поскольку требует копирования или перемещения значений. Более сложные типы внутреннего пространства обычно используют RefCell, который отслеживает общие и эксклюзивные ссылки во время выполнения и паникует, если они используются неправильно.
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug, Default)]
struct Node {
value: i64,
children: Vec<Rc<RefCell<Node>>>,
}
impl Node {
fn new(value: i64) -> Rc<RefCell<Node>> {
Rc::new(RefCell::new(Node { value, ..Node::default() }))
}
fn sum(&self) -> i64 {
self.value + self.children.iter().map(|c| c.borrow().sum()).sum::<i64>()
}
}
fn main() {
let root = Node::new(1);
root.borrow_mut().children.push(Node::new(5));
let subtree = Node::new(10);
subtree.borrow_mut().children.push(Node::new(11));
subtree.borrow_mut().children.push(Node::new(12));
root.borrow_mut().children.push(subtree);
println!("graph: {root:#?}");
println!("graph sum: {}", root.borrow().sum());
}
Ремарки:
- если бы в этом примере мы использовали
CellвместоRefCell, нам пришлось бы переместитьNodeизRc, чтобы добавить дочерние элементы, а затем вернуть его обратно. Это безопасно, поскольку в ячейке всегда есть одно значение, на которое нет ссылки, но это не эргономично - для того, чтобы сделать что-то с
Node, нужно вызвать какой-нибудь методRefCell, обычноborrowилиborrow_mut - ссылочные циклы могут быть созданы путем добавления
rootвsubtree.children(не пытайтесь вывести их в терминал) - для того, чтобы вызвать панику во время выполнения, добавьте
fn inc(&mut self), который увеличиваетself.valueи вызывает тот же метод для своих дочерних элементов. Это вызовет панику из-за наличия ссылочного цикла:thread 'main' panicked at 'already borrowed: BorrowMutError'
Упражнение: показатели здоровья
Вы работаете над внедрением системы мониторинга здоровья. В рамках этого вам необходимо отслеживать показатели здоровья пользователей.
Ваша задача - реализовать метод visit_doctor в структуре User.
#![allow(dead_code)]
pub struct User {
name: String,
age: u32,
height: f32,
visit_count: usize,
// Опциональное поле
last_blood_pressure: Option<(u32, u32)>,
}
pub struct Measurements {
height: f32,
blood_pressure: (u32, u32),
}
// 'a - это время жизни, мы поговорим об этом в следующем разделе
pub struct HealthReport<'a> {
patient_name: &'a str,
visit_count: u32,
height_change: f32,
// Опциональное поле
blood_pressure_change: Option<(i32, i32)>,
}
impl User {
pub fn new(name: String, age: u32, height: f32) -> Self {
Self {
name,
age,
height,
visit_count: 0,
last_blood_pressure: None,
}
}
pub fn visit_doctor(&mut self, measurements: Measurements) -> HealthReport {
todo!("Обновляем показатели здоровья пользователя на основе измерений в результате посещения врача")
}
}
fn main() {
let bob = User::new(String::from("Bob"), 32, 155.2);
println!("I'm {} and my age is {}", bob.name, bob.age);
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_visit() {
let mut bob = User::new(String::from("Bob"), 32, 155.2);
assert_eq!(bob.visit_count, 0);
let report = bob.visit_doctor(Measurements {
height: 156.1,
blood_pressure: (120, 80),
});
assert_eq!(report.patient_name, "Bob");
assert_eq!(report.visit_count, 1);
assert_eq!(report.blood_pressure_change, None);
let report = bob.visit_doctor(Measurements {
height: 156.1,
blood_pressure: (115, 76),
});
assert_eq!(report.visit_count, 2);
assert_eq!(report.blood_pressure_change, Some((-5, -4)));
}
}
Решение:
Срезы и времена жизни
Срезы
Срез (slice) - это представление (view) (часть) большой коллекции значений:
fn main() {
let mut a: [i32; 6] = [10, 20, 30, 40, 50, 60];
println!("a: {a:?}");
let s: &[i32] = &a[2..4];
println!("s: {s:?}");
}
- Срезы заимствуют данные из исходного типа
- Вопрос: что произойдет, если модифицировать
a[3]перед выводомsв терминал?
Ремарки:
- мы создаем срез путем заимствования
aи определения начального и конечного индексов в квадратных скобках - если срез начинается с индекса
0, синтаксис диапазонаRustпозволяет не указывать начальный индекс:&a[0..a.len()]==&a[..a.len()] - тоже справедливо для конечного индекса:
&a[2..a.len()]==&a[2..] - срез всего массива можно создать с помощью
&a[..] s- это ссылка на срез целых чисел со знаком. Обратите внимание, что в типеs(&[i32]) не упоминается длина массива. Это позволяет вычислять срезы разных размеров- срезы всегда заимствуют значения объектов. В примере
aостается "живой" (в области видимости) до тех пор, пока "жив" его срез - вопрос об изменении
a[3]может вызвать интересную дискуссию, но ответ заключается в том, что из соображений безопасности памяти мы не можем сделать это черезaна данном этапе выполнения кода, но мы можем безопасно читать данные как изa, так и изs. Это работает до создания среза и после вызоваprintln!, когда срез больше не используется
Строки
Теперь мы можем разобраться с типом &str: это почти &[char], но с данными, хранящимися в кодировке переменной длины (UTF-8).
fn main() {
let s1: &str = "World";
println!("s1: {s1}");
let mut s2: String = String::from("Hello ");
println!("s2: {s2}");
s2.push_str(s1);
println!("s2: {s2}");
let s3: &str = &s2[6..];
println!("s3: {s3}");
}
&str- иммутабельная ссылка на строковый срезString- мутабельная ссылка на буфер
Ремарки:
&str- это срез строки, иммутабельная ссылка на закодированные в UTF-8 текстовые данные, хранящиеся в блоке памяти. Строковые литералы ("Hello") хранятся в бинарнике (исполняемом файле) программы- тип
String- это обертка над вектором байтов. Как иVec<T>, он является собственным (owned) String::from()создает строку из литерала строки;String::new()создает новую пустую строку, в которую можно добавлять строковые данные с помощью методовpushиpush_str- макрос
format!генерирует собственную строку из динамических значений. Стиль его форматирования схож сprintln! - мы можем заимствовать срезы
&strизStringчерез&и опциональный диапазон выбора (range selection). Если выбран диапазон байтов, который не совпадает с границами символов (character boundaries), выражение запаникует. Итераторcharsперебирает символы и является предпочтительным способом правильного извлечения символов - байтовые строки позволяют создавать
&[u8]напрямую:
fn main() {
let byte_string = b"abc";
println!("{:?}", byte_string);
assert_eq!(byte_string, &[97, 98, 99])
}
Аннотации времен жизни
Ссылка имеет время жизни (lifetime), она не должна "переживать" значение, на которое ссылается. Соблюдение этого правила обеспечивается контроллером заимствований (borrow checker).
Время жизни может определяться неявно - то, что мы видели до сих пор. Времена жизни также могут быть явными: &'a Point, &'static str. Времена жизни начинаются с ' и 'a - имя по умолчанию. &'a Point читается как "заимствование структуры Point, которое является валидным на протяжении времени жизни a".
Времена жизни всегда выводятся (inferred) компилятором, они не могут присваиваться явно. Явные аннотации (annotations) времен жизни создают ограничения в случае неопределенности; компилятор предоставляет валидное решение в рамках этих ограничений.
Времена жизни становятся сложными, когда значения передаются в и возвращаются из функции:
#[derive(Debug)]
struct Point(i32, i32);
fn left_most(p1: &Point, p2: &Point) -> &Point {
if p1.0 < p2.0 {
p1
} else {
p2
}
}
fn main() {
let p1: Point = Point(10, 10);
let p2: Point = Point(20, 20);
let p3 = left_most(&p1, &p2); // каково время жизни `p3`?
println!("p3: {p3:?}");
}
В примере компилятор не может самостоятельно определить время жизни p3. Ему требуется наша помощь:
fn left_most<'a>(p1: &'a Point, p2: &'a Point) -> &'a Point { .. }
Возвращаемое значение должно жить как минимум также долго, как передаваемые аргументы.
В обычных ситуациях явные аннотации времен жизни не требуются.
Времена жизни в функциях
Времена жизни параметров функции и возвращаемого функцией значения должны быть полностью определены, но в ряде случаев Rust позволяет опустить (elide) аннотации времен жизни. На этот счет существует несколько простых правил:
- каждому аргументу присваивается аннотация времени жизни при отсутствии
- если функция принимает только один параметр, его время жизни становится временем жизни возвращаемого функцией значения
- если функция принимает несколько параметров, но первым параметром является
self, время жизниselfстановится временем жизни возвращаемого функцией значения
#[derive(Debug)]
struct Point(i32, i32);
fn cab_distance(p1: &Point, p2: &Point) -> i32 {
(p1.0 - p2.0).abs() + (p1.1 - p2.1).abs()
}
fn nearest<'a>(points: &'a [Point], query: &Point) -> Option<&'a Point> {
let mut nearest = None;
for p in points {
if let Some((_, nearest_dist)) = nearest {
let dist = cab_distance(p, query);
if dist < nearest_dist {
nearest = Some((p, dist));
}
} else {
nearest = Some((p, cab_distance(p, query)));
};
}
nearest.map(|(p, _)| p)
}
fn main() {
println!(
"{:?}",
nearest(
&[Point(1, 0), Point(1, 0), Point(-1, 0), Point(0, -1),],
&Point(0, 2)
)
);
}
Функция cab_distance не требует явных аннотаций времен жизни, поскольку p1 и p2 имеют одинаковый тип.
Параметры функции nearest имеют разные типы, поэтому функция требует явных аннотаций времен жизни. Попробуйте переписать ее сигнатуру следующим образом:
fn nearest<'a, 'q'>(points: &'a [Point], query: &'q Point) -> Option<&'q Point> { .. }
Такой код не компилируется. Это доказывает, что аннотации проверяются компилятором на корректность.
В большинстве случаев автоматический вывод аннотаций и типов означают, что их не нужно указывать явно. В более сложных ситуациях аннотации времени жизни могут помочь устранить неоднозначность. Часто, особенно при создании прототипов, проще работать с собственными данными, клонируя значения там, где это необходимо.
Времена жизни в структурах
Если структура хранит заимствованные данные, она должна быть аннотирована временем жизни:
#[derive(Debug)]
struct Highlight<'doc>(&'doc str);
fn erase(text: String) {
println!("Bye {text}!");
}
fn main() {
let text = String::from("The quick brown fox jumps over the lazy dog.");
let fox = Highlight(&text[4..19]);
let dog = Highlight(&text[35..43]);
// erase(text);
println!("{fox:?}");
println!("{dog:?}");
}
- аннотация
Highlightобеспечивает, чтобы данные, хранящиеся в&str, существовали по крайней мере также долго, как любой экземплярHighlight, использующий эти данные - если
textбудет потреблен до окончания жизниfox(илиdog), контроллер заимствований выбросит ошибку - типы с заимствованными данными вынуждают пользователей сохранять исходные данные. Это может быть полезно для создания упрощенных представлений (lightweight views), но обычно это несколько усложняет их использование
- по возможности делайте так, чтобы структуры владели своими данными
- некоторые структуры с несколькими ссылками внутри могут иметь более одной аннотации времени жизни. Это может быть необходимо, если помимо времени жизни самой структуры, необходимо описать отношения между временами жизни самих ссылок. Это очень продвинутые варианты использования
Упражнение: анализ Protobuf
В этом упражнении вы создадите анализатор двоичной кодировки protobuf. Не волнуйтесь, это проще, чем кажется! Упражнение иллюстрирует общий шаблон парсинга данных, разделенных на фрагменты (срезы). Исходные данные никогда не копируются.
Полный анализ сообщения protobuf требует знания типов полей, индексированных по номерам полей. Обычно это описывается в файле proto. В этом упражнении мы закодируем эту информацию в операторы сопоставления в функциях, которые вызываются для каждого поля.
Мы будем использовать следующий прототип:
message PhoneNumber {
optional string number = 1;
optional string type = 2;
}
message Person {
optional string name = 1;
optional int32 id = 2;
repeated PhoneNumber phones = 3;
}
Протосообщение кодируется как серия полей, идущих одно за другим. Каждый из них реализован как "тег", за которым следует значение. Тег содержит номер поля (например, 2 для поля id сообщения Person) и тип поля, определяющий, как полезная нагрузка должна извлекаться из потока байтов.
Целые числа, включая тег, представлены с помощью кодировки переменной длины, называемой VARINT. Функция parse_varint уже определена в коде. Также определены коллбеки для обработки полей Person и PhoneNumber и для парсинга сообщения в виде серии вызовов этих коллбеков.
Вам осталось реализовать функцию parse_field и трейт ProtoMessage для Person и PhoneNumber.
Обратите внимание: это упражнения является сложным и опциональным. Это означает, что на данном этапе освоения Rust вы можете его пропустить и вернуться к нему позже.
use std::convert::TryFrom;
use thiserror::Error;
#[derive(Debug, Error)]
enum Error {
#[error("Invalid varint")]
InvalidVarint,
#[error("Invalid wire-type")]
InvalidWireType,
#[error("Unexpected EOF")]
UnexpectedEOF,
#[error("Invalid length")]
InvalidSize(#[from] std::num::TryFromIntError),
#[error("Unexpected wire-type)")]
UnexpectedWireType,
#[error("Invalid string (not UTF-8)")]
InvalidString,
}
// Тип поля
enum WireType {
// Тип Varint указывает, что значение является единичным `VARINT`
Varint,
// Тип `Len` указывает, что значение - это длина, представленная как
// `VARINT`, точно следующий за этим количеством байтов
Len,
// Тип `I32` указывает, что значение - это точно 4 байта в прямом порядке (little-endian order),
// содержащие 32-битное целое число со знаком
I32,
// Тип `I64` для этого упражнения не нужен
}
#[derive(Debug)]
// Значение поля, типизированное на основе типа поля
enum FieldValue<'a> {
Varint(u64),
// `I64(i64)` для этого упражнения не нужен
Len(&'a [u8]),
I32(i32),
}
#[derive(Debug)]
// Поле, содержащее номер поля и его значение
struct Field<'a> {
field_num: u64,
value: FieldValue<'a>,
}
trait ProtoMessage<'a>: Default + 'a {
fn add_field(&mut self, field: Field<'a>) -> Result<(), Error>;
}
impl TryFrom<u64> for WireType {
type Error = Error;
fn try_from(value: u64) -> Result<WireType, Error> {
Ok(match value {
0 => WireType::Varint,
// `1 => WireType::I64` для этого упражнения не нужен
2 => WireType::Len,
5 => WireType::I32,
_ => return Err(Error::InvalidWireType),
})
}
}
impl<'a> FieldValue<'a> {
fn as_string(&self) -> Result<&'a str, Error> {
let FieldValue::Len(data) = self else {
return Err(Error::UnexpectedWireType);
};
std::str::from_utf8(data).map_err(|_| Error::InvalidString)
}
fn as_bytes(&self) -> Result<&'a [u8], Error> {
let FieldValue::Len(data) = self else {
return Err(Error::UnexpectedWireType);
};
Ok(data)
}
fn as_u64(&self) -> Result<u64, Error> {
let FieldValue::Varint(value) = self else {
return Err(Error::UnexpectedWireType);
};
Ok(*value)
}
}
// Функция разбора VARINT, возвращающая разобранное значение и оставшиеся байты
fn parse_varint(data: &[u8]) -> Result<(u64, &[u8]), Error> {
for i in 0..7 {
let Some(b) = data.get(i) else {
return Err(Error::InvalidVarint);
};
if b & 0x80 == 0 {
// Это последний байт `VARINT`, преобразуем его
// в `u64` и возвращаем
let mut value = 0u64;
for b in data[..=i].iter().rev() {
value = (value << 7) | (b & 0x7f) as u64;
}
return Ok((value, &data[i + 1..]));
}
}
// Если байтов больше 7, значит `VARINT` не является валидным
Err(Error::InvalidVarint)
}
// Функция преобразования тега в номер поля и тип поля
fn unpack_tag(tag: u64) -> Result<(u64, WireType), Error> {
let field_num = tag >> 3;
let wire_type = WireType::try_from(tag & 0x7)?;
Ok((field_num, wire_type))
}
// Функция разбора поля, возвращающая оставшиеся байты
fn parse_field(data: &[u8]) -> Result<(Field, &[u8]), Error> {
let (tag, remainder) = parse_varint(data)?;
let (field_num, wire_type) = unpack_tag(tag)?;
let (fieldvalue, remainder) = match wire_type {
_ => todo!("На основе типа поля создаем поле, употребив столько байтов, сколько необходимо")
};
todo!("Возвращаем поле и оставшиеся байты")
}
// Функция разбора сообщения в определенные данные, вызывающая `T::add_field` для каждого поля.
// Все входные данные потребляются
fn parse_message<'a, T: ProtoMessage<'a>>(mut data: &'a [u8]) -> Result<T, Error> {
let mut result = T::default();
while !data.is_empty() {
let parsed = parse_field(data)?;
result.add_field(parsed.0)?;
data = parsed.1;
}
Ok(result)
}
#[derive(Debug, Default)]
struct PhoneNumber<'a> {
number: &'a str,
type_: &'a str,
}
#[derive(Debug, Default)]
struct Person<'a> {
name: &'a str,
id: u64,
phone: Vec<PhoneNumber<'a>>,
}
impl<'a> ProtoMessage<'a> for Person<'a> {
fn add_field(&mut self, field: Field<'a>) -> Result<(), Error> {
todo!("реализуй меня")
}
}
impl<'a> ProtoMessage<'a> for PhoneNumber<'a> {
fn add_field(&mut self, field: Field<'a>) -> Result<(), Error> {
todo!("реализуй меня")
}
}
fn main() {
let person: Person = parse_message(&[
0x0a, 0x07, 0x6d, 0x61, 0x78, 0x77, 0x65, 0x6c, 0x6c, 0x10, 0x2a, 0x1a,
0x16, 0x0a, 0x0e, 0x2b, 0x31, 0x32, 0x30, 0x32, 0x2d, 0x35, 0x35, 0x35,
0x2d, 0x31, 0x32, 0x31, 0x32, 0x12, 0x04, 0x68, 0x6f, 0x6d, 0x65, 0x1a,
0x18, 0x0a, 0x0e, 0x2b, 0x31, 0x38, 0x30, 0x30, 0x2d, 0x38, 0x36, 0x37,
0x2d, 0x35, 0x33, 0x30, 0x38, 0x12, 0x06, 0x6d, 0x6f, 0x62, 0x69, 0x6c,
0x65,
])
.unwrap();
println!("{:#?}", person);
}
#[cfg(test)]
mod test {
use super::*;
#[test]
fn as_string() {
assert!(FieldValue::Varint(10).as_string().is_err());
assert!(FieldValue::I32(10).as_string().is_err());
assert_eq!(FieldValue::Len(b"hello").as_string().unwrap(), "hello");
}
#[test]
fn as_bytes() {
assert!(FieldValue::Varint(10).as_bytes().is_err());
assert!(FieldValue::I32(10).as_bytes().is_err());
assert_eq!(FieldValue::Len(b"hello").as_bytes().unwrap(), b"hello");
}
#[test]
fn as_u64() {
assert_eq!(FieldValue::Varint(10).as_u64().unwrap(), 10u64);
assert!(FieldValue::I32(10).as_u64().is_err());
assert!(FieldValue::Len(b"hello").as_u64().is_err());
}
}
Решение:
Итераторы
Iterator
Трейт Iterator позволяет перебирать значения коллекции. Он требует реализации метода next и предоставляет большое количество полезных методов. Многие типы стандартной библиотеки реализуют Iterator, и мы также можем его реализовывать на собственных типах:
struct Fibonacci {
curr: u32,
next: u32,
}
impl Iterator for Fibonacci {
type Item = u32;
fn next(&mut self) -> Option<Self::Item> {
let new_next = self.curr + self.next;
self.curr = self.next;
self.next = new_next;
Some(self.curr)
}
}
fn main() {
let fib = Fibonacci { curr: 0, next: 1 };
for (i, n) in fib.enumerate().take(5) {
println!("fib({i}): {n}");
}
}
Ремарки:
- трейт
Iteratorреализует много популярных операций функционального программирования над коллекциями (map,filter,reduceи т.д.). ВRustэти функции должны создавать код, столь же эффективный, как и эквивалентные императивные реализации IntoIterator- это трейт, обеспечивающий работу циклаfor. Он реализуется типами коллекций, такими какVec<T>, и ссылками на них, такими как&Vec<T>и&[T]. Диапазоны (ranges) также реализуют этот трейт. Вот почему мы можем перебирать элементы вектора с помощьюfor i in some_vec { .. }, ноsome_vec.next()отсутствует
IntoIterator
Трейт Iterator сообщает, как выполнять итерацию после создания итератора. Трейт IntoIterator определяет, как создать итератор для типа. Он автоматически используется циклом for.
struct Grid {
x_coords: Vec<u32>,
y_coords: Vec<u32>,
}
impl IntoIterator for Grid {
type Item = (u32, u32);
type IntoIter = GridIter;
fn into_iter(self) -> GridIter {
GridIter { grid: self, i: 0, j: 0 }
}
}
struct GridIter {
grid: Grid,
i: usize,
j: usize,
}
impl Iterator for GridIter {
type Item = (u32, u32);
fn next(&mut self) -> Option<(u32, u32)> {
if self.i >= self.grid.x_coords.len() {
self.i = 0;
self.j += 1;
if self.j >= self.grid.y_coords.len() {
return None;
}
}
let res = Some((self.grid.x_coords[self.i], self.grid.y_coords[self.j]));
self.i += 1;
res
}
}
fn main() {
let grid = Grid { x_coords: vec![3, 5, 7, 9], y_coords: vec![10, 20, 30, 40] };
for (x, y) in grid {
println!("point = {x}, {y}");
}
}
Каждая реализация IntoIterator должна определять 2 типа:
Item- перебираемый тип, такой какi8IntoIter- типIterator, возвращаемый методомinto_iter
Обратите внимание, что IntoIter и Iter связаны: итератор должен иметь такой же тип Item. Это означает, что он должен возвращать Option<Type>.
В примере перебираются все комбинации координат x и y.
Обратите внимание, что IntoIterator::into_iter принимает владение (ownership) над self. Попробуйте дважды перебрать grid в функции main.
Решите эту проблему путем реализации IntoIterator для &Grid и сохранения ссылки на Grid в GridIter.
Аналогичная проблема может возникнуть при использовании стандартных типов: for e in some_vec принимает владение над some_vec и перебирает собственные элементы вектора. Для перебора ссылок на элементы вектора следует использовать for e in &some_vec.
FromIterator
Трейт FromIterator позволяет создавать коллекции из Iterator:
fn main() {
let primes = vec![2, 3, 5, 7];
let prime_squares = primes.into_iter().map(|p| p * p).collect::<Vec<_>>();
println!("prime_squares: {prime_squares:?}");
}
Iterator реализует
fn collect<B>(self) -> B
where
B: FromIterator<Self::Item>,
Self: Sized
Существует 2 способа определить B для этого метода:
- с помощью turbofish:
some_iterator.collect::<COLLECTION_TYPE>(), как показано в примере. Сокращение_позволяетRustвывести тип элементов вектора самостоятельно - с помощью вывода типов:
let prime_squares: Vec<_> = some_iterator.collect()
Базовые реализации IntoIterator существуют для Vec, HashMap и некоторых других типов. Существуют также более специализированные реализации, позволяющие делать клевые вещи, вроде преобразования Iterator<Item = Result<V, E>> в Result<Vec<V>, E>
Упражнение: цепочка методов итератора
В этом упражнении вам нужно найти и использовать некоторые методы трейта Iterator для реализации сложных вычислений.
Используйте выражение итератора и соберите (collect) результат для построения возвращаемого значения.
// Функция для вычисления разницы между элементами `values`, смещенными на `offset`.
// `values` перебираются по кругу.
//
// Элемент `n` результата - `values[(n+offset)%len] - values[n]`.
fn offset_differences<N>(offset: usize, values: Vec<N>) -> Vec<N>
where
N: Copy + std::ops::Sub<Output = N>,
{
todo!("реализуй меня")
}
fn main() {
let res = offset_differences(1, vec![1, 3, 5, 7]);
println!("{:?}", res);
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_offset_one() {
assert_eq!(offset_differences(1, vec![1, 3, 5, 7]), vec![2, 2, 2, -6]);
assert_eq!(offset_differences(1, vec![1, 3, 5]), vec![2, 2, -4]);
assert_eq!(offset_differences(1, vec![1, 3]), vec![2, -2]);
}
#[test]
fn test_larger_offsets() {
assert_eq!(offset_differences(2, vec![1, 3, 5, 7]), vec![4, 4, -4, -4]);
assert_eq!(offset_differences(3, vec![1, 3, 5, 7]), vec![6, -2, -2, -2]);
assert_eq!(offset_differences(4, vec![1, 3, 5, 7]), vec![0, 0, 0, 0]);
assert_eq!(offset_differences(5, vec![1, 3, 5, 7]), vec![2, 2, 2, -6]);
}
#[test]
fn test_custom_type() {
assert_eq!(
offset_differences(1, vec![1.0, 11.0, 5.0, 0.0]),
vec![10.0, -6.0, -5.0, 1.0]
);
}
#[test]
fn test_degenerate_cases() {
assert_eq!(offset_differences(1, vec![0]), vec![0]);
assert_eq!(offset_differences(1, vec![1]), vec![0]);
let empty: Vec<i32> = vec![];
assert_eq!(offset_differences(1, empty), vec![]);
}
}
Решение:
Модули
Модули
Мы видели, как блоки impl позволяют нам использовать функции пространства имен (namespace) для типа.
Аналогично, mod позволяет нам использовать типы и функции пространства имен:
mod foo {
pub fn do_something() {
println!("в модуле foo");
}
}
mod bar {
pub fn do_something() {
println!("в модуле bar");
}
}
fn main() {
foo::do_something();
bar::do_something();
}
Ремарки:
- пакеты (packages) предоставляют функционал и включают файл
Cargo.toml, описывающий сборку из нескольких крейтов - крейты (crates) - это дерево модулей, где бинарный крейт является исполняемым файлом, а библиотечный крейт компилируется в библиотеку
- модули определяют организацию и область видимости кода
Иерархия файловой системы
Если опустить содержимое модуля, Rust будет искать его в другом файле:
mod garden;
Это сообщает Rust, что содержимое модуля Garden находится по адресу src/garden.rs. Аналогично, модуль Garden::vegetables следует искать по адресу src/garden/vegetables.rs.
Корневой crate находится в:
src/lib.rs(для библиотечного крейта)src/main.rs(для бинарного крейта)
Модули, определенные в файлах, можно документировать с помощью "внутренних комментариев документа". Они документируют элемент, который их содержит - в данном случае модуль.
//! This module implements the garden, including a highly performant germination
//! implementation.
// Re-export types from this module.
pub use garden::Garden;
pub use seeds::SeedPacket;
/// Sow the given seed packets.
pub fn sow(seeds: Vec<SeedPacket>) {
todo!()
}
/// Harvest the produce in the garden that is ready.
pub fn harvest(garden: &mut Garden) {
todo!()
}
Ремарки:
- до
Rust 2018модули должны были находиться вmodule/mod.rsвместоmodule.rs, и это по-прежнему работает - основная причина представления
filename.rsв качестве альтернативыfilename/mod.rsзаключается в том, что при большом количестве файловmod.rsстановится сложно в них разбираться - при более глубокой вложенности можно использовать директории, даже если основной модуль является файлом:
src/
├── main.rs
├── top_module.rs
└── top_module/
└── sub_module.rs
- место поиска модулей может быть изменено с помощью директивы компилятора:
#[path = "some/path.rs"]
mod some_module;
Это может быть полезным, например, когда мы хотим поместить тесты для модуля в файл с именем some_module_test.rs.
Видимость
Модули являются приватными/закрытыми:
- элементы модулей являются приватными по умолчанию (скрывают детали своей реализации)
- родители и сиблинги всегда являются видимыми (для элементов модулей)
- если элемент видим в модуле
foo, он видим всем потомкамfoo
mod outer {
fn private() {
println!("outer::private");
}
pub fn public() {
println!("outer::public");
}
mod inner {
fn private() {
println!("outer::inner::private");
}
pub fn public() {
println!("outer::inner::public");
super::private();
}
}
}
fn main() {
outer::public();
}
Ремарки:
- для того, чтобы сделать модуль публичным/открытым, используется ключевое слово
pub - существуют продвинутые спецификаторы
pub, позволяющие ограничивать область публичной видимости
use, super, self
Модуль может импортировать элементы другого модуля в свою область видимости с помощью ключевого слова use. В начале каждого модуля можно увидеть что-то вроде этого:
use std::collections::HashSet;
use std::process::abort;
Пути
Путь (path) разрешается следующим образом:
- Как относительный путь:
fooилиself::fooссылается наfooв текущем модулеsuper::fooссылается наfooв родительском модуле
- Как абсолютный путь:
crate:fooссылается наfooв корне текущего крейтаbar::fooссылается наfooв крейтеbar
Ремарки:
- распространенной практикой является повторный экспорт элементов модулей. Например, корневой файл
lib.rsможет содержать:
mod storage;
pub use storage::disk::DiskStorage;
pub use storage::network::NetworkStorage;
Это сделает DiskStorage и NetworkStorage доступными другим крейтам по короткому пути.
- в основном, необходимо
use(использовать) только элементы, которые используются в модуле. Однако для того, чтобы вызывать методы трейта, он должен находиться в области видимости, даже если тип, реализующий этот трейт, уже находится в ней. Например, чтобы использовать методread_to_stringдля типа, реализующего трейтRead, необходимоuse std::io::Read - в операторе
useможет использоваться подстановочный знак:use std::io::*. Делать так не рекомендуется, поскольку неясно, какие элементы импортируются, и эти элементы могут измениться со временем
Упражнение: модули для библиотеки пользовательского интерфейса
В этом упражнении вы реорганизуете код "Библиотеки графического интерфейса" из раздела "Методы и трейты" в набор модулей. Обычно каждый тип или набор тесно связанных типов помещают в отдельный модуль, поэтому каждый тип виджета должен иметь свой собственный модуль.
Код:
pub trait Widget {
fn width(&self) -> usize;
fn draw_into(&self, buffer: &mut dyn std::fmt::Write);
fn draw(&self) {
let mut buffer = String::new();
self.draw_into(&mut buffer);
println!("{buffer}");
}
}
pub struct Label {
label: String,
}
impl Label {
fn new(label: &str) -> Label {
Label { label: label.to_owned() }
}
}
pub struct Button {
label: Label,
}
impl Button {
fn new(label: &str) -> Button {
Button { label: Label::new(label) }
}
}
pub struct Window {
title: String,
widgets: Vec<Box<dyn Widget>>,
}
impl Window {
fn new(title: &str) -> Window {
Window { title: title.to_owned(), widgets: Vec::new() }
}
fn add_widget(&mut self, widget: Box<dyn Widget>) {
self.widgets.push(widget);
}
fn inner_width(&self) -> usize {
std::cmp::max(
self.title.chars().count(),
self.widgets.iter().map(|w| w.width()).max().unwrap_or(0),
)
}
}
impl Widget for Window {
fn width(&self) -> usize {
self.inner_width() + 4
}
fn draw_into(&self, buffer: &mut dyn std::fmt::Write) {
let mut inner = String::new();
for widget in &self.widgets {
widget.draw_into(&mut inner);
}
let inner_width = self.inner_width();
writeln!(buffer, "+-{:-<inner_width$}-+", "").unwrap();
writeln!(buffer, "| {:^inner_width$} |", &self.title).unwrap();
writeln!(buffer, "+={:=<inner_width$}=+", "").unwrap();
for line in inner.lines() {
writeln!(buffer, "| {:inner_width$} |", line).unwrap();
}
writeln!(buffer, "+-{:-<inner_width$}-+", "").unwrap();
}
}
impl Widget for Button {
fn width(&self) -> usize {
self.label.width() + 4
}
fn draw_into(&self, buffer: &mut dyn std::fmt::Write) {
let width = self.width();
let mut label = String::new();
self.label.draw_into(&mut label);
writeln!(buffer, "+{:-<width$}+", "").unwrap();
for line in label.lines() {
writeln!(buffer, "|{:^width$}|", &line).unwrap();
}
writeln!(buffer, "+{:-<width$}+", "").unwrap();
}
}
impl Widget for Label {
fn width(&self) -> usize {
self.label.lines().map(|line| line.chars().count()).max().unwrap_or(0)
}
fn draw_into(&self, buffer: &mut dyn std::fmt::Write) {
writeln!(buffer, "{}", &self.label).unwrap();
}
}
fn main() {
let mut window = Window::new("Rust GUI Demo 1.23");
window.add_widget(Box::new(Label::new("This is a small text GUI demo.")));
window.add_widget(Box::new(Button::new("Click me!")));
window.draw();
}
Упражнение можно начать с выполнения следующих команд:
cargo init gui-modules
cd gui-modules
cargo run
Отредактируйте файл src/main.rs, добавив в него инструкции mod, и создайте необходимые файлы в директории src.
Решение:
Тестирование
Модульные/юнит-тесты
Rust и Cargo поставляются с фреймворком для тестирования:
- модульные (unit) тесты поддерживаются прямо в коде, который мы пишем
- интеграционные (integration) тесты поддерживаются через директорию
tests
Тесты помечаются с помощью директивы #[test]. Юнит-тесты часто помещаются во вложенный модуль tests. Директива #[cfg(test)] сообщает компилятору, что содержащийся далее код следует компилировать только при запуске тестов:
fn first_word(text: &str) -> &str {
match text.find(' ') {
Some(idx) => &text[..idx],
None => &text,
}
}
#[cfg(test)]
mod test {
use super::*;
#[test]
fn test_empty() {
assert_eq!(first_word(""), "");
}
#[test]
fn test_single_word() {
assert_eq!(first_word("Hello"), "Hello");
}
#[test]
fn test_multiple_words() {
assert_eq!(first_word("Hello World"), "Hello");
}
}
- Модульные тесты позволяют тестировать приватный функционал
- атрибут
#[cfg(test)]активируется только при выполненииcargo test
Другие типы тестов
Интеграционные тесты
Интеграционные тесты используются для тестирования библиотеки от лица клиента.
Создаем файл .rs в директории tests/:
// tests/my_library.rs
use my_library::init;
#[test]
fn test_init() {
assert!(init().is_ok());
}
Эти тесты имеют доступ только к публичному API тестируемого крейта.
Документационные тесты
Rust имеет встроенную поддержку документационных тестов:
/// Сокращает строку до указанной длины.
///
/// ```
/// # use playground::shorten_string;
/// assert_eq!(shorten_string("Hello World", 5), "Hello");
/// assert_eq!(shorten_string("Hello World", 20), "Hello World");
/// ```
pub fn shorten_string(s: &str, length: usize) -> &str {
&s[..std::cmp::min(length, s.len())]
}
- Блоки кода в комментариях
///считаются валидным кодомRust(разумеется, если код компилируется) - код будет скомпилирован и выполнен как часть
cargo test - добавление
#в код скроет его из документации, но он по-прежнему будет компилироваться/выполняться
Полезные крейты
Rust предоставляет лишь базовую поддержку тестов.
Вот несколько крейтов, которые могут пригодиться для тестирования:
- googletest - комплексная библиотека тестирования в лучших традициях
GoogleTestдляC++ - proptest - библиотека тестирования на основе свойств (properties)
- rstest - библиотека тестирования, поддерживающая фикстуры (fixtures) и параметризованные тесты
GoogleTest
Крейт googletest позволяет создавать гибкие тесты с использованием сопоставителей (matchers):
use googletest::prelude::*;
#[googletest::test]
fn test_elements_are() {
let value = vec!["foo", "bar", "baz"];
expect_that!(value, elements_are!(eq("foo"), lt("xyz"), starts_with("b")));
}
Если мы изменим b на ! в последнем элементе, тест провалится с выдачей структурированного сообщения об ошибке:
---- test_elements_are stdout ----
Value of: value
Expected: has elements:
0. is equal to "foo"
1. is less than "xyz"
2. starts with prefix "!"
Actual: ["foo", "bar", "baz"],
where element #2 is "baz", which does not start with "!"
at src/testing/googletest.rs:6:5
Error: See failure output above
Ремарки:
- выполните
cargo add googletestдля установкиgoogletest use googletest::prelude::*;импортирует некоторые часто используемые макросы и типыgoogletestпредоставляет большое количество сопоставителей- приятной особенностью
googletestявляется то, что несоответствия в многострочных строках отображаются в виде разницы:
#[test]
fn test_multiline_string_diff() {
let haiku = "Memory safety found,\n\
Rust's strong typing guides the way,\n\
Secure code you'll write.";
assert_that!(
haiku,
eq("Memory safety found,\n\
Rust's silly humor guides the way,\n\
Secure code you'll write.")
);
}
Вывод будет цветным:
Value of: haiku
Expected: is equal to "Memory safety found,\nRust's silly humor guides the way,\nSecure code you'll write."
Actual: "Memory safety found,\nRust's strong typing guides the way,\nSecure code you'll write.",
which isn't equal to "Memory safety found,\nRust's silly humor guides the way,\nSecure code you'll write."
Difference(-actual / +expected):
Memory safety found,
-Rust's strong typing guides the way,
+Rust's silly humor guides the way,
Secure code you'll write.
at src/testing/googletest.rs:17:5=
Мокинг
Для мокинга (mocking - создание макета) широко используется библиотека mockall:
use std::time::Duration;
#[mockall::automock]
pub trait Pet {
fn is_hungry(&self, since_last_meal: Duration) -> bool;
}
#[test]
fn test_robot_dog() {
let mut mock_dog = MockPet::new();
mock_dog.expect_is_hungry().return_const(true);
assert_eq!(mock_dog.is_hungry(Duration::from_secs(10)), true);
}
Ремарки:
- для установки
mockallвыполните командуcargo add mockall - на crates.io доступны и другие библиотеки для мокинга, в частности, для мокинга HTTP-сервисов. Другие библиотеки работают аналогично
Mockall: они позволяют легко получить макет реализации определенного трейта - обратите внимание, что использование макетов несколько противоречиво: макеты позволяют полностью изолировать тест от его зависимостей. Непосредственным результатом является более быстрое и стабильное выполнение тестов. С другой стороны, макеты могут быть настроены неправильно и возвращать данные, отличные от того, что делали бы реальные зависимости. По-возможности следует использовать реальные зависимости. Например, многие базы данных позволяют настроить серверную часть в памяти (in-memory backend). Это означает, что мы получаем правильное поведение тестов, плюс они работают быстро и автоматически очищаются. Многие веб-фреймворки позволяют запускать внутрипроцессный сервер, который привязывается к произвольному порту на локальном хосте. Этот подход является более предпочтительным, чем мокинг, поскольку позволяет тестировать код в реальной среде
Mockallпредоставляет много полезных функций. В частности, мы можем настроить ожидания (expectations), которые зависят от переданных аргументов. Здесь мы используем это, чтобы создать макет кошки, которая проголодалась через 3 часа после того, как ее в последний раз покормили:
#[test]
fn test_robot_cat() {
let mut mock_cat = MockPet::new();
mock_cat
.expect_is_hungry()
.with(mockall::predicate::gt(Duration::from_secs(3 * 3600)))
.return_const(true);
mock_cat.expect_is_hungry().return_const(false);
assert_eq!(mock_cat.is_hungry(Duration::from_secs(1 * 3600)), false);
assert_eq!(mock_cat.is_hungry(Duration::from_secs(5 * 3600)), true);
}
- мы можем использовать
.times(n), чтобы ограничить количество вызовов фиктивного метода доn- при превышении этого лимита программа запаникует
Линтер и Clippy
Компилятор Rust выдает фантастические сообщения об ошибках, а также полезные подсказки (lints). Clippy предоставляет еще больше подсказок, организованных в группы, которые можно включать/выключать для каждого проекта.
#[deny(clippy::cast_possible_truncation)]
fn main() {
let x = 3;
while (x < 70000) {
x *= 2;
}
println!("X помещается в u16, верно? {}", x as u16);
}
Упражнение: алгоритм Луна
Алгоритм Луна используется для проверки номеров кредитных карт. Алгоритм принимает строку на вход и выполняет следующие действия:
- игнорируем все пробелы
- отклоняем номера, содержащие менее двух цифр
- двигаясь справа налево, удваиваем каждую вторую цифру: для числа 1234 удваиваем 3 и 1, для числа 98765 удваиваем 6 и 8
- после удвоения цифры суммируем цифры, если результат больше 9. Таким образом, удвоение 7 дает 14, что дает 1 + 4 = 5
- суммируем все неудвоенные и удвоенные цифры
- номер кредитной карты действителен, если сумма заканчивается на 0
Приведенный код содержит ошибочную реализацию алгоритма Луна, а также два модульных теста, которые подтверждают, что большая часть алгоритма реализована правильно:
pub fn luhn(cc_number: &str) -> bool {
let mut sum = 0;
let mut double = false;
for c in cc_number.chars().rev() {
if let Some(digit) = c.to_digit(10) {
if double {
let double_digit = digit * 2;
sum +=
if double_digit > 9 { double_digit - 9 } else { double_digit };
} else {
sum += digit;
}
double = !double;
} else {
continue;
}
}
sum % 10 == 0
}
fn main() {
let cc_number = "1234 5678 1234 5670";
println!(
"{cc_number} является действительным номером кредитной карты? {}",
if luhn(cc_number) { "Да" } else { "Нет" }
);
}
#[cfg(test)]
mod test {
use super::*;
#[test]
fn test_valid_cc_number() {
assert!(luhn("4263 9826 4026 9299"));
assert!(luhn("4539 3195 0343 6467"));
assert!(luhn("7992 7398 713"));
}
#[test]
fn test_invalid_cc_number() {
assert!(!luhn("4223 9826 4026 9299"));
assert!(!luhn("4539 3195 0343 6476"));
assert!(!luhn("8273 1232 7352 0569"));
}
#[test]
fn test_non_digit_cc_number() {
assert!(!luhn("foo"));
assert!(!luhn("foo 0 0"));
}
#[test]
fn test_empty_cc_number() {
assert!(!luhn(""));
assert!(!luhn(" "));
assert!(!luhn(" "));
assert!(!luhn(" "));
}
#[test]
fn test_single_digit_cc_number() {
assert!(!luhn("0"));
}
#[test]
fn test_two_digit_cc_number() {
assert!(luhn(" 0 0 "));
}
}
Решение:
Обработка ошибок
Паника
Фатальные ошибки обрабатываются в Rust с помощью "паники" (panic).
Паника происходит при возникновении фатальной ошибки во время выполнения:
fn main() {
let v = vec![10, 20, 30];
println!("v[100]: {}", v[100]);
}
Ремарки:
- паника связана с неисправимыми и неожиданными ошибками:
- паника - это симптомы ошибок в программе
- сбои во время выполнения, такие как неудачная проверка границ (boundaries), могут вызвать панику
- утверждения (например,
assert!) паникуют при неудаче - для целенаправленной паники можно использовать макрос
panic!
- паника "разматывает" (unwind) стек, сбрасывая значения так же, как если бы функции вернули значения
- в примере для безопасного доступа к элементу вектора по индексу можно использовать
Vec::get
По умолчанию паника разматывает стек. Разматывание может быть перехвачено:
use std::panic;
fn main() {
let result = panic::catch_unwind(|| "No problem here!");
println!("{result:?}");
let result = panic::catch_unwind(|| {
panic!("Oh no!");
});
println!("{result:?}");
}
- Не пытайтесь реализовать исключения с помощью
catch_unwind - это может быть полезно на серверах, которые должны продолжать работать даже в случае сбоя одного запроса
- это не работает при установке
panic = 'abort'вCargo.toml
Оператор ?
Ошибки времени выполнения, такие как отказ в соединении или отсутствие файла, обрабатываются с помощью типа Result, но сопоставление (matching) этого типа при каждом вызове может быть утомительным и излишним. Оператор ? используется для возврата ошибок вызывающему (caller). Он позволяет заменить
match some_expression {
Ok(value) => value,
Err(err) => return Err(err),
}
на
some_expression?
Попробуйте упростить обработку ошибок в следующем коде:
use std::io::Read;
use std::{fs, io};
fn read_username(path: &str) -> Result<String, io::Error> {
let username_file_result = fs::File::open(path);
let mut username_file = match username_file_result {
Ok(file) => file,
Err(err) => return Err(err),
};
let mut username = String::new();
match username_file.read_to_string(&mut username) {
Ok(_) => Ok(username),
Err(err) => Err(err),
}
}
fn main() {
// fs::write("config.dat", "alice").unwrap();
let username = read_username("config.dat");
println!("username or error: {username:?}");
}
Подсказки:
- переменная
usernameможет быть либоOk(String), либоErr(error) - используйте
fs::writeдля тестирования разных случаев: отсутствие файла, пустой файл, файл с именем пользователя - обратите внимание, что
mainможет возвращатьResult<(), E>до тех пор, пока реализуетstd::process:Termination. На практике это означает, чтоEреализуетDebug. Исполняемый файл напечатает вариантErrи вернет ненулевой статус выхода в случае ошибки
Преобразования Try
Оператор ? работает немного сложнее, чем можно подумать.
Это:
expression?
Эквивалентно этому:
match expression {
Ok(value) => value,
Err(err) => return Err(From::from(err)),
}
Вызов From::from здесь означает, что мы пытаемся преобразовать тип ошибки в тип, возвращаемый функцией. Это позволяет легко преобразовать локальные ошибки в ошибки более высокого уровня.
Пример
use std::error::Error;
use std::fmt::{self, Display, Formatter};
use std::fs::File;
use std::io::{self, Read};
#[derive(Debug)]
enum ReadUsernameError {
IoError(io::Error),
EmptyUsername(String),
}
impl Error for ReadUsernameError {}
impl Display for ReadUsernameError {
fn fmt(&self, f: &mut Formatter) -> fmt::Result {
match self {
Self::IoError(e) => write!(f, "Ошибка ввода/вывода: {e}"),
Self::EmptyUsername(path) => write!(f, "Имя пользователя отсутствует в {path}"),
}
}
}
impl From<io::Error> for ReadUsernameError {
fn from(err: io::Error) -> Self {
Self::IoError(err)
}
}
fn read_username(path: &str) -> Result<String, ReadUsernameError> {
let mut username = String::with_capacity(100);
File::open(path)?.read_to_string(&mut username)?;
if username.is_empty() {
return Err(ReadUsernameError::EmptyUsername(String::from(path)));
}
Ok(username)
}
fn main() {
// fs::write("config.dat", "").unwrap();
let username = read_username("config.dat");
println!("Имя пользователя или ошибка: {username:?}");
}
Оператор ? должен возвращать значение, совместимое с типом значения, возвращаемого функцией. Для Result это означает, что типы ошибок должны быть совместимыми. Функция, возвращающая Result<T, ErrorOuter>, может использовать ? только для значения типа Result<U, ErrorInner>, если ErrorOuter и ErrorInner имеют один и тот же тип, или если ErrorOuter реализует From<ErrorInner>.
Распространенной альтернативой реализации From является Result::map_err, особенно когда преобразование происходит только в одном месте.
Для Option нет требований совместимости. Функция, возвращающая Option<T>, может использовать оператор ? на Option<U> для произвольных типов T и U.
Функция, возвращающая Result, не может использовать ? на Option, и наоборот. Однако, Option::ok_or преобразует Option в Result, а Result::ok - Result в Option.
Динамические типы ошибок
Иногда мы хотим возвращать любой тип ошибки без создания перечисления, охватывающего все варианты. Трейт std::error::Error позволяет легко создать трейт-объект, который может содержать любую ошибку:
use std::error::Error;
use std::fs;
use std::io::Read;
fn read_count(path: &str) -> Result<i32, Box<dyn Error>> {
let mut count_str = String::new();
fs::File::open(path)?.read_to_string(&mut count_str)?;
let count: i32 = count_str.parse()?;
Ok(count)
}
fn main() {
fs::write("count.dat", "1i3").unwrap();
match read_count("count.dat") {
Ok(count) => println!("Содержимое: {count}"),
Err(err) => println!("Ошибка: {err}"),
}
}
Функция read_count может возвращать std::io::Error (из операций с файлом) или std::num::ParseIntError (из String::parse).
Использование динамических (boxing) ошибок сокращает количество кода, но лишает возможности по-разному обрабатывать разные ошибки. Поэтому использовать Box<dyn Error> в общедоступном API библиотеки не рекомендуется, но это может быть хорошим вариантом, когда мы просто хотим где-то отображать сообщение об ошибке.
При создании кастомных типов ошибок убедитесь, что они реализуют std::error::Error, чтобы их можно было оборачивать в Box.
thiserror и anyhow
Крейты thiserror и anyhow широко используются для упрощения обработки ошибок. thiserror помогает создавать кастомные типы ошибок, реализующие From<T>. anyhow помогает с обработкой ошибок в функциях, включая добавление контекстуальной информации в ошибки.
use anyhow::{bail, Context, Result};
use std::fs;
use std::io::Read;
use thiserror::Error;
#[derive(Clone, Debug, Eq, Error, PartialEq)]
#[error("Имя пользователя отсутствует в {0}")]
struct EmptyUsernameError(String);
fn read_username(path: &str) -> Result<String> {
let mut username = String::with_capacity(100);
fs::File::open(path)
.with_context(|| format!("Ошибка при открытии {path}"))?
.read_to_string(&mut username)
.context("Ошибка при чтении")?;
if username.is_empty() {
bail!(EmptyUsernameError(path.to_string()));
}
Ok(username)
}
fn main() {
// fs::write("config.dat", "").unwrap();
match read_username("config.dat") {
Ok(username) => println!("Имя пользователя: {username}"),
Err(err) => println!("Ошибка: {err:?}"),
}
}
thiserror:
- макрос
errorпредоставляетсяthiserrorи содержит большое количество атрибутов для лаконичного определения типов ошибок - трейт
std::error::Errorреализуется автоматически - сообщение из
#[error]используется для автоматической реализации трейтаDisplay
anyhow:
anyhow::Error- это обертка надBox<dyn Error>. Опять же это не лучший выбор для общедоступного API библиотеки, но он широко используется в приложенияхanyhow::Result<V>- это синоним типаResult<V, anyhow::Error>- при необходимости фактический тип ошибки внутри него можно извлечь для проверки
anyhow::Context- это трейт, реализованный для стандартных типовResultиOption.use anyhow::Contextнеобходим для включения.context()и.with_context()на этих типах
Упражнение: без паники
Следующий код реализует очень простой синтаксический анализатор языка выражений. Однако он обрабатывает ошибки путем паники. Перепишите его, чтобы вместо этого использовать идиоматическую обработку ошибок и распространять ошибки на возврат из main. Не стесняйтесь использовать thiserror и anyhow.
Подсказка: начните исправлять ошибки в функции parse. После того, как она заработает, обновите Tokenizer для реализации Iterator<Item=Result<Token, TokenizerError>> и обработайте его в парсере.
use std::iter::Peekable;
use std::str::Chars;
// Арифметический оператор
#[derive(Debug, PartialEq, Clone, Copy)]
enum Op {
Add,
Sub,
}
// Токен языка
#[derive(Debug, PartialEq)]
enum Token {
Number(String),
Identifier(String),
Operator(Op),
}
// Выражение языка
#[derive(Debug, PartialEq)]
enum Expression {
// Ссылка на переменную
Var(String),
// Литеральное число
Number(u32),
// Бинарная операция
Operation(Box<Expression>, Op, Box<Expression>),
}
fn tokenize(input: &str) -> Tokenizer {
return Tokenizer(input.chars().peekable());
}
struct Tokenizer<'a>(Peekable<Chars<'a>>);
impl<'a> Iterator for Tokenizer<'a> {
type Item = Token;
fn next(&mut self) -> Option<Token> {
let c = self.0.next()?;
match c {
'0'..='9' => {
let mut num = String::from(c);
while let Some(c @ '0'..='9') = self.0.peek() {
num.push(*c);
self.0.next();
}
Some(Token::Number(num))
}
'a'..='z' => {
let mut ident = String::from(c);
while let Some(c @ ('a'..='z' | '_' | '0'..='9')) = self.0.peek() {
ident.push(*c);
self.0.next();
}
Some(Token::Identifier(ident))
}
'+' => Some(Token::Operator(Op::Add)),
'-' => Some(Token::Operator(Op::Sub)),
_ => panic!("Неожиданный символ {c}"),
}
}
}
fn parse(input: &str) -> Expression {
let mut tokens = tokenize(input);
fn parse_expr<'a>(tokens: &mut Tokenizer<'a>) -> Expression {
let Some(tok) = tokens.next() else {
panic!("Неожиданный конец ввода");
};
let expr = match tok {
Token::Number(num) => {
let v = num.parse().expect("Невалидное 32-битное целое число");
Expression::Number(v)
}
Token::Identifier(ident) => Expression::Var(ident),
Token::Operator(_) => panic!("Неожиданный токен {tok:?}"),
};
// Проверяем наличие бинарной операции
match tokens.next() {
None => expr,
Some(Token::Operator(op)) => Expression::Operation(
Box::new(expr),
op,
Box::new(parse_expr(tokens)),
),
Some(tok) => panic!("Неожиданный токен {tok:?}"),
}
}
parse_expr(&mut tokens)
}
fn main() {
let expr = parse("10+foo+20-30");
println!("{expr:?}");
}
Решение:
Небезопасный Rust
Небезопасный Rust
Rust состоит из двух частей:
- безопасный
Rust- работа с памятью является безопасной, отсутствует неопределенное поведение - небезопасный
Rust- код может приводить к неопределенному поведению при нарушении определенных условий
В этом курсе мы видели в основном безопасный Rust, но важно понимать, что такое небезопасный Rust.
Небезопасный код обычно небольшой и изолированный, и его корректность должна быть тщательно документирована. Обычно он оборачивается в безопасный уровень абстракции (safe abstraction layer).
Небезопасный Rust предоставляет доступ к 5 новым возможностям:
- разыменование сырых указателей (raw pointers)
- доступ и модификация мутабельных статичных переменных
- доступ к полям
union - вызов
unsafeфункций, включаяextern(внешние) функции - реализация
unsafeтрейтов
Небезопасный Rust не означает, что код неправильный. Он означает, что разработчики отключили некоторые функции безопасности компилятора и им приходится писать правильный код самостоятельно. Это означает, что компилятор не обеспечивает соблюдение правил безопасности памяти Rust.
Разыменование сырых указателей
Создание указателей является безопасным, но их разыменование требует unsafe:
fn main() {
let mut s = String::from("careful!");
let r1 = &mut s as *mut String;
let r2 = r1 as *const String;
// Безопасно, поскольку r1 и r2 были получены из ссылок и поэтому
// гарантированно не равны нулю и правильно выровнены (properly aligned), объекты, лежащие в основе ссылок,
// из которых они были получены, активны на протяжении всего небезопасного блока,
// и к ним нельзя получить доступ ни через ссылки, ни (конкурентно) через другие указатели
unsafe {
println!("r1 is: {}", *r1);
*r1 = String::from("uhoh");
println!("r2 is: {}", *r2);
}
// Небезопасно. Не делайте так
/*
let r3: &String = unsafe { &*r1 };
drop(s);
println!("r3 is: {}", *r3);
*/
}
Хорошей практикой является написание комментария для каждого небезопасного блока, объясняющего, как код внутри него удовлетворяет требованиям безопасности выполняемых им небезопасных операций.
В случае разыменования указателей это означает, что указатели должны быть валидными, т.е.:
- указатель не должен равняться нулю
- указатель должен быть разыменовываемым (в пределах одного выделенного объекта)
- объект не должен быть освобожден
- не должно быть одновременного доступа к одной и той же локации памяти
- если указатель был получен путем приведения ссылки (reference coercion), базовый объект должен быть активным и никакая ссылка не может использоваться для доступа к памяти
В большинстве случаев указатель также должен быть правильно выровнен.
В разделе "Небезопасно" приведен пример распространенной ошибки неопределенного поведения: *r1 имеет 'static время жизни, поэтому r3 имеет тип &'static String и, таким образом, переживает s. Создание ссылки из указателя требует большой осторожности.
Модификация статичных переменных
Чтение иммутабельной статичной переменной является безопасным:
static HELLO_WORLD: &str = "Hello, world!";
fn main() {
println!("HELLO_WORLD: {HELLO_WORLD}");
}
Однако, учитывая риск возникновения гонки данных (data race), чтение и модификация мутабельных статичных переменных являются небезопасными:
static mut COUNTER: u32 = 0;
fn add_to_counter(inc: u32) {
unsafe {
COUNTER += inc;
}
}
fn main() {
add_to_counter(42);
unsafe {
println!("COUNTER: {COUNTER}");
}
}
Программа в примере безопасна, поскольку она однопоточная. Однако компилятор Rust консервативен и предполагает худшее. Попробуйте удалить unsafe и увидите предупреждение компилятора о том, что изменение статики из нескольких потоков может привести к неопределенному поведению.
Использование изменяемой статики, как правило, является плохой идеей, но в некоторых случаях это может иметь смысл в низкоуровневом коде no_std, например, при реализации распределителя кучи (heap allocator) или работе с некоторыми API языка C.
Объединения
Объединения (unions) похожи на перечисления, но активное поле нужно отслеживать самостоятельно:
#[repr(C)]
union MyUnion {
i: u8,
b: bool,
}
fn main() {
let u = MyUnion { i: 42 };
println!("int: {}", unsafe { u.i });
println!("bool: {}", unsafe { u.b }); // неопределенное поведение
}
В Rust объединения нужны очень редко, поскольку обычно можно использовать перечисления. Иногда они необходимы для взаимодействия с API библиотек языка C.
Если мы просто хотим интерпретировать байты как другой тип, нам, вероятно, понадобится std::mem::transmute или безопасная оболочка, такая как крейт zerocopy.
Небезопасные функции
Вызов небезопасных функций
Функция или метод могут быть помечены как unsafe, если у них есть дополнительные условия, которые должны быть соблюдены во избежание неопределенного поведения:
extern "C" {
fn abs(input: i32) -> i32;
}
fn main() {
let emojis = "🗻∈🌏";
// Безопасно, потому что индексы находятся в правильном порядке, в пределах
// фрагмента строки (string slice) и последовательности UTF-8
unsafe {
println!("эмодзи: {}", emojis.get_unchecked(0..4));
println!("эмодзи: {}", emojis.get_unchecked(4..7));
println!("эмодзи: {}", emojis.get_unchecked(7..11));
}
println!("количество символов: {}", count_chars(unsafe { emojis.get_unchecked(0..7) }));
unsafe {
// Потенциально неопределенное поведение
println!("абсолютное значение -3 согласно C: {}", abs(-3));
}
// Несоблюдение требований кодировки UTF-8 нарушает безопасность памяти
// println!("эмодзи: {}", unsafe { emojis.get_unchecked(0..3) });
// println!("количество символов: {}", count_chars(unsafe {
// emojis.get_unchecked(0..3) }));
}
fn count_chars(s: &str) -> usize {
s.chars().count()
}
Создание небезопасных функций
Мы можем пометить собственные функции как unsafe, если они требуют соблюдения определенных условий во избежание неопределенного поведения:
/// Меняет значения, на которые указывают указатели
///
/// # Безопасность
///
/// Указатели должны быть валидными и правильно выровненными
unsafe fn swap(a: *mut u8, b: *mut u8) {
let temp = *a;
*a = *b;
*b = temp;
}
fn main() {
let mut a = 42;
let mut b = 66;
// Безопасно, поскольку...
unsafe {
swap(&mut a, &mut b);
}
println!("a = {}, b = {}", a, b);
}
Вызов небезопасных функций
get_unchecked, как и большинство функций _unchecked, небезопасна, поскольку может привести к неопределенному поведению, если диапазон неверен. abs небезопасна по другой причине: это внешняя функция (FFI). Вызов внешних функций обычно является проблемой только тогда, когда эти функции совершают действия с указателями, которые могут нарушить модель памяти Rust, но в целом любая функция C может иметь неопределенное поведение при определенных обстоятельствах.
Создание небезопасных функций
На самом деле в примере создания небезопасной функции мы не стали бы использовать указатели - такую функцию можно безопасно реализовать с помощью ссылок.
Обратите внимание, что небезопасный код разрешен внутри небезопасной функции без блока unsafe. Мы можем запретить это с помощью #[deny(unsafe_op_in_unsafe_fn)]. Попробуйте добавить его и посмотрите, что произойдет. Вероятно, это изменится в будущей версии Rust.
Небезопасные трейты
Как и в случае с функциями, мы можем пометить трейт как unsafe, если его реализация должна гарантировать определенные условия во избежание неопределенного поведения.
Например, крейт zerocopy имеет небезопасный трейт, который выглядит примерно так:
use std::mem::size_of_val;
use std::slice;
/// ...
/// # Безопасность
/// Тип должен иметь определенное представление и не иметь отступов (padding)
pub unsafe trait AsBytes {
fn as_bytes(&self) -> &[u8] {
unsafe {
slice::from_raw_parts(
self as *const Self as *const u8,
size_of_val(self),
)
}
}
}
// Безопасно, поскольку `u32` имеет определенное представление и не имеет отступов
unsafe impl AsBytes for u32 {}
В Rustdoc должен быть раздел # Safety (безопасность) с требованиями к безопасной реализации трейта.
Реальный раздел безопасности для AsBytes гораздо длиннее и сложнее.
Встроенные трейты Send и Sync являются небезопасными.
Упражнение: безопасная обертка FFI
Обратите внимание: это упражнение является сложным и опциональным.
В Rust имеется отличная поддержка вызова функций через интерфейс внешних функций (foreign function interface, FFI). Мы будем использовать это для создания безопасной оболочки для функций libc, которые используются в C для чтения имен файлов в директории.
Полезно изучить следующие страницы руководства:
Также полезно изучить документацию модуля std::ffi. Там вы найдете несколько типов строк, которые вам понадобятся для упражнения:
| Типы | Кодировка | Назначение |
|---|---|---|
| str и String | UTF-8 | Обработка текста в Rust |
| CStr и CString | NUL-завершенная | Взаимодействие с функциями C |
| OsStr и OsString | Зависит от ОС | Взаимодействие с ОС |
Вы будете выполнять следующие преобразования типов:
&strвCString- необходимо выделение пространства для завершающего символа\0CStringв*const i8- для вызова функцийCнужен указатель*const i8в&CStr- требуется средство обнаружения завершающего символа\0&CStrв&[u8]- срез байтов - это универсальный интерфейс для "некоторых неизвестных данных"&[u8]в&OsStr-&OsStr- это шаг на пути кOsString, используйте OsStrExt для ее создания&OsStrвOsString- данные в&OsStrнужно клонировать для того, чтобы иметь возможность их вернуть и повторно вызватьreaddir
В Nomicon имеется отличный раздел о FFI.
mod ffi {
use std::os::raw::{c_char, c_int};
#[cfg(not(target_os = "macos"))]
use std::os::raw::{c_long, c_uchar, c_ulong, c_ushort};
// Непрозрачный тип. См. https://doc.rust-lang.org/nomicon/ffi.html.
#[repr(C)]
pub struct DIR {
_data: [u8; 0],
_marker: core::marker::PhantomData<(*mut u8, core::marker::PhantomPinned)>,
}
// Макет в соответствии со страницей руководства Linux для `readdir(3)`, где `ino_t` и
// `off_t` разрешаются согласно определениям в
// /usr/include/x86_64-linux-gnu/{sys/types.h, bits/typesizes.h}.
#[cfg(not(target_os = "macos"))]
#[repr(C)]
pub struct dirent {
pub d_ino: c_ulong,
pub d_off: c_long,
pub d_reclen: c_ushort,
pub d_type: c_uchar,
pub d_name: [c_char; 256],
}
// Макет в соответствии со страницей руководства `macOS` для `dir(5)`.
#[cfg(all(target_os = "macos"))]
#[repr(C)]
pub struct dirent {
pub d_fileno: u64,
pub d_seekoff: u64,
pub d_reclen: u16,
pub d_namlen: u16,
pub d_type: u8,
pub d_name: [c_char; 1024],
}
extern "C" {
pub fn opendir(s: *const c_char) -> *mut DIR;
#[cfg(not(all(target_os = "macos", target_arch = "x86_64")))]
pub fn readdir(s: *mut DIR) -> *const dirent;
// См. https://github.com/rust-lang/libc/issues/414 и раздел
// _DARWIN_FEATURE_64_BIT_INODE на странице руководства `macOS` для `stat(2)`.
//
// "Платформы, существовавшие до того, как эти обновления стали доступны"
// (platforms that existed before these updates were available) относятся к
// macOS (но не к iOS, wearOS и т.д.) на Intel и PowerPC.
#[cfg(all(target_os = "macos", target_arch = "x86_64"))]
#[link_name = "readdir$INODE64"]
pub fn readdir(s: *mut DIR) -> *const dirent;
pub fn closedir(s: *mut DIR) -> c_int;
}
}
use std::ffi::{CStr, CString, OsStr, OsString};
use std::os::unix::ffi::OsStrExt;
#[derive(Debug)]
struct DirectoryIterator {
path: CString,
dir: *mut ffi::DIR,
}
impl DirectoryIterator {
fn new(path: &str) -> Result<DirectoryIterator, String> {
// Вызываем `opendir` и возвращаем значение `Ok` при успехе
// и `Err` с сообщением при неудаче
unimplemented!()
}
}
impl Iterator for DirectoryIterator {
type Item = OsString;
fn next(&mut self) -> Option<OsString> {
// Продолжаем вызывать `readdir` до тех пор, пока не вернется указатель на значение NULL
unimplemented!()
}
}
impl Drop for DirectoryIterator {
fn drop(&mut self) {
// Вызывваем `closedir` по необходимости
unimplemented!()
}
}
fn main() -> Result<(), String> {
let iter = DirectoryIterator::new(".")?;
println!("файлы: {:#?}", iter.collect::<Vec<_>>());
Ok(())
}
#[cfg(test)]
mod tests {
use super::*;
use std::error::Error;
#[test]
fn test_nonexisting_directory() {
let iter = DirectoryIterator::new("no-such-directory");
assert!(iter.is_err());
}
#[test]
fn test_empty_directory() -> Result<(), Box<dyn Error>> {
let tmp = tempfile::TempDir::new()?;
let iter = DirectoryIterator::new(
tmp.path().to_str().ok_or("Non UTF-8 character in path")?,
)?;
let mut entries = iter.collect::<Vec<_>>();
entries.sort();
assert_eq!(entries, &[".", ".."]);
Ok(())
}
#[test]
fn test_nonempty_directory() -> Result<(), Box<dyn Error>> {
let tmp = tempfile::TempDir::new()?;
std::fs::write(tmp.path().join("foo.txt"), "The Foo Diaries\n")?;
std::fs::write(tmp.path().join("bar.png"), "<PNG>\n")?;
std::fs::write(tmp.path().join("crab.rs"), "//! Crab\n")?;
let iter = DirectoryIterator::new(
tmp.path().to_str().ok_or("Non UTF-8 character in path")?,
)?;
let mut entries = iter.collect::<Vec<_>>();
entries.sort();
assert_eq!(entries, &[".", "..", "bar.png", "crab.rs", "foo.txt"]);
Ok(())
}
}
Решение:
Параллельный Rust
Rust полностью поддерживает параллелизм (concurrency) с использованием потоков ОС с мьютексами (mutexes) и каналами (channels).
Система типов Rust играет важную роль в том, что многие ошибки параллелизма становятся ошибками времени компиляции. Это часто называют бесстрашным параллелизмом (fearless concurrency), поскольку мы можем положиться на компилятор, который обеспечивает правильную обработку параллелизма во время выполнения.
Потоки
Потоки (threads) Rust работают аналогично потокам в других языках:
use std::thread;
use std::time::Duration;
fn main() {
thread::spawn(|| {
for i in 1..10 {
println!("значение счетчика в выделенном потоке: {i}!");
thread::sleep(Duration::from_millis(5));
}
});
for i in 1..5 {
println!("значение счетчика в основном потоке: {i}");
thread::sleep(Duration::from_millis(5));
}
}
- потоки являются потоками демона (daemon threads), основной поток не ждет их выполнения
- потоки паникуют независимо друг от друга
- паника может содержать полезную нагрузку (payload), которую можно извлечь с помощью
downcast_ref
- паника может содержать полезную нагрузку (payload), которую можно извлечь с помощью
Ремарки:
- обратите внимание, что основной поток не ждет выполнения выделенных (spawned) потоков
- для ожидания выполнения потока следует использовать
let handle = thread::spawn()и затемhandle.join() - вызовите панику в потоке. Обратите внимание, что это не влияет на
main - используйте
Result, возвращаемый изhandle.join(), для доступа к полезной нагрузке паники. В этом может помочь Any
Потоки с ограниченной областью видимости
Обычные потоки не могут заимствовать значения из окружения:
use std::thread;
fn foo() {
let s = String::from("привет");
thread::spawn(|| {
println!("длина: {}", s.len());
});
}
fn main() {
foo();
}
Однако для этого можно использовать scoped threads (потоки с ограниченной областью видимости):
use std::thread;
fn main() {
let s = String::from("привет");
thread::scope(|scope| {
scope.spawn(|| {
println!("длина: {}", s.len());
});
});
}
Ремарки:
- когда функция
thread::scopeзавершается, все потоки гарантированно объединяются, поэтому они могут вернуть заимствованные данные - применяются обычные правила заимствования
Rust: мы можем заимствовать значение мутабельно в одном потоке, или иммутабельно в любом количестве потоков
Каналы
Каналы (channels) Rust состоят из двух частей: Sender<T> (отправитель/передатчик) и Receiver<T> (получатель/приемник). Они соединяются с помощью канала, но мы видим только конечные точки:
use std::sync::mpsc;
fn main() {
let (tx, rx) = mpsc::channel();
tx.send(10).unwrap();
tx.send(20).unwrap();
println!("Получено: {:?}", rx.recv());
println!("Получено: {:?}", rx.recv());
let tx2 = tx.clone();
tx2.send(30).unwrap();
println!("Получено: {:?}", rx.recv());
}
mpscозначает Multi-Producer, Single-Consumer (несколько производителей, один потребитель).SenderиSyncSenderреализуютClone(поэтому мы можем создать несколько производителей), аReceiverне реализует (поэтому у нас может быть только один потребитель)send()иrecv()возвращаютResult. Если они возвращаютErr, значит соответствующийSenderилиReceiverуничтожен (dropped) и канал закрыт
Несвязанные каналы
mpsc::channel() возвращает несвязанный (unbounded) и асинхронный канал:
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let thread_id = thread::current().id();
for i in 1..10 {
tx.send(format!("Сообщение {i}")).unwrap();
println!("{thread_id:?}: отправил сообщение {i}");
}
println!("{thread_id:?}: готово");
});
thread::sleep(Duration::from_millis(100));
for msg in rx.iter() {
println!("Основной поток: получено {msg}");
}
}
Связанные каналы
send() связанного (bounded) синхронного канала блокирует текущий поток:
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
let (tx, rx) = mpsc::sync_channel(3);
thread::spawn(move || {
let thread_id = thread::current().id();
for i in 1..10 {
tx.send(format!("Сообщение {i}")).unwrap();
println!("{thread_id:?}: отправил сообщение {i}");
}
println!("{thread_id:?}: готово");
});
thread::sleep(Duration::from_millis(100));
for msg in rx.iter() {
println!("Основной поток: получено {msg}");
}
}
Ремарки:
- вызов
send()блокирует текущий поток до тех пор, пока в канале имеется место для новых сообщений. Поток может блокироваться бесконечно, если отсутствует получатель - вызов
send()заканчивается ошибкой (поэтому возвращаетсяResult), если канал закрыт. Канал закрывается после уничтожения получателя - связанный канал с нулевым размером называется "rendezvous channel". Каждый вызов
send()блокирует текущий поток, пока другой поток не вызоветread()
Send и Sync
Откуда Rust знает о необходимости запрета доступа к общему (shared) состоянию из нескольких потоков? Ответ кроется в двух трейтах:
- Send: тип
TявляетсяSend, если передачаTв другой поток является безопасной - Sync: тип
TявляетсяSync, если передача&Tв другой поток является безопасной
Send и Sync являются небезопасными трейтами. Компилятор автоматически реализует их для наших типов при условии, что они содержат только типы Send и Sync. Эти типы можно реализовать самостоятельно, если мы уверены в валидности наших типов.
Ремарки:
- о типах
SendиSyncможно думать как о маркерах того, что тип содержит несколько безопасных с точки зрения потоков (thread-safety) свойств - эти типы могут использоваться в качестве общих ограничений по аналогии с обычными трейтами
Send
Тип T является Send, если передача значения T в другой поток является безопасной.
Эффект перемещения владения в другой поток заключается в том, что деструкторы T запускаются в этом новом потоке. Поэтому вопрос состоит в том, когда мы можем выделить значение в одном потоке и освободить его в другом потоке.
Например, подключение к SQLite доступно только в одном потоке.
Sync
Тип T является Sync, если одновременный доступ к значению T из нескольких потоков является безопасным.
Если быть более точным, определение гласит следующее: T является Sync, если и только если &T является Send.
Это означает, что если тип является "потокобезопасным" (thread-safe) для совместного использования, он также потокобезопасен для передачи ссылок между потоками.
Если тип является Sync, его можно использовать в нескольких потоках без риска возникновения гонок за данными (data race) и других проблем с синхронизацией, поэтому его можно безопасно перемещать в другой поток. Ссылка на тип также может безопасно перемещаться в другой поток, поскольку доступ к данным, на которые она ссылается, из любого потока является безопасным.
Примеры
Send + Sync
Большинство типов является Send + Sync:
i8,f32,bool,char,&stretc.(T1, T2),[T; N],&[T],struct { x: T }etc.String,Option<T>,Vec<T>,Box<T>etc.Arc<T>- явно потокобезопасный благодаря атомарному подсчету ссылокMutex<T>- явно потокобезопасный благодаря внутренней блокировкеAtomicBool,AtomicU8etc., где используются специальные атомарные инструкции
Дженерики обычно являются Send + Sync, когда таковыми являются параметры типов.
Send + !Sync
Эти типы могут перемещаться в другие потоки, но не являются потокобезопасными. Обычно это связано с их внутренней изменчивостью:
mpsc::Sender<T>mpsc::Receiver<T>Cell<T>RefCell<T>
!Send + Sync
Эти типы являются потокобезопасными, но не могут перемещаться в другие потоки:
MutexGuard<T: Sync>- использует примитивы уровня ОС, которые должны быть освобождены в создавшем их потоке
!Send + !Sync
Эти типы не являются потокобезопасными и не могут перемещаться в другой поток:
Rc<T>- каждыйRc<T>содержит ссылку наRcBox<T>, который содержит неатомарный счетчик ссылок*const T,*mut T-Rustпредполагает, что сырые указатели могут иметь нюансы, связанные с их параллельным выполнением
Общее состояние
Rust использует систему типов для обеспечения синхронизации общих (shared) данных. Это делается в основном с помощью двух типов:
Arc<T>- атомарный счетчик ссылок наT: обрабатывает передачу между потоками и освобождаетTпри уничтожении последней ссылки на нееMutex<T>- обеспечивает взаимоисключающий доступ к значениюT
Arc
Arc<T> предоставляет общий доступ только для чтения к T через Arc::clone():
use std::sync::Arc;
use std::thread;
fn main() {
let v = Arc::new(vec![10, 20, 30]);
let mut handles = Vec::new();
for _ in 1..5 {
let v = Arc::clone(&v);
handles.push(thread::spawn(move || {
let thread_id = thread::current().id();
println!("{thread_id:?}: {v:?}");
}));
}
handles.into_iter().for_each(|h| h.join().unwrap());
println!("v: {v:?}");
}
Ремарки:
Arcозначает Atomic Reference Counter (атомарный счетчик ссылок) и является потокобезопасной версиейRc, в которой используются атомарные операцииArc<T>реализуетCloneнезависимо от того, делает ли этоT. Он реализуетSendиSync, только еслиTих реализуетArc::clone()имеет некоторую цену за счет выполнения атомарных операций, но после этого использованиеTявляется бесплатным- остерегайтесь ссылочных циклов,
Arcне использует сборщик мусора для их обнаружения- в этом может помочь
std::sync::Weak
- в этом может помочь
Mutex
Mutex<T> обеспечивает взаимное исключение и предоставляет мутабельный доступ к T через доступный только для чтения интерфейс (форма внутренней изменчивости):
use std::sync::Mutex;
fn main() {
let v = Mutex::new(vec![10, 20, 30]);
println!("v: {:?}", v.lock().unwrap());
{
let mut guard = v.lock().unwrap();
guard.push(40);
}
println!("v: {:?}", v.lock().unwrap());
}
Обратите внимание на неявную реализацию (impl<T: Send> Sync for Mutex<T>)https://doc.rust-lang.org/std/sync/struct.Mutex.html#impl-Sync-for-Mutex%3CT%3E.
Ремарки:
MutexвRustпохож на коллекцию, состоящую из одного элемента - защищенных данных- невозможно забыть получить (acquire) мьютекс перед доступом к защищенным данным
- из
&Mutex<T>через блокировку (lock) можно получить&mut T.MutexGuardгарантирует, что&mut Tне живет дольше удерживаемой (held) блокировки Mutex<T>реализуетSendиSync, только еслиTреализуетSendRwLockявляется блокировкой, доступной как для чтения, так и для записи- почему
lock()возвращаетResult?- Если поток, в котором находится мьютекс, паникует, мьютекс становится "отравленным" (poisoned), сигнализируя о том, что защищенные данные могут находиться в несогласованном состоянии. Вызов
lock()на отравленном мьютексе проваливается с PoisonError. Для восстановления данных можно вызватьinto_iter()на ошибке
- Если поток, в котором находится мьютекс, паникует, мьютекс становится "отравленным" (poisoned), сигнализируя о том, что защищенные данные могут находиться в несогласованном состоянии. Вызов
Пример
Рассмотрим Arc и Mutex в действии:
use std::thread;
// use std::sync::{Arc, Mutex};
fn main() {
let v = vec![10, 20, 30];
let handle = thread::spawn(|| {
v.push(10);
});
v.push(1000);
handle.join().unwrap();
println!("v: {v:?}");
}
Возможное решение:
use std::sync::{Arc, Mutex};
use std::thread;
fn main() {
let v = Arc::new(Mutex::new(vec![10, 20, 30]));
let v2 = Arc::clone(&v);
let handle = thread::spawn(move || {
let mut v2 = v2.lock().unwrap();
v2.push(10);
});
{
let mut v = v.lock().unwrap();
v.push(1000);
}
handle.join().unwrap();
println!("v: {v:?}");
}
Ремарки:
vобернут вArcиMutex, поскольку их зоны ответственности ортогональны- оборачивание
MutexвArcявляется распространенным паттерном для передачи мутабельного состояния между потоками
- оборачивание
v: Arc<_>должен быть клонирован какv2для передачи в другой поток. Обратите внимание наmoveв сигнатуре лямбды- блоки предназначены для максимального сужения области видимости
LockGuard
Упражнения
Попрактикуемся применять новые знания на двух упражнениях:
- обедающие философы - классическая задача параллелизма
- многопоточная проверка ссылок
Обедающие философы
Условия задачи:
Пять безмолвных философов сидят вокруг круглого стола, перед каждым философом стоит тарелка спагетти. На столе между каждой парой ближайших философов лежит по одной вилке.
Каждый философ может либо есть, либо размышлять. Прием пищи не ограничен количеством оставшихся спагетти - подразумевается бесконечный запас. Тем не менее, философ может есть только тогда, когда держит две вилки - взятую справа и слева.
Каждый философ может взять ближайшую вилку (если она доступна) или положить - если он уже держит ее. Взятие каждой вилки и возвращение ее на стол являются раздельными действиями, которые должны выполняться одно за другим.
Задача заключается в том, чтобы разработать модель (параллельный алгоритм), при которой ни один из философов не будет голодать, то есть будет чередовать прием пищи и размышления 100 раз.
use std::sync::{mpsc, Arc, Mutex};
use std::thread;
use std::time::Duration;
struct Fork;
struct Philosopher {
name: String,
// left_fork: ...
// right_fork: ...
// thoughts: ...
}
impl Philosopher {
fn think(&self) {
self.thoughts
.send(format!("Эврика! {} сгенерировал(а) новую идею!", &self.name))
.unwrap();
}
fn eat(&self) {
// Берем вилки
println!("{} ест...", &self.name);
thread::sleep(Duration::from_millis(10));
}
}
static PHILOSOPHERS: &[&str] =
&["Сократ", "Гипатия", "Платон", "Аристотель", "Пифагор"];
fn main() {
// Создаем вилки
// Создаем философов
// Каждый философ размышляет и ест 100 раз
// Выводим размышления философов
}
Подсказка: рассмотрите возможность использования std::mem::swap для решения проблемы взаимной блокировки (deadlock).
Решение:
Многопоточная проверка ссылок
Создадим инструмент для многопоточной проверки ссылок. Он должен начинать с основной веб-страницы и проверять корректность ссылок на ней. Затем он должен рекурсивно проверять другие страницы в том же домене и продолжать делать это до тех пор, пока все страницы не будут проверены.
Для создания такого инструмента вам потребуется какой-нибудь клиент HTTP, например, reqwest:
cargo add reqwest --features blocking,rustls-tls
Для обнаружения ссылок можно воспользоваться scraper:
cargo add scraper
Наконец, для обработки ошибок пригодится thiserror:
cargo add thiserror
Cargo.toml:
[package]
name = "link-checker"
version = "0.1.0"
edition = "2021"
publish = false
[dependencies]
reqwest = { version = "0.11.12", features = ["blocking", "rustls-tls"] }
scraper = "0.13.0"
thiserror = "1.0.37"
Начните с небольшого сайта, такого как https://www.google.org.
src/main.rs:
use reqwest::blocking::Client;
use reqwest::Url;
use scraper::{Html, Selector};
use thiserror::Error;
#[derive(Error, Debug)]
enum Error {
#[error("ошибка запроса: {0}")]
ReqwestError(#[from] reqwest::Error),
#[error("плохой ответ HTTP: {0}")]
BadResponse(String),
}
#[derive(Debug)]
struct CrawlCommand {
url: Url,
extract_links: bool,
}
fn visit_page(client: &Client, command: &CrawlCommand) -> Result<Vec<Url>, Error> {
println!("проверка {:#}", command.url);
let response = client.get(command.url.clone()).send()?;
if !response.status().is_success() {
return Err(Error::BadResponse(response.status().to_string()));
}
let mut link_urls = Vec::new();
if !command.extract_links {
return Ok(link_urls);
}
let base_url = response.url().to_owned();
let body_text = response.text()?;
let document = Html::parse_document(&body_text);
let selector = Selector::parse("a").unwrap();
let href_values = document
.select(&selector)
.filter_map(|element| element.value().attr("href"));
for href in href_values {
match base_url.join(href) {
Ok(link_url) => {
link_urls.push(link_url);
}
Err(err) => {
println!("в {base_url:#} не поддается разбору {href:?}: {err}");
}
}
}
Ok(link_urls)
}
fn main() {
let client = Client::new();
let start_url = Url::parse("https://www.google.org").unwrap();
let crawl_command = CrawlCommand{ url: start_url, extract_links: true };
match visit_page(&client, &crawl_command) {
Ok(links) => println!("ссылки: {links:#?}"),
Err(err) => println!("невозможно извлечь ссылки: {err:#}"),
}
}
Задачи:
- используйте потоки для параллельной проверки ссылок: отправьте проверяемые URL-адреса в канал и позвольте нескольким потокам проверять URL-адреса параллельно
- реализуйте рекурсивное извлечение ссылок со всех страниц домена
www.google.org. Установите верхний предел в 100 страниц или около того, чтобы сайт вас не заблокировал
Решение:
Асинхронный Rust
"Асинхронность" (async) - это модель параллелизма, в которой несколько задач выполняются одновременно. Каждая задача выполняется до тех пор, пока не завершится или не заблокируется, затем выполняется следующая (готовая к выполнению) задача и т.д. Такая модель позволяет выполнять большое количество задач с помощью небольшого числа потоков. Это связано с тем, что накладные расходы на выполнение каждой задачи обычно очень низкие, а операционные системы предоставляют примитивы для эффективного переключения между задачами.
Асинхронные операции Rust основаны на фьючерсах (futures, от "future" - будущее), представляющих собой работу, которая может быть завершена в будущем. Фьючерсы "опрашиваются" (polled) до тех пор, пока не сообщат о завершении.
Фьючерсы опрашиваются асинхронной средой выполнения (async runtime). Доступно несколько таких сред. Одной из самых популярных является Tokio.
Сравнения:
- в
Pythonиспользуется похожая модель вasyncio. Однако, его типFutureоснован на функциях обратного вызова (callbacks), а не на опросах. Асинхронные программыPythonдолжны выполняться в цикле, как и асинхронные программыRust PromiseвJavaScriptпохож на фьючерс, но также основан на колбэках. Среды выполнения реализует цикл событий (event loop), поэтому многие детали разрешения промиса являются скрытыми
Основы асинхронности
async/await
На высоком уровне асинхронный код Rust выглядит очень похоже на обычный синхронный код:
use futures::executor::block_on;
async fn count_to(count: i32) {
for i in 1..=count {
println!("Значение счетчика: {i}!");
}
}
async fn async_main(count: i32) {
count_to(count).await;
}
fn main() {
block_on(async_main(10));
}
Ремарки:
- это упрощенный пример для демонстрации синтаксиса. В нем отсутствуют долгие операции или параллелизм
- какой тип возвращает асинхронная функция?
- используйте
let future: () = async_main(10);вmain()и посмотрите
- используйте
- ключевое слово
async- это синтаксический сахар. Компилятор заменяет возвращаемый тип фьючерсом - мы не можем сделать функцию
mainасинхронной без предоставления компилятору дополнительных инструкций о том, как использовать возвращаемый фьючерс - для запуска асинхронного кода требуется исполнитель (executor).
block_on()блокирует текущий поток до завершения фьючерса .awaitасинхронно ждет завершения другой операции. В отличие отblock_on(),awaitне блокирует текущий потокawaitможет использоваться только внутри асинхронной функции (или блока, о чем мы поговорим позже)
Фьючерсы
Future - это трейт, реализуемый объектами, представляющими операцию, которая пока не может быть завершена. Фьючерсы могут опрашиваться, poll() возвращает Poll.
use std::pin::Pin;
use std::task::Context;
pub trait Future {
type Output;
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
pub enum Poll<T> {
Ready(T),
Pending,
}
Асинхронная функция возвращает impl Future. Также возможно (но редко применяется) реализовать Future для собственных типов. Например, JoinHandle, возвращаемый tokio::spawn реализует Future, что позволяет присоединяться (join) к нему.
Ключевое слово await приостанавливает выполнение асинхронной функции, пока фьючерс не будет готов.
Ремарки:
- типы
FutureиPollреализованы в точности, как показано - мы не будем рассматривать
PinиContext, поскольку не будет создавать новые асинхронные примитивы. Коротко:Contextпозволяет фьючерсу планировать повторный опрос при возникновении событияPinгарантирует, что фьючерс не перемещается в памяти, поэтому ссылки в этом фьючерсе остаются валидными. Это необходимо, чтобы ссылки оставались валидными послеawait
Среда выполнения
Среда выполнения (runtime) предоставляет поддержку для асинхронного выполнения операций (reactor) и отвечает за выполнение фьючерсов (executor). Rust не имеет "встроенной" среды выполнения, но доступно несколько вариантов:
- Tokio - производительный, с хорошим набором инструментов, таких как Hyper для
HTTPили Tonic дляgRPC - async-std - стремится быть "стандартной библиотекой для асинхронного кода" и включает стандартную среду выполнения в
async::task - smol - простой и легковесный
Несколько больших приложений имеют собственные среды выполнения. Одним из таких приложений является Fuchsia.
Фьючерсы являются "инертными" в том смысле, что они ничего не делают, пока не будут опрошены исполнителем. Это отличается от промисов JS, например, которые запускаются, даже если никогда не используются.
Tokio
Tokio предоставляет:
- многопоточную среду выполнения для выполнения асинхронного кода
- асинхронную версию стандартной библиотеки
- большую экосистему библиотек
use tokio::time;
async fn count_to(count: i32) {
for i in 1..=count {
println!("Значение счетчика в задаче: {i}!");
time::sleep(time::Duration::from_millis(5)).await;
}
}
#[tokio::main]
async fn main() {
tokio::spawn(count_to(10));
for i in 1..5 {
println!("Значение счетчика в основной задаче: {i}");
time::sleep(time::Duration::from_millis(5)).await;
}
}
Ремарки:
- макрос
tokio::mainпозволяет делать функциюmainасинхронной - функция
spawnсоздает новую параллельную "задачу" - обратите внимание:
spawnпринимаетFuture, мы не вызывает.awaitнаcount_to() - почему
count_to()обычно не доходит до 10? Это пример отмены асинхронной операции.tokio::spawn()возвращает обработчик (handle), который может заставить поток ждать его завершения - попробуйте заменить
tokio::spawnнаcount_to(10).await - попробуйте добавить ожидание завершения задачи, возвращаемой
tokio::spawn()
Задачи
Rust имеет систему задач (task system), которая является формой легковесного трейдинга (threading).
Задача имеет один верхнеуровневый фьючерс, который опрашивается исполнителем. Этот фьючерс может иметь несколько вложенных фьючерсов, которые он опрашивает методом poll, что приблизительно соответствует стеку вызовов (call stack). Параллелизм внутри задачи возможен путем опроса нескольких дочерних фьючерсов, например, запуск таймера и выполнение операции ввода-вывода.
use tokio::io::{self, AsyncReadExt, AsyncWriteExt};
use tokio::net::TcpListener;
#[tokio::main]
async fn main() -> io::Result<()> {
let listener = TcpListener::bind("127.0.0.1:0").await?;
println!("запросы принимаются на порту {}", listener.local_addr()?.port());
loop {
let (mut socket, addr) = listener.accept().await?;
println!("запрос из {addr:?}");
tokio::spawn(async move {
socket.write_all(b"Кто ты?\n").await.expect("ошибка сокета");
let mut buf = vec![0; 1024];
let name_size = socket.read(&mut buf).await.expect("ошибка сокета");
let name = std::str::from_utf8(&buf[..name_size]).unwrap().trim();
let reply = format!("Привет, {name}!\n");
socket.write_all(reply.as_bytes()).await.expect("ошибка сокета");
});
}
}
- Перед нами
asyncблок. Такие блоки похожи на замыкания, но не принимают параметров. Их возвращаемым значением является фьючерс, как уasync fn - переделайте асинхронный блок в функцию и улучшите обработку ошибок с помощью оператора
?
Асинхронные каналы
Некоторые крейты поддерживают асинхронные каналы, например, tokio:
use tokio::sync::mpsc::{self, Receiver};
async fn ping_handler(mut input: Receiver<()>) {
let mut count: usize = 0;
while let Some(_) = input.recv().await {
count += 1;
println!("получено {count} пингов");
}
println!("ping_handler завершен");
}
#[tokio::main]
async fn main() {
let (sender, receiver) = mpsc::channel(32);
let ping_handler_task = tokio::spawn(ping_handler(receiver));
for i in 0..10 {
sender.send(()).await.expect("провал отправки пинга");
println!("отправлено {} пингов", i + 1);
}
drop(sender);
ping_handler_task.await.expect("что-то пошло не так");
}
- измените размер канала на
3и посмотрите, как это повлияет на выполнение - интерфейс асинхронных каналов аналогичен интерфейсу
syncканалов, о которых мы говорили ранее - попробуйте удалить
std::mem::drop. Что произойдет? Почему? - крейт Flume предоставляет каналы, которые реализуют как
sync, так иasync send, иrecv. Это может быть полезным для сложных приложений с задачами обработки ввода-вывода и тяжелыми для ЦП задачами asyncканалы могут быть использованы вместе с другимиfutureдля создания сложного потока управления (control flow)
Поток управления фьючерсов
Фьючерсы могут объединяться вместе для создания графов потоков параллельных вычислений. Мы уже видели задачи, которые функционируют как автономные потоки выполнения.
Join
Метод join_all ждет, когда все фьючерсы будут готовы, и возвращает их результаты. Это похоже на Promise.all в JavaScript или asyncio.gather в Python.
use anyhow::Result;
use futures::future;
use reqwest;
use std::collections::HashMap;
async fn size_of_page(url: &str) -> Result<usize> {
let resp = reqwest::get(url).await?;
Ok(resp.text().await?.len())
}
#[tokio::main]
async fn main() {
let urls: [&str; 4] = [
"https://google.com",
"https://httpbin.org/ip",
"https://play.rust-lang.org/",
"BAD_URL",
];
let futures_iter = urls.into_iter().map(size_of_page);
let results = future::join_all(futures_iter).await;
let page_sizes_dict: HashMap<&str, Result<usize>> =
urls.into_iter().zip(results.into_iter()).collect();
println!("{:?}", page_sizes_dict);
}
Ремарки:
- для нескольких фьючерсов непересекающихся типов можно использовать
std::future::join!но мы должны знать, сколько фьючерсов у нас будет во время компиляции. В настоящее времяjoin_all()находится в крейтеfutures, но скоро будет стабилизирован вstd::future - риск соединения заключается в том, что какой-нибудь фьючерс может никогда не разрешиться, что приведет к остановке программы
- мы можем комбинировать
join_all()сjoin!, например, чтобы объединить все запросы к службеHTTP, а также запрос к базе данных. Попробуйте добавитьtokio::time::sleep()во фьючерс, используяfuture::join!. Это не таймаут (для которого требуетсяselect!, как описано в следующем разделе), а демонстрация работыjoin!
Select
Операция выбора (select) ждет готовности любого фьючерса из набора и реагирует на его результат. В JavaScript это похоже на Promise.race. В Python это похоже на asyncio.wait(task_set, return_when=asyncio.FIRST_COMPLETED).
Подобно оператору match, тело select! имеет несколько ветвей (arms), каждая из которых имеет форму pattern = future => statement. Когда future готов, его возвращаемое значение деструктурируется pattern. Затем statement запускается с итоговыми переменными. Результат statement становится результатом макроса select!.
use tokio::sync::mpsc::{self, Receiver};
use tokio::time::{sleep, Duration};
#[derive(Debug, PartialEq)]
enum Animal {
Cat { name: String },
Dog { name: String },
}
async fn first_animal_to_finish_race(
mut cat_rcv: Receiver<String>,
mut dog_rcv: Receiver<String>,
) -> Option<Animal> {
tokio::select! {
cat_name = cat_rcv.recv() => Some(Animal::Cat { name: cat_name? }),
dog_name = dog_rcv.recv() => Some(Animal::Dog { name: dog_name? })
}
}
#[tokio::main]
async fn main() {
let (cat_sender, cat_receiver) = mpsc::channel(32);
let (dog_sender, dog_receiver) = mpsc::channel(32);
tokio::spawn(async move {
sleep(Duration::from_millis(500)).await;
cat_sender.send(String::from("Феликс")).await.expect("ошибка отправки имени кота");
});
tokio::spawn(async move {
sleep(Duration::from_millis(50)).await;
dog_sender.send(String::from("Рекс")).await.expect("ошибка отправки имени собаки");
});
let winner = first_animal_to_finish_race(cat_receiver, dog_receiver)
.await
.expect("ошибка получения победителя");
println!("Победителем является {winner:?}");
}
Ремарки:
- в примере у нас имеется гонка между кошкой и собакой.
first_animal_to_finish_race()"слушает" (listening) оба канала и возвращает первый по времени результат. Поскольку имя собаки прибывает через 50 мс, собака выигрывает у кошки, имя которой прибывает через 500 мс - в примере вместо
channelможно использоватьoneshot, поскольку предполагается однократный вызов методаsend - попробуйте добавить к гонке дедлайн, демонстрируя выбор разных фьючерсов
- обратите внимание, что
select!уничтожает не совпавшие ветви, что отменяет их фьючерсы.select!легче всего использовать, когда каждое выполнение этого макроса создает новые фьючерсы- альтернативой является передача
&mut futureвместо самого фьючерса, но это может привести к проблемам, о котором мы поговорим позже
- альтернативой является передача
Ловушки async/await
async/await предоставляет удобную и эффективную абстракцию для параллельного асинхронного программирования. Однако модель async/await в Rust также имеет свои подводные камни и ловушки, о которых мы поговорим в этом разделе.
Блокировка исполнителя
Большинство асинхронных сред выполнения допускают одновременное выполнение только задач ввода-вывода. Это означает, что задачи блокировки ЦП будут блокировать исполнителя (executor) и препятствовать выполнению других задач. Простой обходной путь - использовать эквивалентные асинхронные методы там, где это возможно.
use futures::future::join_all;
use std::time::Instant;
async fn sleep_ms(start: &Instant, id: u64, duration_ms: u64) {
std::thread::sleep(std::time::Duration::from_millis(duration_ms));
println!(
"фьючерс {id} спал в течение {duration_ms} мс, завершился после {} мс",
start.elapsed().as_millis()
);
}
#[tokio::main(flavor = "current_thread")]
async fn main() {
let start = Instant::now();
let sleep_futures = (1..=10).map(|t| sleep_ms(&start, t, t * 10));
join_all(sleep_futures).await;
}
Ремарки:
- запустите код и убедитесь, что переходы в режим сна происходят последовательно, а не одновременно
flavor = "current_thread"помещает все задачи в один поток. Это делает эффект более очевидным, но рассмотренная ошибка присутствует и в многопоточной версии- замените
std::thread::sleepнаtokio::time::sleepи дождитесь результата - другим решением может быть
tokio::task::spawn_blocking, который порождает реальный поток и преобразует его дескриптор вfuture, не блокируя исполнителя - о задачах не следует думать как о потоках ОС. Они не совпадают 1 к 1, и большинство исполнителей позволяют выполнять множество задач в одном потоке ОС. Это особенно проблематично при взаимодействии с другими библиотеками через
FFI, где эта библиотека может зависеть от локального хранилища потоков или сопоставляться с конкретными потоками ОС (например,CUDA). В таких ситуациях отдавайте предпочтениеtokio::task::spawn_blocking - используйте синхронные мьютексы осторожно. Удержание мьютекса над
.awaitможет привести к блокировке другой задачи, которая может выполняться в том же потоке
Pin
Асинхронные блоки и функции возвращают типы, реализующие трейт Future. Возвращаемый тип является результатом преобразования компилятора, который превращает локальные переменные в данные, хранящиеся внутри фьючерса.
Некоторые из этих переменных могут содержать указатели на другие локальные переменные. По этой причине фьючерсы никогда не должны перемещаться в другую ячейку памяти, поскольку это сделает такие указатели недействительными.
Чтобы предотвратить перемещение фьючерса в памяти, его можно опрашивать только через закрепленный (pinned) указатель. Pin - это оболочка ссылки, которая запрещает все операции, которые могли бы переместить экземпляр, на который она указывает, в другую ячейку памяти.
use tokio::sync::{mpsc, oneshot};
use tokio::task::spawn;
use tokio::time::{sleep, Duration};
// Рабочая единица. В данном случае она просто спит в течение определенного времени
// и отвечает сообщением в канал `respond_on`
#[derive(Debug)]
struct Work {
input: u32,
respond_on: oneshot::Sender<u32>,
}
// Воркер, который ищет работу в очереди (queue) и выполняет ее
async fn worker(mut work_queue: mpsc::Receiver<Work>) {
let mut iterations = 0;
loop {
tokio::select! {
Some(work) = work_queue.recv() => {
sleep(Duration::from_millis(10)).await; // выполняем "работу"
work.respond_on
.send(work.input * 1000)
.expect("провал отправки ответа");
iterations += 1;
}
// TODO: сообщать о количестве итераций каждый 100 мс
}
}
}
// "Запрашиватель" (requester), который запрашивает работу и ждет ее выполнения
async fn do_work(work_queue: &mpsc::Sender<Work>, input: u32) -> u32 {
let (tx, rx) = oneshot::channel();
work_queue
.send(Work { input, respond_on: tx })
.await
.expect("провал отправки работы в очередь");
rx.await.expect("провал ожидания ответа")
}
#[tokio::main]
async fn main() {
let (tx, rx) = mpsc::channel(10);
spawn(worker(rx));
for i in 0..100 {
let resp = do_work(&tx, i).await;
println!("результат работы для итерации {i}: {resp}");
}
}
Ремарки:
- в примере вы могли распознать шаблон актора (actor pattern). Акторы, как правило, вызывают
select!в цикле - это обобщение нескольких предыдущих уроков, так что не торопитесь
- добавьте
_ = sleep(Duration::from_millis(100)) => { println!(..) }вselect!. Это никогда не выполнится. Почему? - теперь добавьте
timeout_fut, содержащий этот фьючерс за пределамиloop:
- добавьте
let mut timeout_fut = sleep(Duration::from_millis(100));
loop {
select! {
..,
_ = timeout_fut => { println!(..); },
}
}
- это также не будет работать. Изучите ошибки компилятора, добавьте
&mutвtimeout_futвselect!для решения проблемы перемещения, затем используйтеBox::pin:
let mut timeout_fut = Box::pin(sleep(Duration::from_millis(100)));
loop {
select! {
..,
_ = &mut timeout_fut => { println!(..); },
}
}
- это компилируется, но по истечении тайм-аута на каждой итерации происходит
Poll::Ready(для решения этой проблемы может помочь объединенный фьючерс). Обновите код, чтобы сбрасыватьtimeout_futкаждый раз, когда он истекает Boxвыделяет память в куче. В некоторых случаяхstd::pin::pin!- это тоже вариант, но его сложно использовать для фьючерса, которой переназначается- другая альтернатива - вообще не использовать
pin, а создать другую задачу, которая будет отправляться в каналoneshotкаждые 100 мс - данные, содержащие указатели на себя, называются самоссылающимися (self-referential). Обычно средство проверки заимствований (borrow checker) в
Rustпредотвращает перемещение таких данных, поскольку ссылки не могут жить дольше данных, на которые они указывают. Однако преобразование кода для асинхронных блоков и функций не проверяется средством проверки заимствований Pin- это обертка над ссылкой. Объект не может перемещаться с помощью закрепленного указателя. Однако он может перемещаться с помощью незакрепленного указателя- метод
pollтрейтаFutureиспользуетPin<&mut Self>вместо&mut Selfдля ссылки на экземпляр. Вот почему он может вызываться только на закрепленном указателе
Асинхронные трейты
Асинхронные методы в трейтах пока не поддерживаются в стабильной версии Rust.
Крейт async_trait предоставляет макрос для решения этой задачи:
use async_trait::async_trait;
use std::time::Instant;
use tokio::time::{sleep, Duration};
#[async_trait]
trait Sleeper {
async fn sleep(&self);
}
struct FixedSleeper {
sleep_ms: u64,
}
#[async_trait]
impl Sleeper for FixedSleeper {
async fn sleep(&self) {
sleep(Duration::from_millis(self.sleep_ms)).await;
}
}
async fn run_all_sleepers_multiple_times(
sleepers: Vec<Box<dyn Sleeper>>,
n_times: usize,
) {
for _ in 0..n_times {
println!("running all sleepers..");
for sleeper in &sleepers {
let start = Instant::now();
sleeper.sleep().await;
println!("slept for {}ms", start.elapsed().as_millis());
}
}
}
#[tokio::main]
async fn main() {
let sleepers: Vec<Box<dyn Sleeper>> = vec![
Box::new(FixedSleeper { sleep_ms: 50 }),
Box::new(FixedSleeper { sleep_ms: 100 }),
];
run_all_sleepers_multiple_times(sleepers, 5).await;
}
Ремарки:
async_traitпрост в использовании, но учтите, что для работы он использует выделение памяти в куче. Это влечет издержки производительности- попробуйте создать новую "спящую" структуру, которая будет спать случайное время, и добавить ее в вектор
Отмена
Удаление фьючерса означает, что его больше никогда нельзя будет опросить. Это называется отменой (cancellation) и может произойти в любой момент ожидания. Необходимо позаботиться о том, чтобы система работала правильно даже в случае отмены фьючерса. Например, он не должен блокироваться или терять данные.
use std::io::{self, ErrorKind};
use std::time::Duration;
use tokio::io::{AsyncReadExt, AsyncWriteExt, DuplexStream};
struct LinesReader {
stream: DuplexStream,
}
impl LinesReader {
fn new(stream: DuplexStream) -> Self {
Self { stream }
}
async fn next(&mut self) -> io::Result<Option<String>> {
let mut bytes = Vec::new();
let mut buf = [0];
while self.stream.read(&mut buf[..]).await? != 0 {
bytes.push(buf[0]);
if buf[0] == b'\n' {
break;
}
}
if bytes.is_empty() {
return Ok(None);
}
let s = String::from_utf8(bytes)
.map_err(|_| io::Error::new(ErrorKind::InvalidData, "не UTF-8"))?;
Ok(Some(s))
}
}
async fn slow_copy(source: String, mut dest: DuplexStream) -> std::io::Result<()> {
for b in source.bytes() {
dest.write_u8(b).await?;
tokio::time::sleep(Duration::from_millis(10)).await
}
Ok(())
}
#[tokio::main]
async fn main() -> std::io::Result<()> {
let (client, server) = tokio::io::duplex(5);
let handle = tokio::spawn(slow_copy("привет\nпривет\n".to_owned(), client));
let mut lines = LinesReader::new(server);
let mut interval = tokio::time::interval(Duration::from_millis(60));
loop {
tokio::select! {
_ = interval.tick() => println!("тик!"),
line = lines.next() => if let Some(l) = line? {
print!("{}", l)
} else {
break
},
}
}
handle.await.unwrap()?;
Ok(())
}
Ремарки:
- компилятор не помогает с обеспечением безопасности отмены. Необходимо читать документацию API и понимать, каким состоянием владеет ваша
async fn - в отличие от
panic!и?, отмена - это часть нормального управления потоком выполнения (а не обработка ошибок) - в примере теряется часть строки
- если ветвь
tick()выполняется первой,next()и егоbufуничтожаются LinesReaderможно сделать безопасным для отмены путем включенияbufв структуру:
- если ветвь
struct LinesReader {
stream: DuplexStream,
bytes: Vec<u8>,
buf: [u8; 1],
}
impl LinesReader {
fn new(stream: DuplexStream) -> Self {
Self { stream, bytes: Vec::new(), buf: [0] }
}
async fn next(&mut self) -> io::Result<Option<String>> {
// ...
let raw = std::mem::take(&mut self.bytes);
let s = String::from_utf8(raw)
// ...
}
}
- Interval::tick безопасен для отмены, поскольку он отслеживает, был ли "доставлен" (delivered) тик
- AsyncReadExt::read безопасен для отмены, поскольку он либо возвращается, либо не читает данные
- AsyncBufReadExt::read_line, как и пример, не является безопасным для отмены. Подробности и альтернативы см. в документации
Упражнения
Для тренировки навыков работы с асинхронным Rust, есть еще два упражнения:
- обедающие философы - на этот раз вам нужно решить эту задачу с помощью асинхронного
Rust - приложение для чата
Обедающие философы
use std::sync::Arc;
use tokio::sync::mpsc::{self, Sender};
use tokio::sync::Mutex;
use tokio::time;
struct Fork;
struct Philosopher {
name: String,
// left_fork: ...
// right_fork: ...
// thoughts: ...
}
impl Philosopher {
async fn think(&self) {
self.thoughts
.send(format!("Эврика! {} сгенерировал(а) новую идею!", &self.name))
.await
.unwrap();
}
async fn eat(&self) {
// Пытаемся до тех пор, пока не получим обе вилки
println!("{} ест...", &self.name);
time::sleep(time::Duration::from_millis(5)).await;
}
}
static PHILOSOPHERS: &[&str] =
&["Сократ", "Гипатия", "Платон", "Аристотель", "Пифагор"];
#[tokio::main]
async fn main() {
// Создаем вилки
// Создаем философов
// Каждый философ размышляет и ест 100 раз
// Выводим размышления философов
}
Для работы с асинхронным Rust рекомендуется использовать tokio:
[package]
name = "dining-philosophers-async"
version = "0.1.0"
edition = "2021"
[dependencies]
tokio = { version = "1.26.0", features = ["sync", "time", "macros", "rt-multi-thread"] }
Подсказка: на этот раз вам придется использовать Mutex и модуль mpsc из tokio.
Решение:
Чат
В этом упражнении мы используем новые знания для разработки приложения чата. У нас есть сервер, к которому подключаются клиенты и в котором они публикуют свои сообщения. Клиент читает пользовательские сообщения через стандартный ввод и отправляет их на сервер. Сервер передает (broadcast) сообщение всем клиентам.
Для реализации этого функционала мы будем использовать широковещательный канал на сервере и tokio_websockets для взаимодействия между клиентом и сервером.
Создайте новый проект и добавьте следующие зависимости в Cargo.toml:
[package]
name = "chat-async"
version = "0.1.0"
edition = "2021"
[dependencies]
futures-util = { version = "0.3.30", features = ["sink"] }
http = "1.0.0"
tokio = { version = "1.28.1", features = ["full"] }
tokio-websockets = { version = "0.5.1", features = ["client", "fastrand", "server", "sha1_smol"] }
Необходимые API
Вам потребуются следующие функции из tokio и tokio_websockets. Потратьте несколько минут для ознакомления со следующими API:
- StreamExt::next(), реализуемый
WebSocketStream- для асинхронного чтения сообщений из потока веб-сокетов - SinkExt::send(), реализуемый
WebSocketStream- для асинхронной отправки сообщений в поток веб-сокетов - Lines::next_line() - для асинхронного чтения сообщений пользователя через стандартный ввод
- Sender::subscribe() - для подписки на широковещательный канал
Два бинарника
Как правило, в проекте может быть только один исполняемый файл (binary) и один файл src/main.rs. Нам требуется два бинарника. Один для клиента и еще один для сервера. Теоретически их можно сделать двумя отдельными проектами, но мы поместим оба бинарника в один проект. Для того, чтобы это работало, клиент и сервер должны находиться в директории src/bin (см. документацию).
Скопируйте следующий код сервера и клиента в src/bin/server.rs и src/bin/client.rs, соответственно.
// src/bin/server.rs
use futures_util::sink::SinkExt;
use futures_util::stream::StreamExt;
use std::error::Error;
use std::net::SocketAddr;
use tokio::net::{TcpListener, TcpStream};
use tokio::sync::broadcast::{channel, Sender};
use tokio_websockets::{Message, ServerBuilder, WebSocketStream};
async fn handle_connection(
addr: SocketAddr,
mut ws_stream: WebSocketStream<TcpStream>,
bcast_tx: Sender<String>,
) -> Result<(), Box<dyn Error + Send + Sync>> {
todo!("реализуй меня")
}
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error + Send + Sync>> {
let (bcast_tx, _) = channel(16);
let listener = TcpListener::bind("127.0.0.1:2000").await?;
println!("Запросы принимаются на порту 2000");
loop {
let (socket, addr) = listener.accept().await?;
println!("Запрос от {addr:?}");
let bcast_tx = bcast_tx.clone();
tokio::spawn(async move {
// Оборачиваем сырой поток TCP в веб-сокет
let ws_stream = ServerBuilder::new().accept(socket).await?;
handle_connection(addr, ws_stream, bcast_tx).await
});
}
}
// src/bin/client.rs
use futures_util::stream::StreamExt;
use futures_util::SinkExt;
use http::Uri;
use tokio::io::{AsyncBufReadExt, BufReader};
use tokio_websockets::{ClientBuilder, Message};
#[tokio::main]
async fn main() -> Result<(), tokio_websockets::Error> {
let (mut ws_stream, _) =
ClientBuilder::from_uri(Uri::from_static("ws://127.0.0.1:2000"))
.connect()
.await?;
let stdin = tokio::io::stdin();
let mut stdin = BufReader::new(stdin).lines();
todo!("реализуй меня")
}
Запуск бинарников
Команда для запуска сервера:
cargo run --bin server
Команда для запуска клиента:
cargo run --bin client
Задачи
- реализовать функцию
handle_connectionвsrc/bin/server.rs- подсказка: используйте
tokio::select!для параллельного выполнения двух задач в бесконечном цикле. Одна задача получает сообщения от клиента и передает их другим клиентам. Другая - отправляет клиенту сообщения, полученные от сервера
- подсказка: используйте
- завершите функцию
mainвsrc/bin/client.rs- подсказка: также используйте
tokio::select!в бесконечном цикле для параллельного выполнения двух задач: 1) чтение сообщений пользователя из стандартного ввода и их отправка серверу; 2) получение сообщений от сервера и их отображение
- подсказка: также используйте
- опционально: измените код для передачи сообщений всем клиентам, кроме отправителя
Решение:
Happy coding!