WebRTC
Что такое WebRTC?
WebRTC (Web Real-Time Communication - коммуникация в режиме реального времени) - это API (Application Programming Interface - программный интерфейс приложения) и протокол. Протокол WebRTC - это набор правил, позволяющий двум агентам WebRTC (браузерам) вести двунаправленную (bi-directional) безопасную коммуникацию в реальном времени. WebRTC API позволяет разработчикам использовать протокол WebRTC. WebRTC API в настоящее время определен только для JavaScript.
Возможно, вам уже известна другая пара с похожим взаимодействием HTTP и Fetch API. В нашем случае протокол WebRTC - это HTTP, а WebRTC API - это Fetch API.
Протокол WebRTC поддерживается рабочей группой rtcweb IETF. WebRTC API задокументирован в W3C как webrtc.
Зачем изучать WebRTC?
Если попытаться кратко описать особенности WebRTC, получится вот такой список. Притом он не является исчерпывающим, это просто примеры интересных характеристик, с которыми вы встретитесь, изучая WebRTC. Не волнуйтесь, если не знакомы с какими-то терминами, все они будут раскрыты далее:
- Открытый стандарт
- Разные реализации
- Доступность в браузерах
- Обязательное шифрование
- Отображение NAT (NAT Traversal)
- Перепрофилирование существующих технологий
- Контроль перегрузки (congestion control)
- Низкая задержка (на уровне долей секунды, sub-second latency)
Протокол WebRTC - это собрание других технологий
В процессе установки соединения с помощью WebRTC можно выделить 4 этапа:
- Сигнализация (signalling)
- Подключение (установка соединения) (connection)
- Безопасность (securing)
- Коммуникация (взаимодействие) (communication)
Переходы между этапами происходят последовательно. Обязательным условием для начала следующего этапа является успешное завершение предыдущего.
Интересный факт о WebRTC - каждый этап состоит из большого количества других протоколов. Для создания WebRTC было объединено множество существующих технологий. В этом смысле WebRTC - это комбинация и конфигурация хорошо известных технологий, появившихся в начале 2000-х годов.
Каждому из перечисленных 4 этапов посвящен отдельный раздел, но для начала давайте рассмотрим их на самом высоком уровне. Поскольку этапы зависят друг от друга, в дальнейшем это облегчит объяснение и понимание назначения каждого из них.
Сигнализация: как пиры (peers) находят друг друга
При запуске WebRTC агент не знает, с кем и по поводу чего будет происходит коммуникация. И именно сигнализация дает нам прозрачность. Это первый этап и его назначение – подготовка вызова (звонка) (call) для того, чтобы два агента WebRTC могли начать коммуникацию.
Сигнализация осуществляется с помощью существующего протокола SDP (Session Description Protocol - протокол описания сессии). Напомним, что SDP – это текстовый протокол. Каждое сообщение SDP состоит из нескольких пар ключ/значение и содержит список "медиа разделов" (media sections). SDP, которыми обмениваются агенты WebRTC, содержит следующую инф�ормацию:
-IP и порты, по которым можно получить доступ к агенту (candidates - кандидаты);
- какое количество аудио и видео треков хочет отправить агент;
- какие аудио и видео кодеки поддерживаются каждым агентом;
- значения, используемые в процессе подключения (
uFrag/uPwd); - значения, используемые для обеспечения безопасности (certificate fingerprint - отпечаток сертификата).
Обратите внимание, что сигнализация, как правило, происходит вне WebRTC; WebRTC, обычно, не используется для передачи сигнальных сообщений (signalling messages). Для передачи SDP между подключенными пирами могут использоваться такие технологии, как конечные точки REST, веб-сокеты или прокси аутентификации (authentication proxies).
Подключение и отображение NAT с помощью STUN/TURN
В процессе сигнализации агенты WebRTC получают достаточно информации для того, чтобы попытаться выполнить подключение. Для этого используется другая технология под названием ICE.
ICE (Interactive Connectivity Establishment - установка интерактивного соединения) - это еще один протокол, предшествующий появлению WebRTC. ICE позволяет устанавливать соединение между двумя агентами. Агенты могут находиться в одной (локальной) сети или в разных концах света. ICE - это решение для установки прямого соединения без центрального сервера.
Настоящее волшебство - это "отображение NAT" и серверы STUN/TURN. И это все, что вам нужно для коммуникации с агентом ICE, находящимся в другой подсети (subnet).
После успешного подключения ICE WebRTC приступает к установке зашифрованного транспортного канала. Он используется для передачи аудио, видео и других данных.
Обеспечение безопасности канала передачи данных с помощью DTLS и SRTP
После того, как мы установили двунаправленный канал коммуникации (с помощью ICE), нам необходимо сделать этот канал безопасным. Это делается с помощью двух протоколов, также разработанных задолго до появления WebRTC. Первый протокол - это DTLS (Datagram Transport Layer Security - протокол датаграмм безопасности транспортного уровня), который является просто TLS поверх UDP. TLS - это криптографический протокол, который используется для безопасной коммуникации через HTTPS. Второй протокол - это SRTP (Secure Real-time Transport Protocol - используется для безопасной передачи данных в реальном времени).
Сначала WebRTC выполняет рукопожатие (handshake) DTLS с помощью соединения ICE. В отличие от HTTPS, WebRTC не использует центральный орган (central authority) для проверки сертификатов. Вместо этого WebRTC проверяет, что сертификат, переданный через DTLS, совпадает с отпечатком (fingerprint, мы подробно поговорим об этом в разделе, посвященном безопасности), переданным в процессе сигнализации. В дальнейшем DTLS-подключение используется для передачи сообщений по DataChannel (каналу передачи данных).
Для передачи аудио/видео используется другой протокол под названием RTP (Real-time Transport Protocol - протокол передачи данных в реальном времени). Пакеты, передаваемые по RTP, защищаются с помощью SRTP. Сессия SRTP начинается с извлечения ключей из установленной сессии DTLS.
Поздравляем! Если предыдущие этапы завершились успешно, у нас имеется двунаправленная и безопа�сная коммуникация. Если соединение между агентами WebRTC является стабильным, можно приступать к обмену данными. К сожалению, в реальном мире мы постоянно сталкиваемся с потерей пакетов и ограниченной пропускной способностью, о чем мы поговорим в следующем разделе.
Коммуникация между пирами через RTP и SCTP
Итак, мы установили безопасное двунаправленное соединение между двумя агентами WebRTC и наконец-то приступаем к коммуникации! Для этого используется два протокола: RTP и SCTP (Stream Control Transmission Protocol — протокол передачи с управлением потоком). RTP используется для передачи медиа, зашифрованного с помощью SRTP, а SCTP - нужен для отправки и приема сообщений по DataChannel, зашифрованных с помощью DTLS.
RTP является довольно минималистичным, но он предоставляет все необходимое дл�я потоковой передачи данных в реальном времени. Гибкость RTP позволяет разработчикам решать проблемы, связанные с задержкой, потерей данных и перегрузкой, самыми разнообразными способами.
Последним протоколом в стеке является SCTP. Он предоставляет множество настроек, связанных с доставкой сообщений. Мы, например, можем пожертвовать надежностью и правильным порядком доставки пакетов данных в пользу низкой задержки доставки. Именно она является критически важной для коммуникации в реальном времени.
WebRTC - коллекция протоколов
На первый взгляд WebRTC может показаться перепроектированным (over-engineered). Но мы можем ему это простить, так как с его помощью мы можем решать большое количество проблем. Гениальность WebRTC заключается в его скромности: он не пытается решать все задачи самостоятельно. Вместо этого, он объединяет множество существующих специализированных технологий в единое целое.
Э�то позволяет исследовать и изучать каждую часть по-отдельности. Очень подходящее сравнение WebRTC – это оркестратор (orchestrator) большого количества других протоколов.

Как работает WebRTC (API)?
В этом разделе мы поговорим о том, как протокол WebRTC реализован в JavaScript API. Это не подробный обзор, а всего лишь попытка нарисовать общую картину того, что происходит в процессе коммуникации в реальном времени.
new RTCPeerConnection
RTCPeerConnection - "WebRTC-сессия" верхнего уровня. Она объединяет все упомянутые выше протоколы. Выполняется подготовка всех необходимых подсистем, но пока еще ничего не происходит.
addTrack
addTrack создает новый поток данных (stream) RTP. Для этого потока генерируется случайный источник синхронизации (Synchronization Source, SSRC). Поток находится внутри описания сессии (Session Description, SDP) (в медиаразделе), генерируемого createOffer. Каждый вызов addTrack создает новый SSRC и медиараздел.
После установки SRTP-сессии и шифрования, эти медиапакеты начинают передаваться через ICE.
createDataChannel
createDataChannel создает новый SCTP-поток при его отсутствии. По умолчанию SCTP отключен, он включается только при запросе любой стороной канала передачи данных.
После установки DTLS-сессии и шифрования, эти пакеты с данными начинают передаваться через ICE.
createOffer
createOffer генерирует описание локального состояния (local state) сессии, передаваемого удаленному (в значении "находящемуся далеко", remote) пиру.
Вызов createOffer ничего не меняет для локального пира.
setLocalDescription
setLocalDescription фиксирует (commits) запрошенные (произведенные) изменения. addTrack, createDataChannel и аналогичные вызовы являются временными до вызова setLocalDescription. setLocalDescription вызывается со значением, сгенерированным createOffer.
setRemoteDescription
setRemoteDescription – способ информирования локального агента о состоянии удаленных кандидатов. Это сигна�лизация, выполняемая JavaScript API.
После вызова setRemoteDescription обеими сторонами, агенты WebRTC имеют достаточно информации для начала коммуникации P2P (Peer-To-Peer - равный к равному).
addIceCandidate
addIceCandidate позволяет WebRTC-агенту добавлять дополнительных кандидатов ICE в любое время. Данный интерфейс отправляет кандидата ICE прямо в подсистему ICE и не оказывает никакого другого влияния на общее соединение.
ontrack
ontrack - это функция обратного вызова (callback), которая вызывается при получении RTP-пакета от удаленного пира. Входящие пакеты помещаются в описание сессии, которое передается в setRemoteDescription.
oniceconnectionstatechange
oniceconnectionstatechange - это колбэк, который вызывается при изменении состояния агента ICE. Так мы получаем уведомления об установке и завершении соединения.
onconnectionstatechange
onconnectionstatechange - это комбинация состояния ICE и DTLS. Мы можем использовать этот коллбэк для получения уведомления об успешной установке ICE и DTLS.
Сигнализация
В момент своего создания агент WebRTC ничего не знает о другом пире. Он не имеет ни малейшего представления о том, с кем будет установлено соединение и чем они будут обмениваться. Сигнализация - это подготовка к совершению звонка. После обмена необходимой информацией агенты могут общаться друг с другом напрямую.
Сообщения, передаваемые в процессе сигнализации - это просто текст. Агентам неважно, как они передаются (какой транспорт для этого используется). Как правило, они передаются через веб-сокеты, но это необязательно.
Как это работает?
WebRTC использует протокол SDP. Через него два агента обмениваются состоянием, необходимым для установки соединения. Сам протокол легко читать. Сложность возникает при изучении значений, генерируемых WebRTC.
Этот протокол не является специфичным для WebRTC. Сначала мы рассмотрим SDP в отрыве от WebRTC, а после – его применение в WebRTC.
Что такое протокол описания сессии?
Протокол описания сессии (Session Description Protocol, SDP) определен в RFC 8866. Он состоит из пар ключ/значение. Каждая пара находится на отдельной строке. Он похож на файл INI. Описание сессии состоит из 0 и более описаний медиа (media descriptions). Об описании сессии можно думать как о массиве описаний медиа.
Описание медиа, обычно, относится к определенному потоку медиаданных. Поэтому, если мы хотим описать звонок, содержащий 3 видеопотока и 2 аудиопотока, у нас будет 5 описаний медиа.
Изучение SDP
Каждая новая строка в описании сессии начинается с одного сим�вола - ключа. Затем следует знак равенства. Все остальное (до новой строки) - это значение.
SDP определяет все ключи, которые являются валидными. Для ключей могут использоваться только буквы латинского алфавита. Каждый ключ имеет определенное значение.
Рассмотрим небольшой кусочек описания сессии:
a=first-value
a=second-value
У нас есть 2 строки и они обе начинаются с ключа a. Значением первой строки является first-value, а второй - second-value.
Ключи SDP, используемые в WebRTC
Не все ключи, определенные в SDP, используются в WebRTC. Используются только ключи, фигурирующие в протоколе установки сессии JavaScript (JavaScript Session Establishment Protocol, JSEP), определенном в RFC 8829. Прямо сейчас достаточно понимать следующие 7 ключей:
v- версия (version) (0);o- источник (origin), уникальный идентификатор, полезный для повторной установки соединения;s- название сессии (-);t- расчет времени (timing) (0 0);m- описание медиа (m=<media> <port> <proto> <fmt> ...);a- атрибут, свободное текстовое поле. Наиболее часто встречающийся ключ;c- данные о подключении (IN IP4 0.0.0.0).
Медиаописания в описании сессии
Описание сессии может состоять из неограниченного количества описаний медиа.
Определение медиаописания состоит из списка форматов (formats). Эти форматы соответствуют типам полезной нагрузки RTP (RTP Payload Types). Кодек определяется атрибутом со значением rtpmap в описании сессии. Каждое описание медиа может состоять из неограниченного количества атрибутов.
Рассмотрим еще один кусочек описания сессии:
v=0
m=audio 4000 RTP/AVP 111
a=rtpmap:111 OPUS/48000/2
m=video 4000 RTP/AVP 96
a=rtpmap:96 VP8/90000
a=my-sdp-value
У нас есть два описания медиа: одно описывает аудио с форматом 111, другое - видео с форматом 96. Первое описание содержит один атрибут. Этот атрибут определяет (привязывает, maps) тип полезной нагрузки 111 как Opus. Второе описание содержит два атрибута. Первый атрибут определяет тип полезной нагрузки 96 как VP8, второй - содержит кастомное значение my-sdp-value.
Полный пример
В следующем примере представлены все ключи SDP, используемые в WebRTC:
v=0
o=- 0 0 IN IP4 127.0.0.1
s=-
c=IN IP4 127.0.0.1
t=0 0
m=audio 4000 RTP/AVP 111
a=rtpmap:111 OPUS/48000/2
m=video 4002 RTP/AVP 96
a=rtpmap:96 VP8/90000
v,o,s,cиtопределены, но они не влияют на сессиюWebRTC;- у нас имеется два описания медиа. Одно с типом
audio, другое -video; - каждое описание содержит один атрибут. Он определяет детали конвейера (pipeline)
RTP.
Как SDP и WebRTC работают вместе
Следующим кусочком пазла является понимание того, как WebRTC использует SDP.
Что такое предложения и ответы?
WebRTC использует модель предложение/ответ (offer/answer). Это означает, что если один агент "предлагает" начать коммуникацию, другой агент "отвечает", хочет он этого или нет.
Это позволяет отвечающему отклонить неподдерживаемые им кодеки, указанные в описаниях медиа. Таким способом пиры определяют, какими форматами данных они будут обмениваться.
Трансиверы
Трансиверы (приемопередатчики, transceivers) - это специфическая для WebRTC концепция, которую вы встретите в API. Их основной задачей является преобразование "описания медиа" в JavaScript API. Каждое описание медиа становится трансивером. При каждом создании трансивера в локальное описание сессии добавляется новое описание медиа.
Каждое описание сессии в WebRTC имеет атрибут, определяющий направление передачи данных (direction). Это позволяет агенту объявлять такие вещи, как, например, "Я собираюсь отправить тебе этот кодек, но не хочу ничего получать в ответ". Валидными значениями направления являются:
send(sendonly, sending - отправка);recv(recvonly, receiving - получение);sendrecv(отправка и получение);inactive(неактивное состояние).
Значения SDP, используемые в WebRTC
Ниже представлен список некоторых часто встречающихся атрибутов описания сессии, используемых агентами. Многие из этих значений контролируют подсистемы, которые мы еще не обсуждали (но �скоро обсудим).
group:BUNDLE
Сборка (bundling) - это передача нескольких типов трафика через одно соединение (часто это называют "батчингом", batching). В некоторых реализациях WebRTC для каждого медиапотока выделяется отдельное соединение. Сборка является предпочтительной.
fingerprint:sha-256
Это хеш сертификата, используемого пиром для DTLS. После завершения рукопожатия DTLS мы сравниваем хеш с сертификатом для подтверждения того, что мы общаемся с тем, кого ожидаем.
setup:
Контролирует поведение агента DTLS. Определяет, чем является агент (клиентом или сервером), после установки ICE. Возможные значения:
setup:active- запуск в качестве клиентаDTLS;setup:passive- запуск в качестве сервераDTLS;setup:actpass- просим другого агентаWebRTCсделать выбор.
ice-ufrag
Значение фрагмента пользователя (user fragment) для агента ICE. Используется для аутентификации трафика ICE.
ice-pwd
Пароль для агента ICE. Используется для аутентификации трафика ICE.
rtpmap
Используется для определения связи между конкретным кодеком и типом полезной нагрузки RTP. Типы полезной нагрузки являются динамическими, поэтому для каждого вызова его инициатор выбирает типы полезной нагрузки для каждого кодека.
fmtp
Определяет дополнительные значения типа полезной нагрузки. Может использоваться для настройки профиля видео или кодировки.
candidate
Кандидат ICE, полученный от агента ICE. Один из адресов, по которым доступен агент WebRTC.
ssrc
Определяет конкретный трек медиапотока (media stream track).
label - это идентификатор потока. mslabel - идентификатор контейнера, который может содержать несколько потоков.
Пример описания сессии
Полное описание сессии, генерируемое клиентом WebRTC:
v=0
o=- 3546004397921447048 1596742744 IN IP4 0.0.0.0
s=-
t=0 0
a=fingerprint:sha-256 0F:74:31:25:CB:A2:13:EC:28:6F:6D:2C:61:FF:5D:C2:BC:B9:DB:3D:98:14:8D:1A:BB:EA:33:0C:A4:60:A8:8E
a=group:BUNDLE 0 1
m=audio 9 UDP/TLS/RTP/SAVPF 111
c=IN IP4 0.0.0.0
a=setup:active
a=mid:0
a=ice-ufrag:CsxzEWmoKpJyscFj
a=ice-pwd:mktpbhgREmjEwUFSIJyPINPUhgDqJlSd
a=rtcp-mux
a=rtcp-rsize
a=rtpmap:111 opus/48000/2
a=fmtp:111 minptime=10;useinbandfec=1
a=ssrc:350842737 cname:yvKPspsHcYcwGFTw
a=ssrc:350842737 msid:yvKPspsHcYcwGFTw DfQnKjQQuwceLFdV
a=ssrc:350842737 mslabel:yvKPspsHcYcwGFTw
a=ssrc:350842737 label:DfQnKjQQuwceLFdV
a=msid:yvKPspsHcYcwGFTw DfQnKjQQuwceLFdV
a=sendrecv
a=candidate:foundation 1 udp 2130706431 192.168.1.1 53165 typ host generation 0
a=candidate:foundation 2 udp 2130706431 192.168.1.1 53165 typ host generation 0
a=candidate:foundation 1 udp 1694498815 1.2.3.4 57336 typ srflx raddr 0.0.0.0 rport 57336 generation 0
a=candidate:foundation 2 udp 1694498815 1.2.3.4 57336 typ srflx raddr 0.0.0.0 rport 57336 generation 0
a=end-of-candidates
m=video 9 UDP/TLS/RTP/SAVPF 96
c=IN IP4 0.0.0.0
a=setup:active
a=mid:1
a=ice-ufrag:CsxzEWmoKpJyscFj
a=ice-pwd:mktpbhgREmjEwUFSIJyPINPUhgDqJlSd
a=rtcp-mux
a=rtcp-rsize
a=rtpmap:96 VP8/90000
a=ssrc:2180035812 cname:XHbOTNRFnLtesHwJ
a=ssrc:2180035812 msid:XHbOTNRFnLtesHwJ JgtwEhBWNEiOnhuW
a=ssrc:2180035812 mslabel:XHbOTNRFnLtesHwJ
a=ssrc:2180035812 label:JgtwEhBWNEiOnhuW
a=msid:XHbOTNRFnLtesHwJ JgtwEhBWNEiOnhuW
a=sendrecv
Вот что мы должны понять из этого сообщения:
- у нас имеется два медиараздела: один для аудио и один для видео;
- оба являются трансиверами
sendrecv. Мы получаем два потока и можем отправить два потока в ответ; - у нас имеются кандидаты
ICEи детали аутентификации, что позволяет предпринять попытку установить соединение; - у нас имеется отпечаток сертификата, что позволяет сделать звонок безопасным.
Подключение
Большинство разрабатываемых сегодня приложений реализует клиент-серверную архитектуру подключения. Такая архитектура предполагает наличие сервера с известным и стабильным транспортным адресом (transport address) (IP и порт). Клиент отправляет запрос, а сервер на него отвечает.
В WebRTC используется другая архитектура - одноранговая сеть (Peer-to-Peer, P2P). В такой сети задача установки соединения распределяется между пирами. Это обусловлено тем, что транспортный адрес не может быть определен заранее, и может меняться в �течение сессии (session). WebRTC собирает всю доступную информацию и делает многое для обеспечения возможности двунаправленной коммуникации (bi-directional communication) между агентами.
Установка такого соединения - задача не из простых. Агенты могут находиться в разных сетях, т.е. не иметь прямого соединения. И даже если оно есть, могут быть другие проблемы. Например, клиенты могут использовать разные протоколы (UPD <-> TCP) или разные версии IP (IPv4 <-> IPv6).
Несмотря на это, WebRTC предоставляет некоторые преимущества по сравнению с клиент-серверной архитектурой.
Уменьшение размера передаваемых данных
Поскольку обмен данными между агентами осуществляется напрямую, нам не нужно "платить" за сервер, предназначенный для ретрансляции (перенаправления) этих данных.
Снижение задержки
Прямая коммуникация является более быстрой. Когда пользователь вынужден отправлять данные через сервер, ретрансляция увеличивает задержку.
Повышение безопасности
Прямая коммуникация является более безопасной. Поскольку сервер не участвует в передаче данных, пользователи могут быть уверены, что данные не будут расшифрованы, пока не достигнут адресата.
Как это работает?
Описанный выше процесс называется установкой интерактивного соединения (Interactive Connectivity Establishment, ICE).
ICE - это протокол, который пытается определить наилучший способ для установки соединения между двумя агентами. Каждый агент публикует (publishes) путь, по которому он может быть достигнут (reachable). Такие пути называются кандидатами (candidates). По сути, кандидат - это транспортный адрес, который один агент считает достижимым для другого агента. Затем ICE определяет наиболее подходящую пару кандидатов.
Для того, чтобы убедиться в необходимости ICE, нужно понимать, какие трудности нам приходится преодолевать на пути установки интерактивного соединения.
Ограничения реального мира
Основное назначение ICE - преодоление ограничений, накладываемых на подключение реальным миром. Кратко обсудим эти ограничения.
Разные сети
В большинстве случаев второй агент будет находиться в другой сети. Как правило, соединение устанавливается между агентами, находящимися в разных сетях.
Ниже представлен граф двух независимых сетей, соединенных вместе через публичный Интернет. В каждой сети у нас имеется два хоста.

Для хостов, находящихся в одной сети, установка соединения - простая задача. Коммуникацию между 192.168.0.1 -> 192.168.0.2 легко организовать. Такие хосты могут общаться друг с другом без посторонней помощи.
Однако, хост, использующий Router B, не имеет возможности общаться с хостами, использующими Router A. Как определить разницу между 192.168.0.1 из Router A и таким же IP из Router B? Эти IP являются частными (закрытыми для внешнего мира, private)! Хост из Router B может отправлять данные в Router A, но запрос завершится ничем. Как Router A определить, какому хосту следует передавать сообщение?
Ограничения протоколов
В одних сетях запрещена передача трафика по UDP, в других - по TCP. Некоторые сети могут иметь очень низкую максимальную единицу передачи данных (Maximum Transmission Unit, MTU). Существует большое количество настроек сетей, которые могут сделать коммуникацию по меньшей мере затруднительной.
Правила межсетевых экранов
Еще одной проблемой является "глубокая проверка пакетов" ("Deep Packet Inspection") и другая фильтраци�я сетевого трафика. Некоторые сетевые администраторы применяют такое программное обеспечение в отношении каждого пакета. Во многих случаях это ПО не понимает WebRTC, считает пакеты WebRTC подозрительными пакетами UDP, передаваемыми по порту, не входящему в белый список (whitelist).
Отображение NAT
Отображение результата преобразования сетевых адресов (Network Address Translation, NAT) (NAT Mapping) - это магия, которая делает подключение WebRTC возможным. Это то, благодаря чему два пира из разных сетей могут общаться друг с другом. Рассмотрим, как работает отображение NAT.
NAT не использует ретранслятор, прокси или сервер. У нас есть Agent 1 и Agent 2, которые находятся в разных сетях. Несмотря на это, они могут обмениваться данными. Вот как это выглядит:
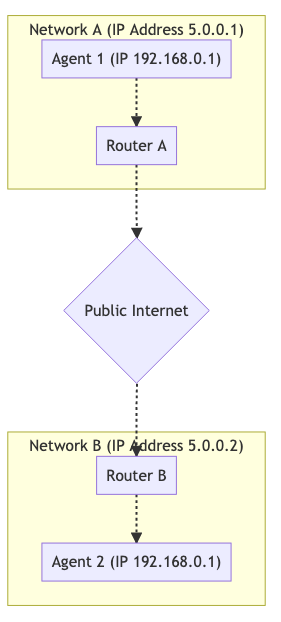
Для обеспечения возможности подобной ком�муникации мы прибегаем к помощи отображения NAT. Agent 1 использует порт 7000 для установки соединения WebRTC с Agent 2. 192.168.0.1:7000 привязывается (bind) к 5.0.0.1:7000. Это позволяет Agent 2 "достигать" Agent 1, отправляя пакеты по адресу 5.0.0.1:7000. Создание отображения NAT похоже на автоматическую версию переадресации портов (port forwarding) в роутере.
Обратной стороной NAT является то, что не существует единой формы отображения (например, статической переадресации портов), в разных сетях поведение может быть различным. Интернет-провайдеры и производители аппаратного обеспечения могут делать это по-разному. В некоторых случаях сетевые администраторы вообще могут его отключить.
Хорошей новостью является то, что все эти особенности мониторятся и учитываются, что позволяет агенту ICE создавать отображение NAT и его атрибуты.
Документом, описывающим данный процесс, является RFC 4787.
Создание отображения NAT
Создание отображения - самая легкая часть. Отображение создается, когда мы отправляем пакет по адресу, находящемуся за пределами нашей сети. Отображение NAT - это просто временные публичные IP и порт, занимаемый нашим NAT. Исходящие сообщения переписываются таким образом, что адресом их источника (source address) становится созданное отображение. При отправке сообщения в отображение, оно автоматически перенаправляется в хост внутри создавшего его NAT. И этот процесс становится сложным, когда речь заходит о деталях создания отображения.
Варианты создания отображения NAT
Создание отображение делится на три категории.
Автономное (не зависящее от конечной точки, endpoint-independent) отображение
Для каждого отправителя внутри NAT создается отдельное отображение. �Если мы отправляем два пакета по двум удаленным адресам, для обоих пакетов используется одно и то же отображение. Оба удаленных хоста будут видеть один и тот же IP и порт источника. При получении ответов от хостов, они передаются в один и тот же локальный обработчик (local listener).
Это лучший сценарий. Для осуществления звонка необходимо, чтобы хотя бы одна сторона была такого типа.
Зависящее от адреса (address dependent) отображение
Новое отображение создается при отправке пакета по новому адресу. Если мы отправляем два пакета в два разных хоста, создается два отображения. Если мы отправляем два пакета в один удаленный хост, но разные порты, создается ОДНО отображение.
Зависящее от адреса и порта отображение
Новое отображение создается, если отличаются удаленный IP или порт. Если мы отправляем два пакета в один удаленный хост, но в разные порты, создается два отображения.
Варианты фильтрации отображения NAT
Фильтрация отображения - это правила, определяющие, кто может использовать отображение. Существует три возможных варианта:
Автономная фильтрация
Отображение может использовать кто угодно. Мы можем делиться им с другими пирами, и они смогут отправлять в него трафик.
Зависящая от адреса фильтрация
Отображение может использовать только создавший его хост. Если мы отправляем пакет в хост A, он может отправить в ответ любое количество пакетов. Если хост B отправит пакет в это отображение, данный пакет будет игнорироваться (will be ignored).
Зависящая от адреса и порта фильтрация
Отображение может использоваться только создавшим его хостом и портом. Если мы отправляем пакет в хост A:5000, он может ответить любым количеством пакетов. Пакет, отправленный хостом A:5001, будет игнорироваться.
Обновление отображения NAT
Рекомендуется уничтожать (destroy) отображение, которое не используется в течение пяти минут, но это зависит от Интернет-провайдеров и производителей "железа".
STUN
Утилиты прохождения сессий для NAT (Session Traversal Utilities for NAT, STUN) - это протокол, предназначенный для работы с NAT. Он определен в RFC 8489, в котором также определяется структура пакетов STUN. Протокол STUN также используется ICE/TURN.
STUN позволяет программно создавать отображения NAT. До STUN мы могли создавать отображения, но не могли получать информацию о созданных IP и портах. STUN не только позволяет создавать отображения, он также предоставляет информацию, которой можно поделиться с другими для того, чтобы они могли передавать данные в отображение.
Начнем с базового описания STUN. Позже мы рассмотрим, как STUN используется в ICE и TURN. Рассмотрим процесс запрос/ответ (request/response) для создания отображения, а также поговорим о том, как получить информацию об IP и портах. Данный процесс происходит, когда у нас есть сервер stun: в путях (urls) ICE для WebRTC PeerConnection (например, new RTCPeerConnection({ iceServers: [{ urls: ['stun:stun.l.google.com:19302'] }] })). STUN помогает конечной точке, находящейся за NAT, получить детали о созданном отображении, путем отправки запроса к серверу STUN о предоставлении информации о том, что он видит извне (observes).
Структура протокола
Каждый пакет STUN имеет следующую структуру:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|0 0| STUN Message Type | Message Length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Magic Cookie |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
| Transaction ID (96 bits) |
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Data |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
STUN Message Type
Тип пакета. В данный момент нас интересует следующее:
- запрос на привязку или связывание (Binding Request) -
0x0001; - ответ на привязку (Binding Response) -
0x0101.
Для создания отображения NAT мы выполняем Binding Request. Сервер отправляет нам Binding Response.
Message Length
Длина раздела Data (размер данных). Этот раздел содержит данные, определенные в Message Type.
Magic Cookie
Фиксированное значение 0x2112A442 в сетевом порядке байтов (network byte order). Это помогает отличать STUN от других протоколов.
Transaction ID
96-битный идентификатор, уникально определяющий запрос/ответ. Это помогает определять пары запросов и ответов.
Data
Данные содержат список атрибутов STUN. Атрибут STUN имеет следующую структуру:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type | Length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Value (variable) ....
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
STUN Binding Request не использует атрибуты. Это означает, что в запросе содержится только заголовок (header).
STUN Binding Response использует XOR-MAPPED-ADDRESS (0x0020). Данный атрибут содержит IP и порт из отображения NAT.
Создание отображения NAT
"Цена" создания отображения NAT с помощью STUN - один запрос. Мы отправляем Binding Request серверу STUN. Он возвращает нам Binding Response. Binding Response содержит Mapped Address. Mapped Address - то, как сервер STUN видит отображение NAT. Mapped Address - то, что может использоваться другой стороной для отправки данных в наш адрес.
Mapped Address - это наш Public IP (публичный адрес) или Server Reflexive Candidate в терминологии WebRTC.
Определение типа NAT
К сожалению, Mapped Address может использоваться не во всех случаях. Если NAT является зависящим от адреса, мы можем получать данные только от сервера STUN. В этом случае сообщения, отправленные другой стороной в Mapped Address, будут потерян�ы (will be dropped). Это делает Mapped Address бесполезным. И проблема эта решается тем, что сервер STUN перенаправляет пакеты к пиру. Такое решение называется TURN.
RFC 5780 описывает метод для определения типа NAT. Это позволяет заранее определить возможность установки прямого соединения.
TURN
Отображение NAT с помощью ретрансляторов (Traversal Using Relays around NAT, TURN), определенный в RFC 8656, это решение проблемы отсутствия возможности прямого соединения. Такое может произойти при несовместимости типов NAT или использовании разных протоколов агентами. TURN также может использоваться для обеспечения конфиденциальности. Создавая коммуникацию с помощью TURN, мы обфусцируем (скрываем) настоящие адреса клиентов.
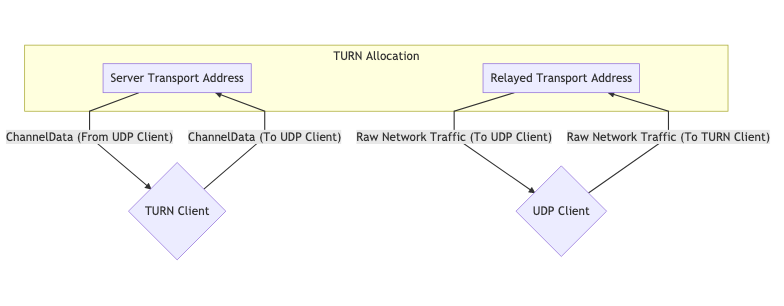
TURN использует выделенный сервер. Этот сервер является прокси для клиента. Клиент подключается к серверу TURN и с�оздает Allocation (размещение). Ему выделяется временный IP/порт/протокол, который может использоваться для передачи данных. Данный обработчик называется Relayed Transport Address. Это своего рода адрес переадресации (forwarding address), который может использоваться другой стороной для передачи трафика через TURN. Для каждого пира создается отдельный Relayed Transport Address, что требует предоставления Permission (разрешения) на коммуникацию.
При передаче трафика через TURN, он передается через Relayed Transport Address. При получении трафика удаленным пиром, он видит, что трафик пришел от TURN.
Жизненный цикл TURN
Поговорим о том, что должен сделать клиент, который хочет создать размещение в TURN. Коммуникация с тем, кто использует TURN, не требует совершения дополнительных действий. Другой пир просто получает IP и порт, которые могут использоваться для передачи данных.
Размещения
Размещения - ядро TURN. Allocation - "сессия TURN". Для создания размещения в TURN мы обращаемся к Server Transport Address сервер TURN (портом по умолчанию является 3478).
При создании размещения серверу необходимо предоставить следующую информацию:
- имя пользователя/пароль - создание размещения требует аутентификации;
- транспорт, используемый размещением - транспортный протокол между сервером (
Server Transport Address) и пирами:UDPилиTCP; Even-Port- мы можем запрашивать последовательность портов для нескольких размещений, не относящихся кWebRTC.
При успешном запросе мы получаем от сервера TURN ответ со следующими атрибутами в разделе Data:
XOR-MAPPED-ADDRESS-Mapped AddressклиентаTURN(TURN Client). При отправке данных вRelayed Transport Address, они перенаправляются в этот адрес;RELAYED-ADDRESS- адрес, передаваемый другим клиентам. При отправке пакета по этому адресу, он передается клиентуTURN;LIFETIME- сколько времени осталось до уничтожения размещенияTURN. Время жизни размещения может быть увеличено через отправку за�просаRefresh.
Разрешения
Удаленный хост не может отправлять данные в наш Relayed Transport Address до тех пор, пока мы не предоставим ему разрешение. При создании разрешения мы говорим серверу TURN, что указанным IP и порту разрешен входящий трафик.
Удаленный хост должен предоставить нам IP и порт в том виде, в каком они отображаются на сервере TURN. Это означает, что он должен отправить STUN Binding Request. Распространенной ошибкой является отправка такого запроса не тому серверу TURN. После отправки запроса удаленный хост обращается к нам с просьбой о предоставлении разрешения.
Предположим, что мы хотим создать разрешение для хоста, находящегося за Address Dependent Mapping. Если мы получим Mapped Address от другого сервера TURN, весь входящий трафик будет потерян. При каждом взаимодействии с другим хостом создается новое отображение. Время жизни разрешения составляет 5 минут.
SendIndication/ChannelData
Эти сообщения предназначены для клиента TURN для отправки сообщений удаленному пиру.
SendIndication - самодостаточное сообщение. Вн�утри него находятся данные для отправки, а также адресат. Отправка большого количества сообщений удаленному пиру является расточительной. При отправке 1000 сообщений IP адрес удаленного пира будет повторен 1000 раз!
ChannelData позволяет отправлять данные без дублирования IP-адреса. Мы создаем канал (channel) с IP и портом. При отправке сообщения в нем указывается ChannelId, а IP и порт заполняются сервером. Это позволяет уменьшить нагрузку на сервер при отправке большого количества сообщений.
Обновление
Размещения уничтожаются автоматически. Для сохранения размещения его LIFETIME (время жизни) должно периодически обновляться.
Использование TURN
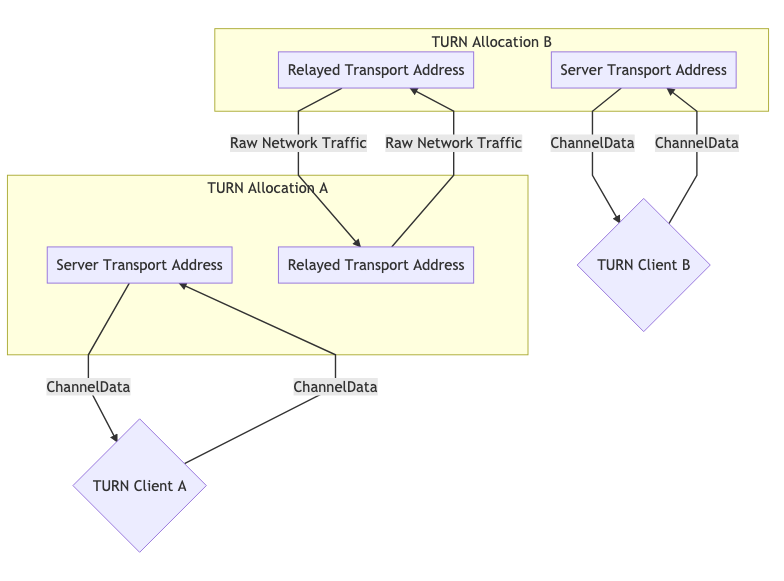
TURN может использоваться в двух формах. Как правило, у нас имеется один пир, выступающий в роли "клиента TURN", и другой сторона, обращающаяся к "клиенту" напрямую. В некоторых случаях может потребоваться использовать TURN на обеих сторонах, например, по причине того, что обе стороны находятся в сетях, блокирующих UDP, поэтому соединение с соответствующими серверами TURN выполняется через TCP.
Одна аллокация TURN для коммуникации
Две аллокации TURN для коммуникации
ICE
ICE - то, как WebRTC подключает двух агентов. Этот протокол определен в RFC 8445. ICE - протокол для установки соединения. Он описывает все возможные маршруты (routes) между двумя пирами и обеспечивает стабильность подключения.
Эти роуты называются Candidate Pairs (парами кандидатов) и представляют собой пару локального и удаленного транспортных адресов. Вот где в игру вступают STUN и TURN. Эти адреса могут быть нашими локальными IP и портом, отображением NAT или Relayed Transport Address. Каждая сторона собирает адреса, которые она хочет (и может) использовать, передает их другой стороне и выполняет попытку подключения.
Два агента ICE взаимодействуют с помощью пинг-пакетов (ping packets) ICE (которые формально называются проверками подключения - connectivity checks) для установки соединения. После установки соединения стороны могут обмениваться данными. Это похоже на использование обычных веб-сокетов. Все необходимые проверки выполняются с помощью протокола STUN.
Создание агента ICE
Агент ICE может быть Controlling (управляющим) или Controlled (управляемым). Управляющий агент - это тот, который выбирает Candidate Pair. Как правило, пир, отправляющий предложение об установке соединения (offer), является управляющей стороной.
Каждая сторона должна иметь user fragment и password. Стороны должны обменяться этими значениями до начала проверок подключения. user fragment отправляется в виде обычного текста и может использоваться для демультиплексирования (demuxing) нескольких сеансов ICE. password используется для генерации атрибута MESSAGE-INTEGRITY. В конце каждого пакета STUN имеется атрибут с хешем содержимого пакета - password используется в качестве ключа. Это позволяет аутентифицировать пакет, т.е. убедиться в том, что он не был подменен или модифицирован в процессе передачи.
В случае с WebRTC эти значения передаются через Session Description (описание сессии), о котором рассказывалось в предыдущем разделе.
Сбор кандидатов (Candidate Gathering)
Теперь нам необходимо собрать все адреса, по которым достижимы агенты. Эти адреса называются кандидатами.
Хост
Кандидат хоста предоставляется локальным интерфейсом. Это может быть UDP или TCP.
mDNS
Кандидат mDNS похож на кандидата хоста, но его IP-адрес скрываетс�я. Вместо IP-адреса другой стороне предоставляется UUID в качестве названия хоста. После этого мы настраиваем многоадресный обработчик (multicast listener), который отвечает на запросы к опубликованному UUID.
Если мы находимся в одной сети с агентом, мы можем найти друг друга через мультикаст (multicast). Если мы и агент находимся в разных сетях, установить соединение не получится. Как минимум, до тех пор, пока администратор сети явно не разрешит такую передачу пакетов.
Это позволяет обеспечить конфиденциальность. В случае с кандидатом хоста пользователь видит наш IP адрес через WebRTC (даже не пытаясь установить соединение), но в случае с кандидатом mDNS он получит только случайный UUID.
Server Reflexive
Кандидат от сервера (Server Reflexive Candidate) генерируется сервером STUN в ответ на STUN Binding Request.
При получении STUN Binding Response содержащийся в нем XOR-MAPPED-ADDRESS - это наш кандидат от сервера.
Peer Reflexive
�Кандидат от пира (Peer Reflexive Candidate) - это когда мы получаем входящий запрос от неизвестного адреса . Поскольку ICE - это протокол с аутентификацией, мы знаем, что трафик является валидным. Это всего лишь означает, что удаленный пир общается с нами с неизвестного адреса.
Это обычно происходит при общении Host Candidate с Server Reflexive Candidate. Поскольку мы общаемся за пределами нашей подсети, создается новое отображение NAT. Помните, мы говорили о том, что проверки подключения - это на самом деле пакеты STUN? Формат ответа STUN позволяет пиру вернуть адрес кандидата от пира (peer-reflexive address).
Relay
Релейный кандидат генерируется сервером TURN.
После первоначального рукопожатия (handshake) мы получаем RELAYED-ADDRESS - наш релейный кандидат.
Проверки подключения
Теперь мы знаем user fragment, password и кандидатов удаленного агента. Выполняем попытку подключения! Кандидаты разбиваются попарно. Поэтому если у нас было три кандидата от каждой стороны, мы получаем девять пар кандидатов.
Вот как это выглядит:

Выбор кандидатов
Управляющий и управляемый агенты начинают передавать трафик через каждую пару. Это требуется, когда один агент находится за Address Dependent Mapping, что приводит к созданию Peer Reflexive Candidate.
Каждая Candidate Pair (пара кандидатов), которая "видит" трафик, становится парой Valid Candidate (валидных кандидатов). Управляющий агент берет одного Valid Candidate и выдвигает (nominate) его. Выдвинутые сторонами кандидаты становятся Nominated Pair (номинированной парой). Агенты снова пытаются установить двунаправленную коммуникацию. При достижении успеха, Nominated Pair становится Selected Candidate Pair (выбранной или избранной парой кандидатов). Эта пара используется на протяжении оставшейся части сессии.
Перезагрузка
Если Selected Candidate Pair прекращает работу по какой-либо причине (истек срок жизни отображения NAT, упал сервер TURN) агент ICE переходит в состояние Failed. Оба агента могут быть перезапущены, и процесс начнется сначала.
Безопасность
Каждое соединение WebRTC аутентифицируется и шифруется. Это позволяет быть уверенным в том, что третья сторона не видит того, что мы отправляем, и не может добавлять (вставлять) фиктивные сообщения. Также можно быть уверенным, что агент, генерирующий описание сессии - это действительно тот, с кем мы хотим общаться.
Очень важно, чтобы никто не мог подменять сообщения. Не страшно, если третья сторона прочитает описание сессии во время передачи. Однако, WebRTC не предоставляет защиты от ее модификации. Злоумышленник может осуществить атаку "человек посередине" (атака посредника) путем подмены кандидатов ICE и обновления отпечатка сертификата.
Как это работает?
Для обеспечения безопасности соединения WebRTC использует 2 существующих протокола: DTLS и SRTP.
DTLS позволяет выполнять подготовку сессии и безопасно обмениваться данными между пирами. Он похож на TLS, который используется в HTTPS, но в качестве протокола транспортного уровня DTLS использует UDP вместо TCP. Это означает, что DTLS не гарантирует надежную доставку сообщений. SRTP был специально разработан для безопасного обмена медиаданными. Он предоставляет несколько оптимизаций по сравнению с DTLS.
Сначала используется DTLS. Он выполняет рукопожатие через соединение ICE. DTLS - это клиент-серверный протокол, поэтому одна из сторон должна инициировать рукопожатие. Роли "клиент/сервер" определяются в процессе сигнализации. В ходе рукопожатия DTLS каждая сторона генерирует сертификат. После завершения рукопожатия каждый сертификат сравнивается с его хешем, содержащимся в описании сессии. Это позволяет убедиться в том, что рукопожатие произошло с ожидаемым агентом. Затем соединение DTLS может использоваться для коммуникации с помощью DataChannel.
Для создания сессии SRTP мы инициализируем ее с помощью ключей, сгенерированных DTLS. SRTP не предоставляет механизма рукопожатия, поэтому подготовка соединения осуществляется с помощью внешних ключей. После установки SRTP-соединения стороны могут обмениваться зашифрованными медиаданными.
Security 101
Давайте познакомимся с терминами, употребляемыми в криптографии.
Обычный текст и зашифрованный текст
Обычный текст (plaintext) - это входные данные для шифрования. Зашифрованный текст (ciphertext) - это результат шифрования.
Шифрование
Шифрование (шифр, cipher) - это последовательность операций по преобразованию обычного текста в зашифрованный. Шифр может быть сохранен для последующей расшифровки зашифрованного текста. Как правило, шифр имеет ключ, меняющий его поведение. Данный процесс также называется encrypting (шифрование) и decrypting (расшифровка).
Примером простого шифра является ROT13. Каждая буква исходного текста сдвигается на 13 символов вперед. Для расшифровки каждая буква сдвигается на 13 символов назад. Обычный текст HELLO становится зашифрованным текстом URYYB. В данном случае шифр - это ROT, а ключ - 13.
Хеш-функции
Хеш-функция (hash function) - это необратимый (однонаправленный) процесс преобразования входных данных в хеш (digest - фарш, мешанина). Для одних и тех же входных данных всегда получается одинаковый результат. Важно, чтобы результат был необратимым. Результат не должен позволять определить входные данные. Хеширование позволяет убедиться в том, что сообщение не было подменено.
Простой функцией хеширования будет функция, пропускающая каждую вторую букву. HELLO станет HLO. Мы не можем "вернуться" к HELLO, но мы можем убедиться, что HELLO совпадает с хешем.
Публичные и приватные ключи
Криптография на основе публичного/приватного ключей (public/private key) описывает тип шифрования, используемого DTLS и SRTP. В такой системе у нас имеется два ключа: публичный (открытый) и приватный (закрытый). Публичный ключ используется для шифрования и его можно передавать другим лицам. Приватный ключ используется для расшифровки и должен быть известен только нам. Расшифровать зашифрованное сообщение можно только с помощью соответствующего приватного ключа.
Протокол Диффи-Хеллмана
Протокол Диффи — Хеллмана (Diffie–Hellman Protocol) позволяет двум пользователям, которые никогда не встречались, безопасно создавать общие секреты через Интернет. Пользователь A может отправлять секреты пользователю B, не опас�аясь прослушки (eavesdropping). Это зависит от сложности решения проблемы дискретного логарифмирования. Это делает возможным рукопожатие DTLS.
Псевдослучайная функция
Псевдослучайная функция (Pseudorandom Function, PRF) - предварительно определенная функция, генерирующая значения, которые на первый взгляд кажутся случайными. Она может принимать несколько входных значений и генерировать один результат.
Функция формирования ключа
Формирование (деривация) ключа (key derivation) - это разновидность псевдослучайной функции. Данная функция используется для усиления ключа. Одним из наиболее распространенных паттернов является растяжка (растяжение) ключа (key stretching).
Предположим, что у нас имеется ключ размером 8 байтов. Мы можем использовать KDF для того, чтобы сделать его сильнее (длиннее).
Однократно используемое число
Однократно используемое число (nonce) - это дополнительные входные данные для шифрования. Оно используется для получения разных результатов при шифровании одного и того же сообщения. Для каждого сообщения используется уникальный nonce.
Код аутентификации сообщения
Код аутентификации сообщения (message authentication code) - это хеш, помещаемый в конец сообщения. MAC позволяет идентифицировать источник сообщения.
Ротация ключей
Ротация ключей (key rotation) - это практика периодической замены ключей. Это позволяет снизить ущерб от возможной кражи (утечки) ключа, т.е. добиться того, что украденный или раскрытый другим способом ключ может использоваться для расшифровки лишь ограниченного количества сообщений.
DTLS
DTLS позволяет двум пирам устанавливать безопасное соединение без предварительной настройки. Даже если кто-то будет прослушивать соединение, он не сможет расшифровать сообщения.
Для того, чтобы коммуникация между клиентом и сервером DTLS, стало возможной, они должны прийти к соглашению о шифре и ключе. Эти значения определяются в процессе рукопожатия. В ходе рукопожатия сообщения представлены в виде обычного текста. После того, как клиент или сервер обменяются достаточным количеством информации для начала шифрования, отправляется Change Cipher Spec. После этого все последующие сообщения подвергаются шифрованию.
Формат пакета
Каждый пакет DTLS начинается с заголовка.
Тип содержимого
Тип содержимого (content type) может быть одним из:
20-Change Chipher Spec;22- рукопожатие (Handshake);23- данные приложения (Application Data).
Handshake используется для обмена информацией, необходимой для начала сессии. Change Chipher Spec используется для уведомления другой стороны о начале шифрования сообщений. Application Data - это сами зашифрованные сообщения.
Версия
Версия (version) может иметь значение 0x0000feff (для DTLS v1.0) или 0x0000fefd (для DTLS v1.2). Версии 1.1 не существует.
Эпоха
Эпоха (epoch) начинается с 0 и принимает значение 1 после Change Chipher Spec. Любые сообщения с "ненулевой эпохой" зашифровываются.
Последовательный номер
Последовательный номер (sequence number) используется для сохранения порядка сообщений. При каждой отправке сообщения данный номер увеличивается. При увеличении эпохи, данный номер обнуляется.
Длина сообщения и полезная нагрузка
Полезная нагрузка (payload) - это конкретный тип содержимого. Для Application Data полезной нагрузкой являются зашифрованные данные. Для Handshake полезная нагрузка зависит от вида сообщения. Длина сообщения (length) определяет размер полезной нагрузки.
Рукопожатие
В процессе рукопожатия клиент и сервер обмениваются серией сообщений. Эти сообщения группируются в пакеты (flights). Каждый пакет может содержать н�есколько сообщений или только одно. Пакет считается полученным только после доставки всех содержащихся в нем сообщений. Далее мы рассмотрим назначение каждого сообщения.
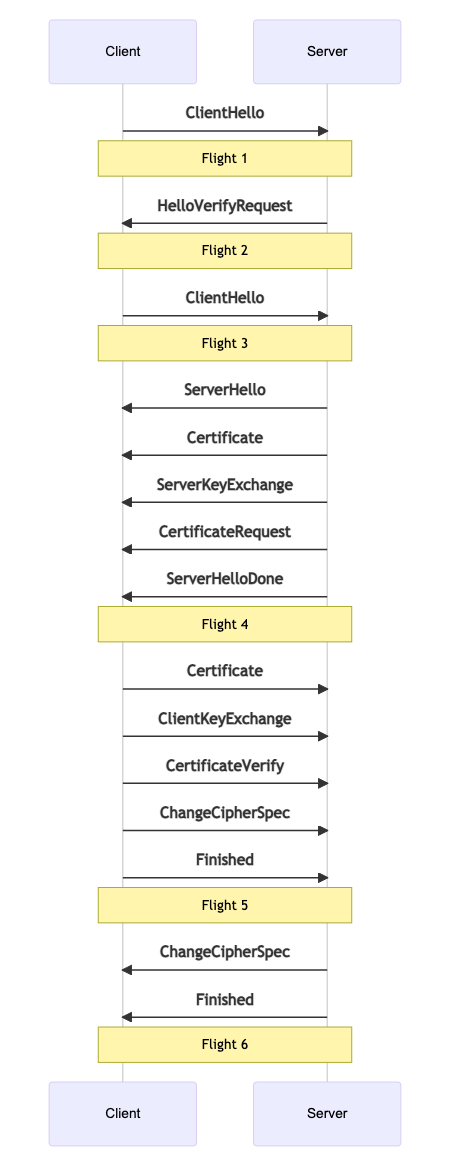
ClientHello
ClientHello - это начальное сообщение от клиента. Оно содержит перечень атрибутов. Эти атрибуты сообщают серверу шифр и возможности, поддерживаемые клиентом. Данный шифр также используется в качестве шифра SCTP. ClientHello также содержит случайные данные, которые впоследствии используются для генерации ключей сессии.
HelloVerifyRequest
HelloVerifyRequest - это сообщение от сервера клиенту. Оно позволяет убедиться, что клиент действительно имел намерение отправить ClientHello. После этого клиент снова отправляет ClientHello, но уже с токеном из HelloVerifyRequest.
ServerHello
ServerHello - это ответ сервера с настройками сессии. Он содержит шифр и случайные данные.
Certificate
Certificate содержит сертификат для клиента или сервера. Сертификат используется для идентификации другой стороны коммуникации. После окон�чания рукопожатия мы проверяем, что хеш сертификата совпадает с его отпечатком в SessionDescription.
ServerKeyExchange/ClientKeyExchange
Эти сообщения используются для передачи публичного ключа. При инициализации клиент и сервер генерируют пару ключей. После рукопожатия эти значения используются для генерации Pre-Master Secret.
CertificateRequest
CertificateRequest - сообщение от сервера клиенту о желании первого получить сертификат. Сервер может просить (request) или требовать (require) получение сертификата.
ServerHelloDone
ServerHelloDone уведомляет клиента о завершении рукопожатия сервером.
CertificateVerify
CertificateVerify - так отправитель подтверждает наличие у него приватного ключа из сообщения с сертификатом.
ChangeCipherSpec
ChangeCipherSpec информирует получателя о том, что последующие сообщения будут зашифрованными.
Finished
Finished является зашифрованным и содержит хеш всех предыдущих сообщений. Это позволяет убедиться в отсутствии модификации рукопожатия.
Генерация ключей
После завершения рукопожатия мы можем отправлять зашифрованные данные. Шифр выбирается сервером и содержится в его ServerHello. Но как выбирается ключ?
Сначала мы генерируем Pre-Master Secret. Для получения этого значения используется протокол Диффи-Хелмана для ключей, обмениваемых с помощью ServerKeyExchange и ClientKeyExchange. Детали зависят от выбранного шифра.
Затем генерируется Master Secret. Каждая версия DTLS имеет определенную псевдослучайную функцию. Для DTLS v1.2 функция "берет" Pre-Master Secret и случайные значения из ClientHello и ServerHello. Результатом выполнения псевдослучайной функции является Master Secret. Master Secret - это значение, которое используется для шифра.
Обмен данными
Рабочей лошадкой DTLS является ApplicationData. После получения инициализированного шифра мы можем шифровать и передавать сообщения.
Сообщения ApplicationData используют заголовок DTLS, как описывалось ранее. Payload заполняется зашифрованным текстом. Теперь у нас имеется сессия DTLS и мы можем общаться безопасно.
SRTP
SRTP - это протокол, разработанный специально для шифрования пакетов RTP. Для начала сессии SRTP необходимо определить ключи и шифр. В отличии от DTLS здесь у нас нет механизма рукопожатия. Все настройки и ключи генерируются в ходе рукопожатия DTLS.
DTLS предоставляет отдельный API для экспорта ключей с целью их использования в других процессах. Данный API определяется в RFC 5705.
Создание сессии
SRTP определяет функцию деривации ключей, которая применяется в отношении входных данных. При создании сессии SRTP входные данные пропускаются через эту функцию для генерации ключей для шифра SRTP. После этого можно переходить к обработке данных.
Обмен медиаданными
Каждый пакет RTP имеет 16-битный SequenceNumber (последовательный номер). Этот номер используется для сохранения правильного порядка доставки пакетов (последовательные номера напоминают первичные ключи - primary keys). В ходе сессии этот номер автоматически увеличивается. Для этого используется специальный счетчик (rollover counter).
При шифровании пакета SRTP использует счетчик и последовательный номер в качестве одноразового значения (nonce). Это позволяет добиться того, что даже при повторной отправке сообщения, его зашифрованный текст будет разным. Это защищает от идентификации паттерна атакующим, а также от выполнения повторной атаки.
Коммуникация в реальном времени
Сети - это ограничительный фактор для коммуникации в реальном времени. В идеальном мире размер передаваемых данных неограничен и пакеты доставляются мгновенно. В реальном мире это не так. Возможности сетей являются ограниченными, условия могут измениться в любое время. Измерение и мониторинг сетей также представляет собой сложную задачу. Мы получаем разное поведение в зависимости от "железа", программного обеспечения и их настроек.
В случае с коммуникацией в реальном времени существует еще одна проблема, которой нет в других средах. Для разработчика медленная работа сайта в некоторых сетях не является серьезной проблемой. До тех пор, пока все данные приходят, пользователи счастливы. Однако в WebRTC "старые" данные являются бесполезными. Никого не интересует, что было сказано на конференции пять секунд назад. Поэтому при разработке систем, работающих в режиме рального времени, зачастую приходится выбирать между задержкой в передаче и размером передаваемых данных.
Какие атрибуты делают сети сложными?
Код, который эффективно работает во всех сетях, является сложным. Необходимо учитывать множество разных факторов, которые могут неочевидным образом влиять друг на друга. Ниже представлен список наиболее общих задач, с решением которых сталкиваются разработчики.
Пропускная способность
Пропускная способность (bandwidth) - это количество данных, которые можно передать по сети. Важно понимать, что данная величина не является постоянной. Пропускная способность зависит от нагрузки, т.е. от количества людей, использующих этот маршрут (роут).
Время передачи и время в пути туда и обратно
Время передачи (transmission time) - это время достижения пакетом пункта назначения. Как и пропускная способность, это значение не является константным. Время передачи может меняться в ходе сессии.
transmission_time = receive_time - send_time
Для расчета время передачи нам нужны часы на стороне отправителя и получателя, синхронизированные с точностью до миллисекунд. Даже небольшая разница может привести к ненадежному измерению времени. Поскольку WebRTC функционирует в высокогетерогенных средах, достижение совершенной синхронизации между хостами является почти невозможным.
Время туда и обратно (round trip time) - это попытка решения проблемы синхронизации.
Вместо использования распределенных часов пир WebRTC отправляет специальный пакет, содержащий время в sendertime1. Второй пир получает пакет, фиксирует время и отправляет пакет обратно. После получения пакета отправителем, он вычитает в�ремя, записанное в sendertime1, из текущего времени sendertime2. Эта разница во времени называется временем в пути туда и обратно.
rtt = sendertime2 - sendertime1
Половина времени туда и обратно считается хорошим приближением времени передачи. Этот подход имеет некоторые недостатки. При его использовании мы исходим из предположения, что отправка и получение пакета занимают равное время. Однако в сотовых сетях операции по отправке и получению могут быть несимметричными по времени. Вы могли замечать, что скорость передачи данных на телефоне почти всегда меньше скорости загрузки данных.
transmission_time = rtt/2
Технические детали измерения времени туда и обратно подробно описаны в следующем разделе.
Джиттер
Причиной джиттера (jitter) является разное время передачи пакетов. Пакеты могут запаздывать и прибывать группами.
Потеря пакетов
Потеря пакетов (packets loss) - это когда сообщения теряются при передаче, т.е. не доходят до адресата. Потеря может быть постоянной или случайной. Это может быть связано с типом сети, например, спутник�овая или Wi-Fi. Это также может быть связано с ПО, встретившимся на пути сообщения.
Максимальная единица передачи
Максимальная единица передачи (maximum transmission unit) - это максимальный размер единичного пакета. Сети не позволяют отправлять одно гигантское сообщение. На уровне протокола сообщения разбиваются (split) на более мелкие пакеты.
MTU также различается в зависимости от выбранного маршрута. Для определения MTU можно использовать протокол Исследования MTU по пути.
Перегрузка
Перегрузка (congestion) возникает при достижении лимитов сети. Обычно, это связано с достижением предельной пропускной способности текущего роута. Или это может быть связано с временными ограничениями, накладываемыми вашим Интернет-провайдером.
Перегрузка проявляется по-разному. Не существует стандартного поведения. В большинстве случаев при возникновении перегрузки лишние пакеты начинают игнорироваться. В други�х случаях происходит буферизация. Это приводит к увеличению времени передачи. В перегруженных сетях также можно наблюдать усиление джиттера. Все, о чем мы тут говорим, – быстро развивающаяся сфера и в ней продолжают появляться новые алгоритмы для определения перегрузки.
Динамичность
Сети являются невероятно динамичными, их условия меняются очень быстро. Во время звонка мы можем отправлять и получать сотни тысяч пакетов. Эти пакеты будут проходить через несколько переходов (посредников, ретрансляторов) (hops). Эти переходы будут распределены между миллионами других пользователей. Даже в локальной сети мы можем загружать фильм в формате HD или наше устройство может загружать обновление во время звонка.
Поддержка стабильности звонка является не такой простой задачей, как исследование сети при инициализации. Необходимо проводить постоянн�ые вычисления. Также необходимо учитывать все факторы, на которые оказывают влияние сетевое "железо" и ПО.
Решение проблемы потери данных
Потеря пакетов - это первая задача, которую необходимо решить при разработке системы коммуникации в реальном времени. Существует множество способов это сделать, каждый со своими плюсами и минусами. Это зависит от того, что мы отправляем и насколько критичной является задержка. Также следует отметить, что не всякая потеря является фатальной. Потеря незначительного количества видеоданных будет незаметна для человеческого глаза. Однако потеря текста сообщения является фатальной.
Предположим, что мы отправили 10 пакетов и пакеты 5 и 6 были потеряны. Давайте разберем, как можно решить эту проблему.
Acknowledgments
Acknowledgments (подтверждения) - это спосо�б, которым получатель сообщает отправителю о получении каждого пакета. Отправитель узнает о потере пакета при получении повторного подтверждения о пакете, который не является последним. Когда отправитель получает ACK для пакета 4 дважды, он понимает, что пакет 5 был потерян.
Selective Acknowledgments
Selective Acknowledgments (выборочные подтверждения) - это улучшение обычных подтверждений. Получатель может отправить SACK с подтверждениями для нескольких пакетов и таким образом уведомить отправителя о потере пакетов. Отправитель получает SACK для пакетов 4 и 7 и понимает, что пакеты 5 и 6 были потеряны. В ответ он повторно отправляет потерянные пакеты.
Negative Acknowledgments
Negative Acknowledgments (негативные подтверждения) решают проблему противоположным образом. Вместо уведомления отправителя о полученном, получатель уведомляет его о том, что было потерян�о. В нашем случае NACK отправляется для пакетов 5 и 6. Отправитель знает только о пакетах, которые необходимо отправить повторно.
Forward Error Correction
Forward Error Correction (превентивное исправление ошибок) пытается решить проблему потери данных заблаговременно. Отправитель отправляет дополнительные данных, чтобы потеря пакетов не повлияла на результат. Одним из примеров FEC является код Рида-Соломона.
Это уменьшает задержку/сложность отправки и получения подтверждений. FEC является пустой тратой полосы пропускания в случае, если потеря данных в сети близка к нулю.
Решение проблемы джиттера
Джиттер присутствует в большинстве сетей. Даже внутри LAN у нас много устройст�в, отправляющих данные с разной скоростью. Вы можете легко увидеть джиттер, "пропинговав" (pinging) другое устройство с помощью команды ping, и наблюдая за флуктуациями, происходящими во время пути туда и обратно (rtt).
Для преодоления джиттера клиенты используют JitterBuffer. Он обеспечивает постоянную скорость доставки пакетов. Недостатком является задержка, которую JitterBuffer добавляет к пакетам, которые прибыли слишком рано. А его преимущество в том, что опоздавшие пакеты не вызывают джиттер. Представьте, что в течение звонка вы видите такое время прибытия пакетов:
* time=1.46 ms
* time=1.93 ms
* time=1.57 ms
* time=1.55 ms
* time=1.54 ms
* time=1.72 ms
* time=1.45 ms
* time=1.73 ms
* time=1.80 ms
В данном случае хорошим выбором будет 1,8 мс. Пакеты, которые будут прибывать позднее, смогут использовать наше окно задержки или временной зазор (window of latency). Пакеты, прибывающие рано, будут немного задержаны и затем помещены в окно вместе с опоздавшими пакетами. Это означает, что мы избавляемся от дрожания и обеспечиваем плавную доставку сообщений клиенту.
Операция JitterBuffer
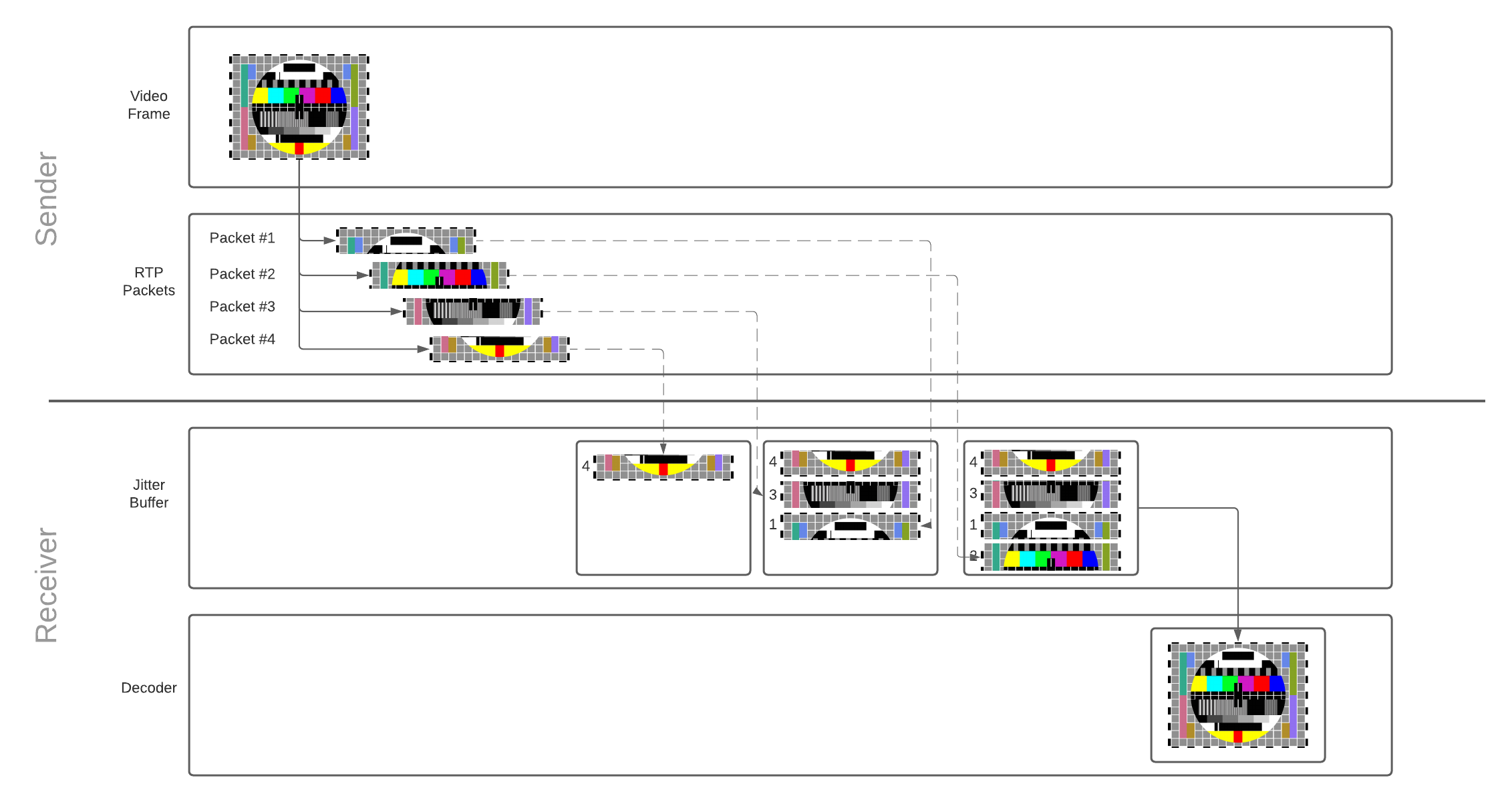
Каждый пакет помещается в буфер при получении. Когда пакетов становится достаточно для реконструкции фрейма (кадра), фрейм высвобождается (release) из буфера и отправляется на расшифровку (decoding). Декодер, в свою очередь, расшифровывает и отрисовывает видеофрейм на экране пользователя. Поскольку буфер имеет ограниченную вместимость, пакеты, которые находятся там слишком долго, отклоняются (discarded).
jitterBufferDelay предоставляет хорошие данные о производительности сети и ее влиянии на плавность воспроизведения. jitterBufferDelay является частью WebRTC statictics API, относящейся к входящему потоку получателя. Задержка (delay) определяет время, которое видеофреймы проводят в буфере перед отправкой декодеру. Большая задержка означает, что наша сеть сильно нагружена.
Определение перегрузки
Перед решением проблемы перегрузки сети, необходимо эту перегрузку определить. Для этого используется congestion controller (контроллер перегрузки). Это сложная вещь, которая в настоящее время активно развивается. Все время публикуются и тестируются новые алгоритмы. На самом высоком уровне все они делают одно и то же. Контроллер перегрузки выполняет оценку пропускной способности на основе некоторых входных данных, например:
- потеря пакетов - потеря пакетов в перегруженных сетях увеличивается;
- джиттер - по мере увеличения нагрузки время доставки пакетов становится все более нестабильным;
- время туда и обратно - время туда и обратно при высокой нагрузке увеличивается;
- явные уведомления о перегрузке (explicit congestion notification) - новейшие сети могут помечать пакеты как находящиеся под угрозой потери для уменьшения нагрузки.
В процессе звонка эти значения должны все время измеряться. Использование сети может увеличиваться и уменьшаться, следовательно, будет меняться пропускная способность.
Решение проблемы перегрузки
После измерения пропускной способности нам необходимо настроить то, что мы отправляем. Настройки зависят о�т типа передаваемых данных.
Снижение скорости передачи данных
Ограничение скорости передачи данных - первое решение проблемы перегрузки. Контроллер нагрузки предоставляет расчеты, а отправитель ограничивает скорость.
В большинстве случаев используется именно этот способ. В случае с TCP это берет на себя операционная система, процесс является полностью прозрачным для пользователей и разработчиков.
Уменьшение количества передаваемых данных
В некоторых случаях мы можем отправлять меньшее количество информации для удовлетворения лимитов. В WebRTC мы не можем снижать скорость передачи данных.
Если нам не хватае�т пропускной способности, мы можем, например, снизить качество передаваемого видео. Для этого требуется тесная связь между видеокодером и контроллером перегрузок.
Обмен медиаданными
WebRTC позволяет отправлять и получать неограниченное количество аудио и видеопотоков. Мы можем добавлять и удалять эти потоки в любое время в течение сессии. Потоки могут быть автономными или объединяться в один. Мы можем отправлять видео захвата экрана и добавлять к нему аудио и видео из вебкамеры.
Протокол WebRTC не зависит от кодеков. Лежащий в его основе транспорт поддерживает все, даже то, чего еще не существует. Однако агент, с которым мы общаемся, может не иметь инструментов, необходимых для принятия звонка.
WebRTC спроектирован для работы в динамичных условиях сетей. Во время звонка пропускная способность может увеличиваться и уменьшаться. Мы можем внезапно столкнуться с сильной потерей пакетов. Протокол предоставляет возможности �для решения этой проблемы. WebRTC реагирует на изменение условий сети и старается обеспечить наилучший опыт использования с учетом доступных ресурсов.
Как это работает?
WebRTC использует 2 протокола, RTP и RTCP, определенные в RFC 1889.
RTP - это протокол для передачи медиаданных. Он был разработан для передачи видео в реальном времени. Он не устанавливает никаких правил относительно задержки или надежности доставки пакетов, но предоставляет инструменты для их настройки. RTP предоставляет потоки, которые могут передаваться через одно соединение. Он также предоставляет информацию о времени отправки и порядке пакетов, необходимую для правильного формирования медиаконвейера (media pipeline).
RTCP - это протокол, содержащий метаданные о звонке. Формат протокола является очень гибким и позволяет добавлять любые метаданные. Это используется для сбора статистики о звонке. Также это может использоваться для обработки потери пакетов и реализации контроля перегрузки. Он предоставляет двунаправленную коммуникацию, автоматически адаптирующуюся к постоянно меняющимся сетевым условиям.
Задержка против качества
Обмен медиаданными в реальном времени всегда сопряжен с выбором между задержкой и качеством. Чем большую задержку мы можем себе позволить, тем выше будет качество медиа.
Ограничения реального мира
Это обусловлено ограничениями реального мира - характеристиками сети, которые необходимо учитывать.
Видео является сложным
Передача видео - сложный процесс. Для хранения 30-минутного несжатого 720 8-битного видео требуется около 110 Гб. В таких условиях конференция с четырьмя участниками является невозможной. Следовательно, нам нужен какой-то способ уменьшения размера видео и ответом является сжатие (compression). Однако, это имеет некоторые недостатки.
Video 101
Мы не будем рассматривать сжатие видео в подробностях. Мы рассмотрим его в степени, достаточной для понимания того, почему RTP спроектирован так, как спроектирован. Сжатие видео - это его кодировка, преобразование в другой формат, который требует меньшего количества битов для представления аналогичного видео.
Сжатие с потерей и без потери качества
Мы можем кодировать видео без потери (lossless compression) и с потерей (lossy compresion) качества. Поскол�ьку кодировка без потери требует большего количества данных для передачи пиру, увеличивая задержку и потерю пакетов, RTP, как правило, применяет кодировку с потерей, несмотря на то, что это приводит к снижению качества видео.
Внутри и межкадровое сжатие
Сжатие видео делится на 2 вида. Первый - это сжатие внутри кадра (или просто сжатие кадра, intra-frame compression). Такое сжатие уменьшает количество бит, используемых для описания единичного видеофрейма. Аналогичная техника используется для сжатия неподвижных (still) изображений, например, JPEG.
Второй тип - это межкадровое сжатие (inter-frame compression). Поскольку видео состоит из большого количества изображений (кадров, фреймов), мы ищем способы не отправлять одинаковую информацию дважды.
Типы межкадрового сжатия
Межкадровое сжатие делится на 3 типа:
- I-Frame - полное изображение, может кодироваться во что угодно;
- P-Frame - частичное изображение, содержащее только изменения предыдущего изображения;
- B-Frame - частичное изображение - совмещение предыдущего и будущего изображений.
Визуализация этих типов:
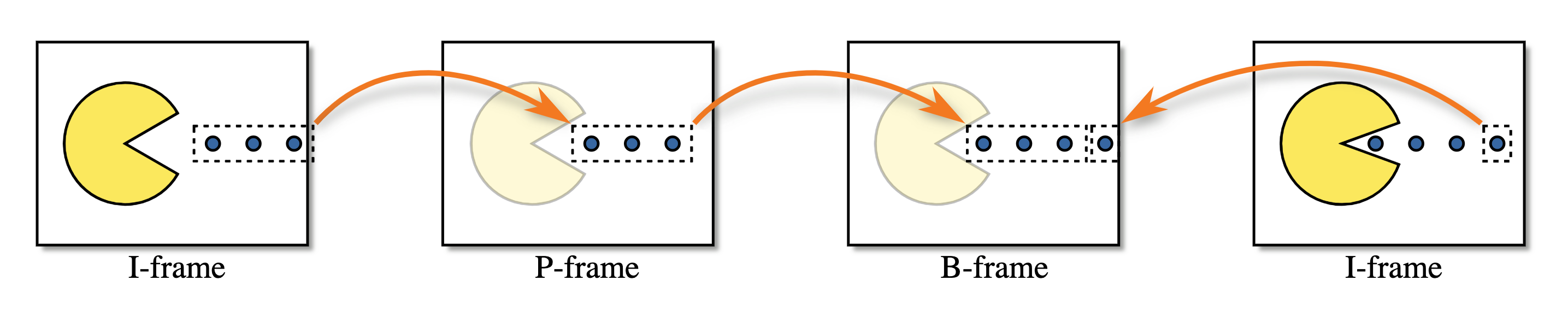
Видео является деликатным
Сжатие видео очень сильно зависит от его состояния, что делает сложным его передачу по сети. Что случится, если мы потеряем часть I-Frame? Откуда P-Frame знает, что модифицировать? С ростом сложности сжатия, вопросов становится все больше и больше. К счастью, RTP и RTCP предоставляют решение этих проблем.
RTP
Формат пакета
Каждый пакет RTP имеет следующую структуру:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|V=2|P|X| CC |M| PT | Sequence Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Timestamp |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Synchronization Source (SSRC) identifier |
+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+
| Contributing Source (CSRC) identifiers |
| .... |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Payload |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Version (V)
Version (версия) всегда имеет значение 2.
Padding (P)
Padding (заполнение) - логическое значение, определяющее, имеет ли полезная нагрузка заполнение.
Последний байт полезной нагрузки содержит количество байтов заполнения.
Extension (X)
Если установлен, заголовок RTP будет содержать расширения. Мы поговорим об этом позже.
CSRC count (CC)
Количество идентификаторов CSRC, следующих после SSRC, но перед полезной нагрузкой.
Marker (M)
Бит маркера не имеет предопределенного значения и может использоваться как угодно.
В некоторых случаях он устанавливается, когда пользователь что-нибудь говорит. Также он часто используется для индикации ключевого кадра (keyframe).
Payload Type (PT)
Payload Type (тип полезной нагрузки) - это уникальный идентификатор кодека, который используется данным пакетом.
Payload Type является динамическим. VP8 в одном звонке может отличаться от VP8 в другом звонке. Инициатор звонка (offerer) определяет связь между Payload Types и кодеками в Session Description (описании сессии).
Sequence Number
Sequence Number (последовательный номер) используется для упорядочивания пакетов в потоке. При каждой отправке пакета Sequence Number увеличивается на единицу.
RTP спроектирован таким образом, что получатель имеет возможность своевременно обнаруживать потерю пакетов.
Timestamp
Момент выборки (sampling instant) для данного пакета. Это не глобальные часы, а время, прошедшее с начала передачи потока. Несколько пакетов RTP могут иметь одинаковый Timestamp, если они, например, являются частью одного фрейма.
Synchronization Source (SSRC)
SSRC (источник синхронизации) - это уникальный идентификатор потока. Это позволяет передавать несколько медиапотоков через одно соединение RTP.
Contributing Source (CSRC)
CSRC (вспомогательный источник) обычно используется для индикаторов речи. Скажем, на сервере мы объединили несколько аудиопотоков в один RTP-поток. Далее мы используем это поле для определения того, что "входящие потоки A и C в данный момент разговаривают между собой".
Payload
Payload - это полезная нагрузка, фактически передаваемые данные.
RTCP
Формат пакета
Каждый пакет RTCP имеет следующую структуру:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|V=2|P| RC | PT | length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Payload |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Version (V)
Version все�гда имеет значение 2.
Padding (P)
Аналогично RTP.
Reception Report Count (RC)
Количество отчетов (reports) в данном пакете. Один пакет RTCP может содержать несколько событий (events).
Packet Type (PT)
Уникальный идентификатор типа пакета RTCP. Агент WebRTC не обязан поддерживать все типы, поддержка между агентами может отличаться. На практике можно встретить следующие типы:
192- полный запрос INTRA-frame (FIR);193- негативные подтверждения (NACK);200- отчет отправителя (sender report);201- отчет получателя (receiver report);205- общая обратная связь (feedback)RTP;206- обратная связь определенной полезной нагрузки.
Значимость каждого из этих типов пакетов будет описана ниже.
Полный запрос INTRA-frame (FIR) и Picture Loss Indication (PLI)
Сообщения FIR и PLI (обнар�ужение потери изображения) служат одной цели. Эти сообщения запрашивают у отправителя полный ключевой кадр. PLI используется, когда декодер получает частичные фреймы и не может их декодировать. Это может произойти из-за потери данных или ошибки декодера.
Согласно RFC 5104 FIR не должен использоваться при потере пакетов или фреймов. Это задача PLI. FIR запрашивает ключевой кадр, например, при подключении к сессии нового участника. Для начала декодирования видео требуется ключевой кадр, декодер будет отклонять кадры до его получения.
Получатель запрашивает полный ключевой кадр сразу после подключения, это позволяет минимизировать задержку между подключением и появлением изображения на экране пользователя.
Пакеты PLI являются частью сообщений с ответной реакцией на определенную полезную нагрузку.
На практике ПО, которое умеет работать с пакетами PLI и FIR, используется в обоих случаях. Оно отправляет сигнал кодеру о предоставлении нового полного ключевого кадра.
Негативные подтверждения
NACK "просит" отправителя повторить отправку пакета RTP. Обычно, это связано с потерей пакета, но также может быть связано с его задержкой.
NACK является гораздо более эффективным с точки зрения пропускной способности решением, чем запрос всего фрейма. Поскольку RTP разбивает пакеты на части (chunks), запрашивается лишь маленький недостающий кусочек. Получатель создает сообщение с SSRC и последовательным номером. Если отправитель не может повторно отправить запрошенный пакет, он просто игнорирует это сообщение.
Отчеты отправителя и получателя
Эти отчеты используются для обмена статистикой между агентами. Статистика содержит информацию о количестве полученных пакетов и д�життере.
Отчеты могут использоваться для диагностики и контроля перегрузки.
Как RTP/RTCP решают проблемы вместе?
RTP и RTCP работают вместе над решением упомянутых выше проблем, связанных с динамичными условиями сетей. Эти техники все еще активно развиваются.
Forward Error Correction
Также известное как FEC (превентивное исправление ошибок) - другой способ решения проблемы потери пакетов. FEC - это когда мы отправляем данные несколько раз, без запроса на их повторную отправку. Это происходит на уровне RTP или даже на уровне кодека.
Если потеря пакетов является постоянной, FEC является более эффективным с точки зрения задержки, чем NACK. Время туда и обратно (round-trip time, rtt) запроса на повторную отправку недостающего пакета и отправк�у этого пакета может быть значительным в случае с NACK.
Адаптивная оценка битрейта и пропускной способности
Как говорилось в предыдущем разделе, сети являются непредсказуемыми и ненадежными. Пропускная способность может меняться несколько раз на протяжении одной сессии. Нередки случаи резкого изменения доступной пропускной способности (на порядки величины) в течение одной секунды.
Основная идея заключается в том, чтобы настраивать битрейт кодирования на основе прогнозируемой, текущей и будущей пропускной способности сети. Это позволяет обеспечить наилучшее качество передаваемого аудио или видео и избежать разрыва соединения по причине перегрузки. Эвристические техники, моделирующие поведение сети и пытающиеся его предсказать, известны как оценка пропускной способности (bandwidth estimation).
Здесь существует много нюансов, остановимся на некоторых из них подробнее.
Идентификация и передача состояния сети
RTP/RTCP используются в разных сетях, как следствие, иногда происходят обрывы соединения. Будучи построенными поверх UDP, эти протоколы не предоставляют встроенного механизма для повторной передачи пакетов, не говоря уже о контроле перегрузки.
Для обеспечение наилучшего пользовательского опыта WebRTC должен вычислять качество сетевого маршрута и адаптироваться к его изменениям. Ключевыми факторами мониторинга является следующее: доступная пропускная способность (в каждом направлении, может быть ассиметричной), время туда и обратно и джиттер (флуктуации, возникающие в пути туда и обратно). Это необходимо для расчета потери пакетов и обмена информацией об изменении этих свойств в процессе эволюции сетевых условий.
Рассматриваемые протоколы преследуют две главные цели:
- Вычисление доступной пропускной способности (в каждом направлении), поддерживаемой сетью.
- Обмен информацией о характеристиках сети между отправителем и получателем.
RTP/RTCP предоставляет три подхода к решению этих задач. Каждый подход имеет свои плюсы и минусы. Применяемый подход зависит от стека ПО, доступного клиентам, а также от библиотек, используемых в приложении.
Отчеты отправителя/получателя
Эти сообщения RTCP определяются в RFC 3550 и используются для обмена характеристиками сети между конечными точками. Отчеты получателя (receiver reports) посвящены качеству сети (включая потерю пакетов, время туда и обратно и джиттер) и используются в алгоритмах, предназначенных для расчета доступной пропускной способности.
Отчеты отправителя и получателя (sender reports/receiver reports, SR/RR) вместе формируют картину качества сети. Они отправляются для каждого SSRC и являются входными данными для вычисления пропускной способности. Эти вычисления производятся отправителем после получения данных RR, содержащих следующие поля:
Fraction Lost(доля потерянных пакетов) - какой процент пакетов был потерян после последнегоRR;Cumulative Number of Packets Lost(совокупное количество потерянных пакетов) - сколько пакетов было потеряно в течение сессии;Extended Highest Sequence Number Received(полученный расширенный максимальный последовательный номер) - какой последовательный номер был получен последним, и сколько раз он был получен;Interarrival Jitter(общий джиттер) - джиттер всего звонка;Last Sender Report Timestamp(время последнего отчета отправителя) - последнее известное время отправителя, используется для расчета времени туда и обратно.
SR и RR используются для вычисления времени туда и обратно.
Отправитель включает в SR свое локальное время sendertime1. При получении пакета SR получатель отправляет в ответ RR. Кроме прочего, RR включает в себя sendertime1, полученное от отправителя. Между получением SR и отправкой RR образуется задержка. По этой причине RR также включает "задержку после последнего отчета отправителя" (delay after last sender report, DLSR). DLSR используется для корректировки вычисления времени туда и обратно. После получения отправителем RR он вычитает sendertime1 и DLSR из текущего времени sendertime2. Эта разница во времени называется временем в пути туда и обратно (round-trip time, rtt).
rtt = sendertime2 - sendertime1 - DLSR
RTT простыми словами:
- я отправляю тебе сообщение, мои часы показывают 16 часов 20 минут 42 секунды и 420 миллисекунд;
- ты присылаешь мне такое же время в ответ;
- ты также присылаешь время, прошедшее между получением моего сообщения и отправкой твоего сообщения, скажем, 5 мс;
- после получения твоего сообщения, я снова смотрю на часы;
- теперь они показывают 16 ч 20 мин 42 сек 690 мс;
- это означает, что передача сообщения туда и обратно заняла 265 мс (690 - 420 - 5);
- таким образом, время туда и обратно составляет 265 мс.
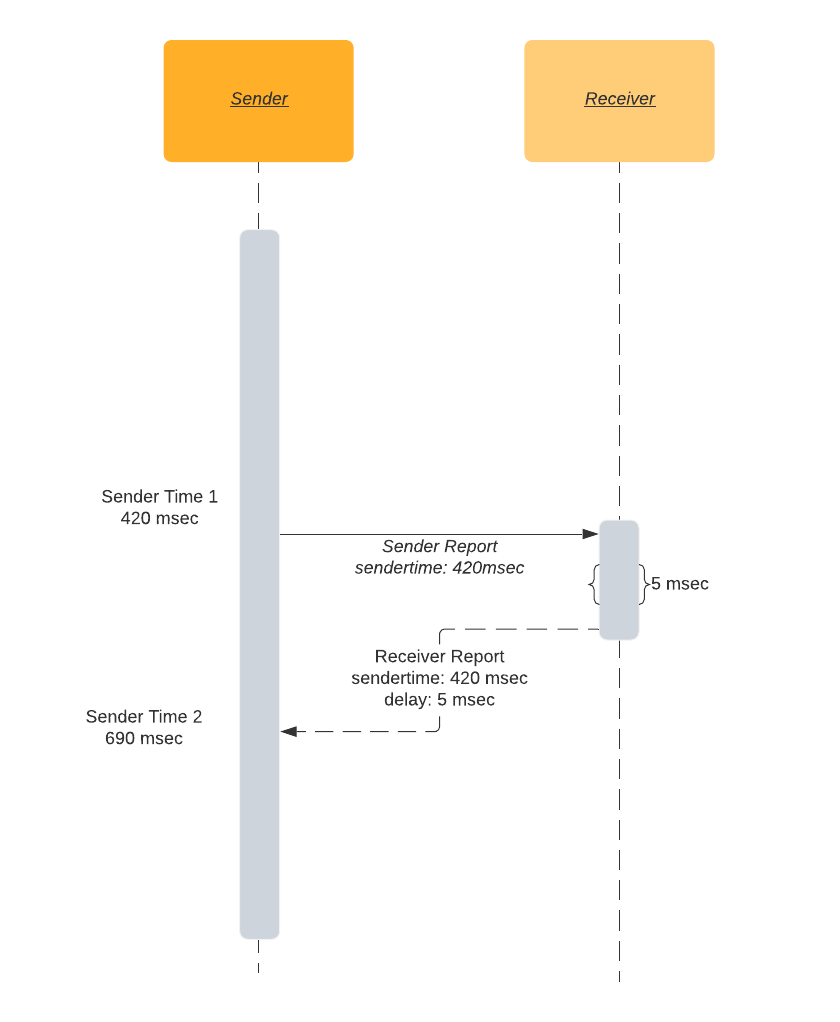
TMMBR, TMMBN, REMB и TWCC в сочетании с GCC
Google Congestion Control (GCC)
Алгоритм Google Congestion Control (GCC), описанный в общих чертах в draft-ietf-rmcat-gcc-02, пытается решить пробле�му расчета пропускной способности. Он сочетается с множеством других протоколов для снижения требований, необходимых для установки соединения. Он хорошо подходит как для принимающей стороны (при работе с TMMBR/TMMBN или REMB), так и для отправляющей стороны (при работе с TWCC).
GCC фокусируется на потерях пакетов и колебаниях времени прибытия кадров в качестве двух основных показателей для расчета пропускной способности. Он пропускает эти показатели через два связанных контроллера: для вычисления потерь (loss-based) и для вычисления задержки (delay-based).
Первый компонент GCC - контроллер для вычисления потерь, является очень простым:
- если потери пакета превышают
10%, оценка пропускной способности снижается; - если потери находятся в диапазоне
2-10%, оценка остается не�изменной; - если потери ниже
2%, оценка увеличивается.
Вычисления производятся не реже одного раза в секунду. В зависимости от парного протокола, о потере пакетов может либо сообщаться в явном виде (TWCC), либо потеря может предполагаться (TMMBR/TMMBN и REMB).
Вторая функция взаимодействует с контроллером для вычисления потерь и отслеживает изменения времени прибытия пакетов. Данный контроллер определяет, когда сетевые каналы становятся перегруженными, и снижает оценку пропускной способности. Идея состоит в том, что перегруженный интерфейс будет помещать пакеты в очередь до тех пор, пока не будет исчерпана емкость его буфера. Если такой интерфейс будет получать больше трафика, чем он может отправить, он будет вынужден отбрасывать (drop) пакеты, не помещающиеся в его буферном пространстве. Такой тип потери пакетов особенно опасен для сетей с малой задержкой или работающих в режиме реального времени, он также может негативно влиять на все типы коммуникаций в сети, поэтому его следует, по возможности, избегать. Таким образом, GCC пытается определить, растет ли глубина очереди сети перед началом действительной потери пакетов. Он уменьшает пропускную способность, если наблюдается увеличение задержек в очереди.
Для решения этой задачи GCC пытается определить увеличение глубины очереди (queue depth), измеряя незначительное увеличение времени приема-передачи. Он записывает "время между прибытиями" (inter-arrival time) кадров t(i) - t(i-1) - разницу во времени прибытия двух групп пакетов (как правило, последовательных видеокадров). Эти группы часто отправляются через равные промежутки времени (например, каждые 1/24 секунды для видео с частотой 24 кадра в секунду). В результате измерение времени между прибытиями становится таким же простым, как измерение разницы во времени между началом первой группы пакетов (т.е. кадра) и первым кадром следующей группы.
На представленной ниже диаграмме среднее увеличение задержки между пакетами составляет +20мс, что является явным показателем перегрузки сети.
Увеличение времени между прибытиями групп пакето�в является свидетельством увеличения глубины очереди в подключенных сетевых интерфейсах и, как следствие, перегрузки сети. Обратите внимание: GCC достаточно умен, чтобы учитывать колебания размеров байтов кадра. GCC уточняет проведенные измерения задержки с помощью фильтра Калмана и выполняет множество измерений времени приема-передачи (и его вариаций), прежде чем делать вывод о перегрузке сети. Фильтр Калмана в GCC можно считать заменой линейной регрессии: он позволяет делать точные прогнозы с учетом джиттера, добавляющего шум (noise) в измерения времени. При определении перегрузки GCC уменьшает доступный битрейт. В условиях стабильной сети он может медленно увеличивать оценку пропускной способности для проверки более высоких значений нагрузки.
TMMBR, TMMBN и REMB
Для TMMBR, TMMBN и REMB получатель сначала вычисляет доступную входящую пропускную способность (с помощью GCC, например), затем передает эту информацию отправителю. Сторонам не нужно обмениваться информацией о потере пакетов или других характеристиках сети, поскольку операции, выполняемые на стороне получателя, позволяют измерить время между прибытиями и потерю пакетов напрямую. Вместо этого TMMBR, TMMBN и REMB обмениваются оценками пропускной способности:
Temporary Maximum Media Stream Bit Rate Request(запрос временного максимального битрейта медиапотока) - мантисса/экспонента запрошенного битрейта для одногоSSRC;Temporary Maximum Media Stream Bit Rate Notification(уведомление о временном максимальном битрейте медиапотока) - уведомление о полученииTMMBR;Receiver Estimated Maximum Bitrate(расчетный максимальный битрейт получателя) - мантисса/экспонента запрошенного битрейта для всего сеанса.
TMMBR и TMMBN появились первыми и определе�ны в RFC 5104. REMB появился позже, был разработан черновик draft-alvestrand-rmcat-remb, который так и не был стандартизирован.
Иллюстрация сессии с использованием REMB:
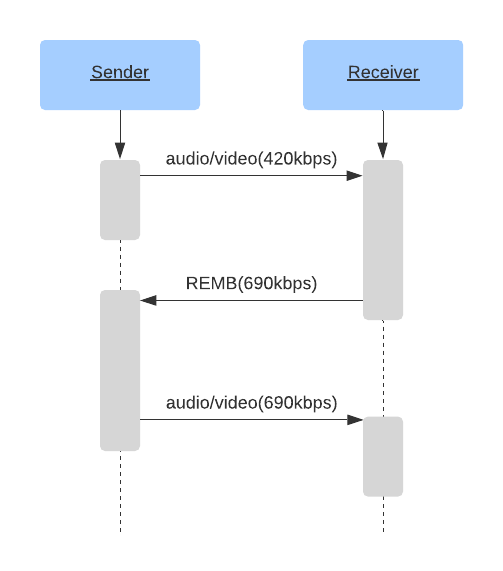
Данный метод хорошо работает на бумаге. Отправитель получает оценку от получателя, устанавливает битрейт кодировщика в полученное значение. Вуаля! Мы адаптировались к сетевым условиям.
Однако на практике REMB имеет некоторые недостатки.
Первым недостатком является неэффективность кодировщика. Когда мы устанавливаем для него битрейт, результат кодировки не обязательно будет соответствовать указанному значению. Мы можем получить больше или меньше битов в зависимости от настроек кодировщика и кодируемого кадра.
Например, результат работы кодировщика x264 с настройкой tune=zerolatency может существенно отличаться от установленного целевого битрейта. Один из возможных сценариев:
- предположим, что наш начальный битрейт составляет
1000 кбит/с; - кодировщик выдает только
700 кбит/с, поскольку ему не хватает высокочастотных признаков (high frequency features) для кодирования; - допустим, что получателю приходит видео
700 кбит/сс нулевой потерей пакетов. Затем он применяет правилоREMB 1для увеличения входящего битрейта на8%; - получатель отправляет пакет
REMBс предложением об увеличении битрейта до756 кбит/с(700 кбит/с * 1.08) отправителю; - отправитель устанавливает битрейт кодирования в значение
756 кбит/с; - кодировщик выдает еще более низкий битрейт;
- данный процесс повторяется снова и снова, что приводит к снижению битрейта до абсолютного минимума.
В конечном счете, это приведет к недоступному для просмотра видео даже при наличии прекрасного соединения.
Transport Wide Congestion Control
TWCC (контроль перегрузки на транспортном уровне) - одно из последних достижений в области оценки состояния сетевой коммуникации. Он определен в черновике draft-holmer-rmcat-transport-wide-cc-extensions-01.
В TWCC используется простой принцип:

В случае с REMB получатель сообщает отправителю о доступном битрейте загрузки. Он использует точные измерения предполагаемой потери пакетов и данные о времени между прибытиями пакетов.
TWCC - своего рода симбиоз протоколов SR/RR и REMB. Оценка пропускной способности возлагается на отправителя (как в SR/RR), но техника оценки больше похожа на REMB.
В TWCC получатель сообщает отправителю время прибытия каждого пакета. Эта информация является достаточной для того, чтобы отправитель мог измерить различные варианты задержек между прибытиями пакетов, а также идентифицировать потерянные и опоздавшие пакеты. При частом обмене такой информацией отправитель имеет возможность быстро адаптироваться к изменениям условий сети и корректировать пропускную способность с помощью таких алгоритмов, как GCC.
Отправитель следит за отправкой пакетов, их последовательными номерами, размером и временем отправки. При получении сообщения RTCP от получателя он сравнивает отправленную задержку между прибытиями пакетов с полученной. Увеличение получаемой задержки свидетельствует о перегрузке сети, в этом случае отправитель принимает необходимые меры по ее снижению.
Предоставляя отправителю необработанные данные, TWCC обеспечивает объективную оценку реальных условий сети:
- почти мгновенную информацию о потере пакетов, вплоть до индивидуальных пакетов;
- точный битрейт отправки;
- точный битрейт получения;
- измерение джиттера;
- разницу между задержками отправки и получения;
- описание того, как сеть справляется с волнообразной или стабильной пропускной способностью.
Одним из наиболее существенных преимуществ TWCC является гибкость, которую он предоставляет разработчикам WebRTC. Поскольку алгоритмы контроля перегрузки применяются на стороне отправителя, клиентский код может оставаться простым и легко масштабируемым. Сложные алгоритмы контроля перегрузки могут реализовываться быстрее на оборудовании, которым они непосредственно управляют (например, Selective Forwarding Unit - единица выборочной пересылки, обсуждаемая в следующем разделе). Для браузеров и мобильных устройств это означает, что клиенты могут извлекать выгоду из улучшений алгоритма, не дожидаясь стандартизации или обновления браузера (что может занимать продолжительное время).
Другие способы оценки пропускной способности
Наиболее разработанной реализацией является "A Google Congestion Control Algorithm for Real-Time Communication" (алгоритм контроля перегрузки для коммуникации в реальном времени), определенный в draft-alvestrand-rmcat-congestion.
Существует несколько альтернатив GCC, например, NADA: A Unified Congestion Control Scheme for Real-Time Media и SCReAM - Self-Clocked Rate Adaptation for Multimedia.
Обмен другими данными
WebRTC предоставляет каналы (data channels) для обмена данными (data communication). Между двумя пирами можно открыть до 65 534 каналов. Канал данных основан на датаграммах (datagram) и имеет определенную продолжительность (durability). По умолчанию канал данных гарантирует сохранения порядка сообщений.
На первый взгляд каналы данных могут казаться лишними. Зачем нам эта подсистема, когда мы можем использовать HTTP или веб-сокеты для обмена данными?
Одна из особенностей каналов данных состоит в том, что в результате настройки они могут стать неким подобием UDP с неупорядоченной/ненадежной доставкой сообщений. Это может потребоваться в ситуациях, когда критически важными являются низкая задержка и высокая производительность. Мы можем провести измерения и обеспечить отправку только такого количества сообщений, с которым гарантированно справится наша сеть.
Как это работает?
Для обмена данными WebRTC использует SCTP, определенный в RFC 4960. SCTP - это транспортный протокол, являющийся альтернативой TCP и UDP. В WebRTC он используется как протокол уровня приложения поверх соединения DTLS.
SCTP состоит из потоков, каждый из которых может настраиваться независимо от других. Каналы данных - это всего лишь абстракция потоков. Настройки, связанные с продолжительностью существования канала и порядком доставки сообщений, просто передаются агенту SCTP.
Каналы данных имеют некоторые возможности, отсутствующие в SCTP, например, метки каналов (channel labels). Для этого используется Протокол установки канала данных (Data Channel Establishment Protocol, DCEP), определенный в RFC 8832. DCEP определяет сообщения для взаимодействия с меткой канала и протоколом.
DCEP
DCEP содержит два сообщения: DATA_CHANNEL_OPEN и DATA_CHANNEL_ACK. Открытый канал должен получить ACK от удаленного пира.
DATA_CHANNEL_OPEN
Данное сообщение отправляется агентом, желающим открыть соединение.
Формат пакета
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Message Type | Channel Type | Priority |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Reliability Parameter |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Label Length | Protocol Length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
\ \
/ Label /
\ \
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
\ \
/ Protocol /
\ \
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Message Type
Message Type (тип сообщения) имеет фиксированное значение 0x03.
Channel Type
Channel Type (тип канала) определяет такие атрибуты канала, как продолжительность и порядок. Может иметь следующие значения:
DATA_CHANNEL_RELIABLE(0x00) - сообщения не были потеряны и будут прибывать в правильном порядке;DATA_CHANNEL_RELIABLE_UNORDERED(0x80) - сообщения не были потеряны, но могут прибывать в неправильном порядке;DATA_CHANNEL_PARTIAL_RELIABLE_REXMIT(0x01) - сообщения могут быть потеряны (после выполнения всех попыток), но будут прибывать в правильном порядке;DATA_CHANNEL_PARTIAL_RELIABLE_REXMIT_UNORDERED(0x81) - сообщения могут быть потеряны (после выполнения всех попыток) и могут прибывать в неправильном порядке;DATA_CHANNEL_PARTIAL_RELIABLE_TIMED(0x02) - сообщения могут быть потеряны (если они не прибывают в запрошенное время), но будут прибывать в правильном порядке;DATA_CHANNEL_PARTIAL_RELIABLE_TIMED_UNORDERED(0x82) - сообщения могут быть потеряны (если они не прибывают в запрошенное время) и могут прибывать в неправильном порядке.
Priority (приоритет)
Определяет приоритет канала. Каналы с более высоким приоритетом создаются раньше. Большие сообщения с низким приоритетом не задерживают отправку сообщений с высоким приоритетом.
Reliability Parameter (параметр надежности)
Если типом канала является DATA_CHANNEL_PARTIAL_RELIABLE, суффикс определяет следующее поведение:
REXMIT- определяет количество попыток отправки сообщения;TIMED- определяет, как долго отправитель будет пытаться отправить сообщение (в мс).
Label (метка, подпись)
Строка в формате UTF-8, содержащая название канала данных. Данная строка может быть пустой.
Protocol (протокол)
Если данная строка является пустой, протокол считается неопределенным. Если строка не является пустой, в ней должно содержаться значение из "Реестра имен подпротокола WebSocket" (WebSocket Subprotocol Name Registry), определенно�го в RFC 6455.
DATA_CHANNEL_ACK
Данное сообщение является подтверждением открытия канала данных, передаваемого от отправителя получателю.
Формат пакета
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Message Type |
+-+-+-+-+-+-+-+-+
SCTP
SCTP предоставляет следующие возможности:
- мультиплексирование;
- надежная доставка сообщений (для этого используется механизм передачи, подобный
TCP); - настройки частичной надежности (partial-reliability options);
- предотвращение перегрузки;
- контроль потока.
Мы разделим рассмотрение SCTP на три части.
Концепция
SCTP предоставляет большое количество возможностей. Мы рассмотрим только те возможности, которые используются в WebRTC. К возможностям, которые не используются WebRTC, относятся множественная адресация (multi-homing) и выбор пути.
SCTP разрабатывается более 20 лет, так что его непросто понять.
Ассоциация
Ассоциация (assosiation) - термин, относящийся к сессии SCTP. Это состояние, распределяемое между двумя взаимодействующими агентами.
Потоки
Поток (stream) - это двунаправленная последовательность пользовательских данных. Канал данных - это поток. Каждая ассоциация SCTP содержит список потоков. Каждый поток может обладать разным типом надежности.
WebRTC позволяет настраивать поток только в момент создания, но SCTP позволяет менять настройки в любое время.
Датаграммы
Кадры (фреймы, frames) SCTP - это набор датаграмм, а не байтовый поток. Отправка и получение данных похожа на использование UDP вместо TCP. Для передачи нескольких сообщений через один поток не нужен дополнительный код.
Сообщения SCTP не имеют ограничений по размеру, в отличие от сообщений UDP. Одно сообщение SCTP может иметь размер в несколько гигабайт.
Части
Протокол SCTP состоит из частей (chunks). Существуют различные типы частей. Эти части используются для всей коммуникации. Пользовательские данные, установка соединения, контроль перегрузки и т.д. - все это делается с помощью частей.
Каждый пакет SCTP состоит из списка частей. Поэтому в одном пакете UDP может содержаться несколько частей с сообщениями из разных потоков.
Последовательный номер передачи
Последовательный номер передачи (Transmission Sequence Number, TSN) - это глобальный уникальный идентификатор частей DATA. Часть DATA содержит все сообщения, которые желает отправить пользователь. TSN помогает получателю определять потерю или неправильный порядок пакетов.
Если получатель замечает отсутствующий TSN, он не передает данные пользователю до решения этой проблемы.
Идентификатор потока
Каждый поток имеет уникальный идентификатор. При создании канала данных с явным ID, этот ID просто передается SCTP в качестве идентификатора потока. Если такой ID отсутствует, он генерируется автоматически.
Идентификатор протокола полезной нагрузки
Каждая часть DATA также имеет идентификатор протокола полезной нагрузки (Payload Protocol Identifier, PPID). Он используется для идентификации типа передаваемых данных. SCTP имеет много PPID, но в WebRTC используются следующие пять:
WebRTC DCEP(50) - сообщенияDCEP;WebRTC String(51) - строковые сообщенияDataChannel;WebRTC Binary(53) - бинарные соо�бщенияDataChannel;WebRTC String Empty(56) - строковое сообщенияDataChannelс нулевой длиной (пустое строковое сообщение);WebRTC Binary Empty(57) - бинарное сообщенияDataChannelс нулевой длиной (пустое бинарное сообщение).
Протокол
Ниже представлены некоторые "чанки", которые используются в WebRTC.
Каждый чанк начинается с поля type. Перед списком чанков находится заголовок (header).
DATA
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type = 0 | Reserved|U|B|E| Length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| TSN |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Stream Identifier | Stream Sequence Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Payload Protocol Identifier |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
\ \
/ User Data /
\ \
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Чанк DATA используется для передачи пользовательских данных. Когда мы что-то отправляем через канал данных, используется этот чанк.
Бит U устанавливается, если данный пакет является неупорядоченным (unordered). Мы можем игнорировать последовательный номер потока.
B и E - это начальный и конечный биты. Если мы хотим отправить сообщение, которое является слишком большим для одного чанка DATA, оно будет разделено (fragmented) на несколько чанков DATA, передаваемых в нескольких пакетах. Для этого SCTP использует биты B и E, а также последовательные номера.
B=1,E=0- первая часть фрагментированного сообщения пользователя;B=0,E=0- средняя часть фрагментированного сообщения пользователя;B=0,E=1- последняя часть фрагментированного сообщения пользователя;B=1,E=1- целое (нефрагментированное) сообщение.
TSN - последовательный номер передачи, уникальный идентификатор данного чанка DATA. После 4 294 967 295 чанка TSN обнуляется. TSN увеличивается на единицу для каждого чанка во фрагментированном сообщении пользователя, что позволяет получателю определять порядок чанков для восстановления исходного сообщения.
Stream Identifier - уникальный идентификатор потока, которому принадлежат данные.
Stream Sequence Number - это 16-битный номер, увеличивающийся при каждом сообщении и включаемый в заголовок сообщения чанка DATA. После 65 535 сообщения SSN обнуляется. Это число используется для определения порядка доставки сообщений получателю, когда U имеет значение 0. SSN похож на TSN, но он увеличивается для каждого сообщения, а не для каждого чанка.
Payload Protocol Identifier - тип данных, передаваемых через поток. В случае с WebRTC он будет DCEP, строкой или двоичными данными.
User Data - это то, что мы отправляем. Все данные, передаваемые через WebRTC, передаются через чанк DATA.
INIT
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type = 1 | Chunk Flags | Chunk Length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Initiate Tag |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Advertised Receiver Window Credit (a_rwnd) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Number of Outbound Streams | Number of Inbound Streams |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Initial TSN |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
\ \
/ Optional/Variable-Length Parameters /
\ \
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Чанк INIT запускает процесс создания ассоциации.
Initiate Tag используется для генерации куки (cookie). Куки используются для предотвращения атак "Человек посередине" и "Отказ в обслуживании".
Advertised Receiver Window Credit используется для контроля перегрузки SCTP. Это поле определяет размер буфера, выделенного получателем для данной ассоциации.
Number of Outbound/Inbound Streams уведомляет удаленный пир о количестве потоков, поддерживаемых данным агентом.
Initial TSN - произвольное число (uint32), с которого начинается локальный TSN.
Поле Optional Parameters предназначено для добавления в протокол новых возможностей.
SACK
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type = 3 |Chunk Flags | Chunk Length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Cumulative TSN Ack |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Advertised Receiver Window Credit (a_rwnd) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Number of Gap Ack Blocks = N | Number of Duplicate TSNs = X |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Gap Ack Block #1 Start | Gap Ack Block #1 End |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
/ /
\ ... \
/ /
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Gap Ack Block #N Start | Gap Ack Block #N End |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Duplicate TSN 1 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
/ /
\ ... \
/ /
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Duplicate TSN X |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Чанк SACK - это подтверждение получения пакета получателем. До получения отправителем SACK для TSN он будет повторно отправлять чанк DATA по запросу. Но SACK не только обновляет TSN.
Cumulative TSN ACK - максимальный полученный TSN.
Advertised Receiver Window Credit - размер буфера получателя. Это значение может меняться в течение сессии, если у получателя появится больше свободной памяти.
Ack Blocks - это TSN, полученные после Cumulative TSN ACK. Это значение используется при наличии бреши в доставленных пакетах. Допустим, были доставлены чанки DATA с TSN, имеющими значения 100, 102, 103 и 104. Cumulative TSN ACK будет иметь значение 100, но Ack Blocks может использоваться для уведомления отправителя об отсутствии необходимости в повторной отправке чанков 102, 103 и 104.
Duplicate TSN информирует отправит�еля, что он получил указанные чанки DATA более одного раза.
HEARTBEAT
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type = 4 | Chunk Flags | Heartbeat Length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
\ \
/ Heartbeat Information TLV (Variable-Length) /
\ \
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Чанк HEARTBEAT используется для проверки активности удаленного пира. Может использоваться для обеспечения открытости NAT без отправки чанков DATA.
ABORT
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type = 6 |Reserved |T| Length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
/ /
\ Zero or more Error Causes \
/ /
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Чанк ABORT резко закрывает ассоциацию. Используется, когда одна из сторон переходит в состояние ошибки (error state). Для плавного закрытия соединения используется чанк SHUTDOWN.
SHUTDOWN
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type = 7 | Chunk Flags | Length = 8 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Cumulative TSN Ack |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Чанк SHUTDOWN запускает процесс плавного закрытия ассоциации SCTP. Каждый агент информирует другую сторону о последнем полученном TSN. Это позволяет убедиться в том, что никакие пакеты не были потеряны. WebRTC не закрывает ассоциацию автоматически. Поэтому каждый канал данных должен быть закрыт вручную.
Cumulative TSN ACK - последний отправленный TSN. Каждая сторона закрывает соединение только после получения чанка DATA с этим TSN.
ERROR
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type = 9 | Chunk Flags | Length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
\ \
/ Одна или более причина ошибки /
\ \
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Чанк ERROR используется для уведомления другой стороны о возникновении не критичной для ассоциации ошибки.
TSN FORWARD
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type = 192 | Flags = 0x00 | Length = Variable |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| New Cumulative TSN |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Stream-1 | Stream Sequence-1 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
\ /
/ \
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Stream-N | Stream Sequence-N |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Чанк TSN FORWARD сдвигает глобальный TSN вперед. Это позволяет пропустить пакеты, которые нам больше не нужны. Предположим, что мы отправили пакеты 10 11 12 13 14 15, которые являются валидными только в случае доставки всех пакетов и только в случае своевременной доставки.
Если мы потеряли пакеты 12 и 13, в отправке пакетов 14 и 15 нет смысла. SCTP использует чанк TSN FORWARD для решения этой задачи. Он сообщает получателю, что пакеты 14 и 15 не будут доставлены.
New Cumulative TSN - новый TSN подключения. Любые пакеты, доставленные перед ним, будут отброшены.
Stream и Stream Sequence используются для сдвига вперед Stream Sequence Number.
Конвейер SCTP
Есть несколько интересных вещей, касающихся машины состояния (state machine) SCTP. WebRTC не использует все возможности этой машины - такие возможности мы рассматривать не будем. Мы также упростим некоторые компоненты для их лучшего понимания.
Установка соединения
Чанки INIT и INIT ACK используются для обмена возможностями и настройками каждого пира. SCTP использует куки в процессе рукопожатия для валидации пира, с которым предполагается коммуникация. Это предотвращает перехват рукопожатия и DoS-атаки.
Чанк INIT ACK содержит куки. Куки возвращаются создателю с помощью COOKIE ECHO. Если верификация куки прошла успешно, отправляется COOKIE ACK и можно обмениваться чанками DATA.

Завершение сессии
Для этого используется чанк SHUTDOWN. Когда агент получает чанк SHUTDOWN, он ждет получения запрошенного Cumulative TSN ACK. Это позволяет убедиться в доставке всех данных, даже если соединение является ненадежным.
Механизм поддержания активности
Для поддержания соединения в активном состоянии используются чанки HEARTBEAT REQUEST и HEARTBEAT ACK. Они отправляются с определенной периодичностью. SCTP также выполняет экспоненциальную выдержку (exponential backoff), когда пакеты не доставляются.
Чанк HEARTBEAT также содержит время, что позволяет двум ассоциациям рассчитать время передачи данных между двумя агентами.
Применение
Данный раздел посвящен тому, что можно создать с помощью WebRTC, а также тому, как это делается. Все возможности WebRTC имеют свою цену и ценность. Разработка реальных приложений WebRTC - задача не из простых.
Случаи использования
Многие считают, что WebRTC - это про конференции в браузере. Однако, это намного больше. WebRTC используется в широком спектре приложений. Все время появляется что-то новое.
Конференц-связь
Конференц-связь (conferencing) - стандартный случай использования WebRTC. Протокол содержит несколько возможностей, которых не содержит ни один другой протокол. Систему конференц-связи можно построить с помощью WebSocket и она будет работать. Но в условиях ре�альных сетей WebRTC - лучший выбор.
WebRTC предоставляет контроль перегрузки и автоматически адаптируемый битрейт для медиа. При изменении сетевых условий пользователи всегда будут иметь наилучший опыт использования приложения. Разработчикам не нужно писать дополнительный код для измерения этих условий.
Участники конференции могут отправлять и получать несколько потоков одновременно. Они также могут добавлять и удалять потоки в любое время в течение сессии. Используемые кодеки также предварительно согласовываются. Весь этот функционал предоставляется браузером.
Такая конференция также выигрывает от наличия каналов данных. Пользователи могут обмениваться дополнительными данными (metadata) или документами. Мы можем создать несколько потоков и сделать некоторые из них более производительными в ущерб надежной доставке сообщений.
Вещание
Все больше новых проектов, в которых используется WebRTC, связаны с вещанием (broadcasting) в той или иной степени. Протокол предоставляет большое количество возможностей как для издателя (publisher), так и для потребителя (consumer) медиа.
WebRTC существенно облегчает процесс публикации видео. Пользователям не нужно устанавливать специальное ПО. Любая платформа с браузером может публиковать видео. Издатели могут отправлять несколько треков и модифицировать или удалять их в любое время. Это является существенным преимуществом перед старыми протоколами, которые позволяли передавать только один аудио или видеотрек через одно соединение.
WebRTC предоставляет разработчикам серьезный контроль над задержкой и качеством. Важно, что задержка никогда не превышает максимальный порог (threshold), и мы можем игнорировать некоторые артефакты декодирования. Мы можем запускать воспроизведение видео сразу после его доставки. С другими протоколами, функционирующими поверх TCP, это сделать не так просто. В браузере мы просто запрашиваем данные и сразу их получаем.
Удаленный доступ
Уда�ленный доступ (remote access) - это когда мы получаем доступ к другому компьютеру через WebRTC. Мы можем контролировать удаленный хост целиком или только отдельное приложение, работающее на нем. Это отлично подходит для выполнения сложных вычислительных задач, когда собственной мощности оказывается недостаточно. WebRTC – это революция сразу в трех направлениях.
WebRTC может использоваться для доступа к удаленному хосту, скрытому от остального мира. С помощью обхода NAT мы можем получить доступ к компьютеру, доступному только через STUN. Это обеспечивает безопасность и конфиденциальность. Пользователям не нужно передавать видео через посредника или "переходник" (ретранслятор). Отображение NAT также облегчает деплой приложения. Нам не надо беспокоиться о перенаправлении портов или настройке статического IP.
Каналы данных также активно применяются в этом сценарии использования. Они могут быть настроены таким образом, что будут принимать только последние данные. В случае с TCP мы рискуем столкнуться с блокировкой начала строки (Head-of-line blocking). Клик мыши или нажатие клавиши могут задержаться в пути и блокировать получение следующих за ними событий. Каналы данных спроектированы специально для обработки таких случаев и позволяют отключить повторную отправку потерянных пакетов. Мы также можем измерять нагрузку и проверять, что отправляем ровно столько данных, сколько способна выдержать наша сеть.
Наличие WebRTC в браузере сильно упрощает жизнь. Нам не нужно скачивать проприетарного (платного) клиента для начала сессии. Все большее количество клиентов имеют встроенную поддержку WebRTC, например, умные телевизоры (Smart TV).
Передача файлов и обход цензуры
Передача файлов (File Sharing) и обход цензуры (Censorship Circumvention) - это две совершенно разные проблемы. Однако, WebRTC успешно решает обе. Он делает коммуникацию легкодоступной и практически не поддающейся блокировке.
Первая задача, которую решает WebRTC - это получение клиента. Если мы хотим присоединиться к файлообменной сети, нам нужно загрузить клиента. Даже если сеть является распределенной, все равно нужен клиент. В ограниченной сети загрузка клиента может быть заблокированной. Даже если получится скачать клиента, сможет ли пользователь самостоятельно установить и запустить его? WebRTC доступен в каждом браузере: это готовый к использованию клиент.
Вторая проблема - блокировка трафика. Если мы используем протокол, предназначенный только для передачи файлов или обхода цензуры, его легко заблокировать. Поскольку WebRTC - это протокол общего назначения, его блокировка затронет каждого. Блокировка WebRTC может помешать подключению новых участников к конференции.
Интернет вещей
Интернет вещей (Internet of Things, IoT) включает в себя несколько вещей. Для многих это означает камеры видеонаблюдения. С помощью WebRTC мы можем передавать видео другому пиру, такому как телефон или браузер. Другим случаем является подключение устройств и обмен чувствительными данными (sensor data). У нас может быть два устройства, функционирующих в локальной сети, которые обмениваются данными о климате, шуме или освещенности.
WebRTC имеет существенные преимущества перед старыми протоколами для обмена потоками. Поскольку WebRTC поддерживает P2P-соединения, мы можем передавать видео с камеры напрямую в браузер. Нет необходимости использовать сторонний сервер. Даже если видео будет зашифрованным, злоумышленник может извлечь некоторую информацию из метаданных звонка.
Совместимость - еще одно преимущество, предоставляемое WebRTC. WebRTC доступен во многих языках программирования: C#, C++, C, Go, Java, Python, Rust, JavaScript и TypeScript. Это означает, что мы можем использовать язык, который хотим. Нам не требуются проприетарные протоколы или форматы для подключения клиентов.
Обмен медиаданными
Предположим, что у нас есть "железо" и ПО, генерирующее видео, но мы пока не можем их обновить. Для просмотра видео пользователь должен загрузить проприетарного клиента. Это является фрустрирующим. Ответ - запуск моста (bridge) WebRTC. Мост транслируется между двумя протоколами, поэтому пользователи могут использовать браузер со старыми настройками.
Во многих форматах, используемые разработчиками, применяются те же протоколы, что и в WebRTC. Протокол установления сеанса (Session Initiation Protocol, SIP), как правило, транслируется через WebRTC и позволяет пользователям совершать телефонные звонки с помощью браузера. Потоковый протокол реального времени (Real Time Streaming Protocol, RTSP) используется в старых камерах видеонаблюдения. Они оба используют одинаковые протоколы (RTP и SDP). Мост требует добавления или удаления только тех вещей, которые специфичны для WebRTC.
Обмен другими данными
Для передачи данных браузер может использовать ограниченный набор протоколов: HTTP, WebSockets, WebRTC и QUIC. Если мы хотим к чему-то подключиться, то должны использовать протокольный мост (protocol bridge). Протокольный мост - это сервер, который преобразует входящий трафик в нечто, доступное для браузера. Хорошим примером является SSH, который используется для доступа к серверу. Каналы данных WebRTC в этом отношении предоставляют несколько преимуществ.
Каналы данных допускают ненадежную и неупорядоченную доставку. Это необходимо в случаях, когда критически важной является низкая задержка доставки пакетов. Мы не хотим, чтобы новые данные блокировались старыми (блокировка начала строки). Представьте, что играете в многопользовательский "шутер" от первого лица. Вам важно, где пользователь был две секунды назад? Если данные не прибывают вовремя, какой смысл продолжать попытки их отправки. Ненадежная и неупорядоченная доставка позволяет использовать данные сразу по их прибытии.
Каналы данных также предоставляют обратную связь о нагрузке (feedback pressure). Это позволяет своевременно определять, что мы отправляем больше данных, чем поддерживает наша сеть. В этом случае у нас есть два варианта: канал данных может помещать сообщения в буфер и доставлять их с задержкой или же мы можем игнорировать "опоздавшие" сообщения.
Телеоперация
Телеоперация (teleoperation) - это управление удаленным устройством через каналы данных WebRTC и обратная отправка видео через RTP. Сегодня WebRTC позволяет разработчикам удаленно управлять автомобилями! Это используется для управления роботами при создании сайтов и доставки посылок.
WebRTC повсюду. Все, что нужно пользователю, это браузер и устройство. Браузеры поддерживают джойстики и геймпады. WebRTC избавляет от необходимости устанавливать дополнительных клиентов на устройство пол�ьзователя.
Распределенные CDN
Распределенные CDN (Content Delivery Network - сеть доставки контента) - это разновидность файлообменной сети. Распределяемые файлы настраиваются оператором CDN. Когда пользователь подключается к CDN, он может скачивать и делиться разрешенными (allowed) файлами.
CDN хорошо работают при наличии хорошего соединения по локальной сети и отсутствии необходимости в хорошем внешнем соединении. У нас может быть один пользователь, скачавший видео, и поделившийся им с остальными. Поскольку пользователи не пытаются скачать один и тот же файл из внешней сети, передача происходит быстро.
Топологии WebRTC
WebRTC - это протокол, предназначенный для прямого соединения двух агентов, но как разработчику подключить тысячу людей? Существует несколько способов, каждый из которых имеет свои п�реимущества и недостатки. Эти решения условно можно разделить на две категории: равный-к-равному (Peer-to-Peer) или клиент/сервер (Client/Server). Гибкость WebRTC позволяет легко реализовать любой из этих сценариев.
Один-к-одному
Один-к-одному (One-to-One) - первый тип подключения, используемый в WebRTC. Мы соединяем двух агентов напрямую и они могут обмениваться медиа и другими данными. В этом случае подключение выглядит так:

Полная сетка
Полная сетка (Full Mesh) - это решение для разработки конференции или многопользовательской игры. В данном случае каждый пользователь устанавливает соединение с другими пользователями напрямую. Это позволяет создать приложение, но имеет некоторые недостатки.
В полной сетке каждый пользователь подключается напрямую. Это означает, что нам нужно шифровать и загружать видео независимо для каждого участника сессии. Условия сети между каждым соединением будут разными, поэтому мы не может повторно использовать одно и то же видео. Обработка ошибок - в данном случае также задача не из простых. Необходимо правильно определять степень потери соединения: является ли оно полным или касается только одного удаленного пира.
По этим и другим причинам полная сетка хорошо подходит для небольших групп. Для большого количества участников сессии лучше подходит топология клиент/сервер.
Гибридная сетка
Гибридная сетка (Hybrid Mesh) - это альтернатива полной сетки, которая может решить некоторые проблемы с ней. В гибридной сетке вместо установки соединения между каждым пользователем медиа ретранслируется через пиры в сети. Это означает, что создателю медиа не требуется большая пропускная способность для передачи данных.
Этот подход также имеет некоторые недостатки. Создатель медиа не знает о том, кому передаются данные и успешно ли они доставляются. Каждый переход также увеличивает время доставки пакетов.
Единица выборочной пересылки
Единица выборочной пересылки (Selective Forwarding Unit, SFU) также устраняет недостатки полной сетки, но несколько другим способом. SFU реализует топологию клиент/сервер вместо P2P. Каждый пир подключается к SFU и загружает в него свое медиа. Затем SFU пересылает медиа каждому подключенному клиенту.
В SFU каждый агент должен зашифровать и загрузить видео только один раз. Ответственность за передачу видео всем участникам ложится на SFU. Установка SFU-соединения, к тому же, проще, чем установка P2P-соединения. SFU может быть запущен на открытом маршрутизируемом адресе, что облегчает подключение к нему клиентов. Поэтому в данном случае не требуется отоб�ражение NAT. Однако нам все еще необходимо обеспечивать доступность SFU через TCP (через ICE-TCP или TURN).
Разработка простого SFU может быть завершена в течение недели. Разработка хорошего SFU, обрабатывающего все типы клиентов - бесконечный процесс, в который входит постоянное совершенствование контроля перегрузки, обработки ошибок и повышение производительности.
Многоточечная конференц-система
Многоточечная конференц-система (Multi-point Conferencing Unit, MCU) - это топология клиент/сервер, похожая на SFU, но объединяющая выходные потоки. Вместо того, чтобы передавать медиаданные в неизменном виде, они декодируются в один поток.

Отладка
Отладка WebRTC - сложная задача, поскольку в нем имеется большое количество подвижных частей, которые могут ломаться независимо друг от друга. Если не проявлять осторожности, можно потратить недели на решение несуществующих проблем. При обнаружении сломавшейся части, необходимо потратить еще немного времени на то, чтобы понять, почему произошла поломка.
Локализация проблемы
При отладке приложения WebRTC сначала необходимо определить источник проблемы.
Потеря сигнала
Потеря сети
Проверяем сервер STUN с помощью netcat:
- Формируем 20-байтный пакет запроса на привязку (binding request packet):
echo -ne "\x00\x01\x00\x00\x21\x12\xA4\x42TESTTESTTEST" | hexdump -C
00000000 00 01 00 00 21 12 a4 42 54 45 53 54 54 45 53 54 |....!..BTESTTEST|
00000010 54 45 53 54 |TEST|
00000014
Здесь:
00 01- тип сообщения;00 00- размер данных (длина соответствующего раздела);21 12 a4 42- магическое куки;54 45 53 54 54 45 53 54 54 45 53 54(декодированное вASCII:TESTTESTTEST) - 12-байтовый идентификатор транзакции.
- Отправляем запрос и ждем получения 32-байтного ответа:
stunserver=stun1.l.google.com;stunport=19302;listenport=20000;echo -ne "\x00\x01\x00\x00\x21\x12\xA4\x42TESTTESTTEST" | nc -u -p $listenport $stunserver $stunport -w 1 | hexdump -C
00000000 01 01 00 0c 21 12 a4 42 54 45 53 54 54 45 53 54 |....!..BTESTTEST|
00000010 54 45 53 54 00 20 00 08 00 01 6f 32 7f 36 de 89 |TEST. ....o2.6..|
00000020
Здесь:
01 01- тип сообщения;00 0c- размер данных, которые декодируются до12в десятичном формате;21 12 a4 42- магическое куки;54 45 53 54 54 45 53 54 54 45 53 54(декодированное вASCII:TESTTESTTEST) - 12-байтовый идентификатор транзакции;00 20 00 08 00 01 6f 32 7f 36 de 89- 12-байтовые данные:00 20- это тип:XOR-MAPPED-ADDRESS;00 08- размер значения, декодируемого до8в десятичном формате;00 01 6f 32 7f 36 de 89- значение данных:00 01- тип адреса (IPv4);6f 32- XOR-сопоставленный (XOR-mapped) порт;7f 36 de 89- XOR-сопоставленный IP-адрес.
Декодирование XOR-сопоставленного раздела является сложным, но мы можем обмануть сервер STUN для выполнения фиктивного отображения XOR с помощью фиктивного магического куки со значением 00 00 00 00:
stunserver=stun1.l.google.com;stunport=19302;listenport=20000;echo -ne "\x00\x01\x00\x00\x00\x00\x00\x00TESTTESTTEST" | nc -u -p $listenport $stunserver $stunport -w 1 | hexdump -C
00000000 01 01 00 0c 00 00 00 00 54 45 53 54 54 45 53 54 |........TESTTEST|
00000010 54 45 53 54 00 01 00 08 00 01 4e 20 5e 24 7a cb |TEST......N ^$z.|
00000020
XOR-операция против фиктивного магического куки будет идемпотентной, поэтому порт и адрес в ответе будут достоверными. Это будет работать не во всех случаях, поскольку некоторые маршрутизаторы манипулируют проходящими через них пакетами, обманывая (cheating) IP-адрес. Последние 8 байтов ответа будут выглядеть следующим образом:
00 01 4e 20 5e 24 7a cb- значение данных:00 01- тип адреса (IPv4);4e 20- сопоставленный порт, которые декодируется до20000в десятичном формате;5e 24 7a cb-IP-адрес, который декодируется в94.36.122.203.
Ошибка безопасности
Ошибка медиа
Ошибка данных
Инструменты для отладки
netcat (nc)
netcat - сетевая утилита командной строки для чтения из/записи в сетевые соединения с помощью TCP или UDP. Данная утилита, обычно, доступна через команду nc.
tcpdump
tcpdump - это интерфейс командной строки для анализа сетевых пакетов с данными.
Наиболее распространенные команды:
- перехватываем пакеты
UDPв/из порта19302, отображаем шестнадцатеричный дамп (hexdump) содержимого пакета
sudo tcpdump 'udp port 19302' -xx
- то же самое, но сохраняем пакеты в файле
PCAP(�захват пакета - packet capture) для дальнейшего изучения
sudo tcpdump 'udp port 19302' -w stun.pcap
Файл PCAP можно открыть с помощью команды wireshark stun.pcap.
Wireshark
Wireshark - это широко используемый анализатор сетевых протоколов.
webrtc-internals
Chrome предоставляет встроенную страницу статистики WebRTC: chrome://webrtc-internals.
Задержка
Как понять, что имеет место высокая задер�жка доставки сообщений? Мы можем заметить, что наше видео лагает (lagging), но как определить точную величину задержки? Для уменьшения задержки, необходимо сначала ее измерить.
Предполагается, что истинная задержка должна измеряться от начала до конца (end-to-end). Это означает учет не только задержки сетевого пути между отправителем и получателем, но общую задержку захвата камеры, шифрования кадров, передачи, получения, расшифровки и отображения, а также возможную буферизацию (постановку задач в очередь - queueing) на любом из этапов.
Задержка от начала до конца - это не просто сумма задержек каждого компонента.
Несмотря на то, что теоретически мы можем измерить задержку каждого компонента потоковой передачи видео по отдельности и суммировать результаты, на практике некоторые компоненты будут либо недоступными для измерения, либо результаты измерения этих компонентов вне конвейера (pipeline) будут сильно отличаться от результатов их измерения в связке с другими компонентами. Разная глубина о�череди на разных этапах, топология сети и изменения экспозиции камеры - вот лишь несколько примеров влияния компонентов на конечную задержку.
Задержка каждого компонента в системе потоковой передачи данных может меняться и влиять на нижележащие компоненты. Даже содержимое захваченного видео влияет на задержку. Например, требуется намного больше битов для высокочастотных (high frequency) изображений вроде ветвей дерева по сравнению с низкочастотными кадрами вроде чистого голубого неба. Камера с автоматической экспозицией может захватывать кадр гораздо дольше ожидаемых 33 мс, даже при установке частоты захвата (capture rate) в значение 30 кадров в секунду (frames per second). Передача по сети, особенно по сотовой, также очень динамична из-за постоянно меняющегося спроса (на ресурсы сети). Чем больше пользователей, тем больше "шума" в эфире. Наша физическая локация (например, в зоне с плохим сигналом) и множество других факторов увеличивают потерю пакетов и задержку. Что происходит при отправке пакета по сети, например, через адаптер WiFi или LTE-модем? Если пакет не может быть доставлен незам�едлительно, он помещается в очередь, чем больше очередь, тем выше задержка.
Ручное измерение конечной задержки
Когда мы говорим о конечной задержке, мы имеем в виду время между возникновением события и его наблюдением, например, отображением видеокадра на экране.
EndToEndLatency = T(observe) - T(happen)
Наивный подход заключается в фиксировании времени возникновения события и его вычитание из времени наблюдения события. Однако при точности в мс критически важной становится задача синхронизации времени. Попытки синхронизации времени в распределенных системах являются практически бесполезными, поскольку даже небольшая ошибка приводит к недостоверному измерению задержки.
Простейшим решением проблемы синхронизации часов является использование одних часов. Для этого отправитель и получатель должны находиться в одной системе отсчета.
Представим, что у нас есть таймер, отсчитывающий миллисекунды. Мы хотим измерить задержку в системе, в которой наш таймер транслируется в реальном времени на удаленный экран. Наивный способ измерения времени между возникновением события и появлением на экране видео кадра состоит в следующем:
- фиксируем время на часах;
- отправляем видео получателю, находящемуся в той же физической локации;
- фиксируем время появления видео на экране получателя;
- вычитаем одно время из другого.
Это самый простой способ измерения конечной задержки. Он учитывает все компоненты, влияющие на задержк�у (камера, кодировщик, сеть, декодер) и не полагается на синхронизацию часов.
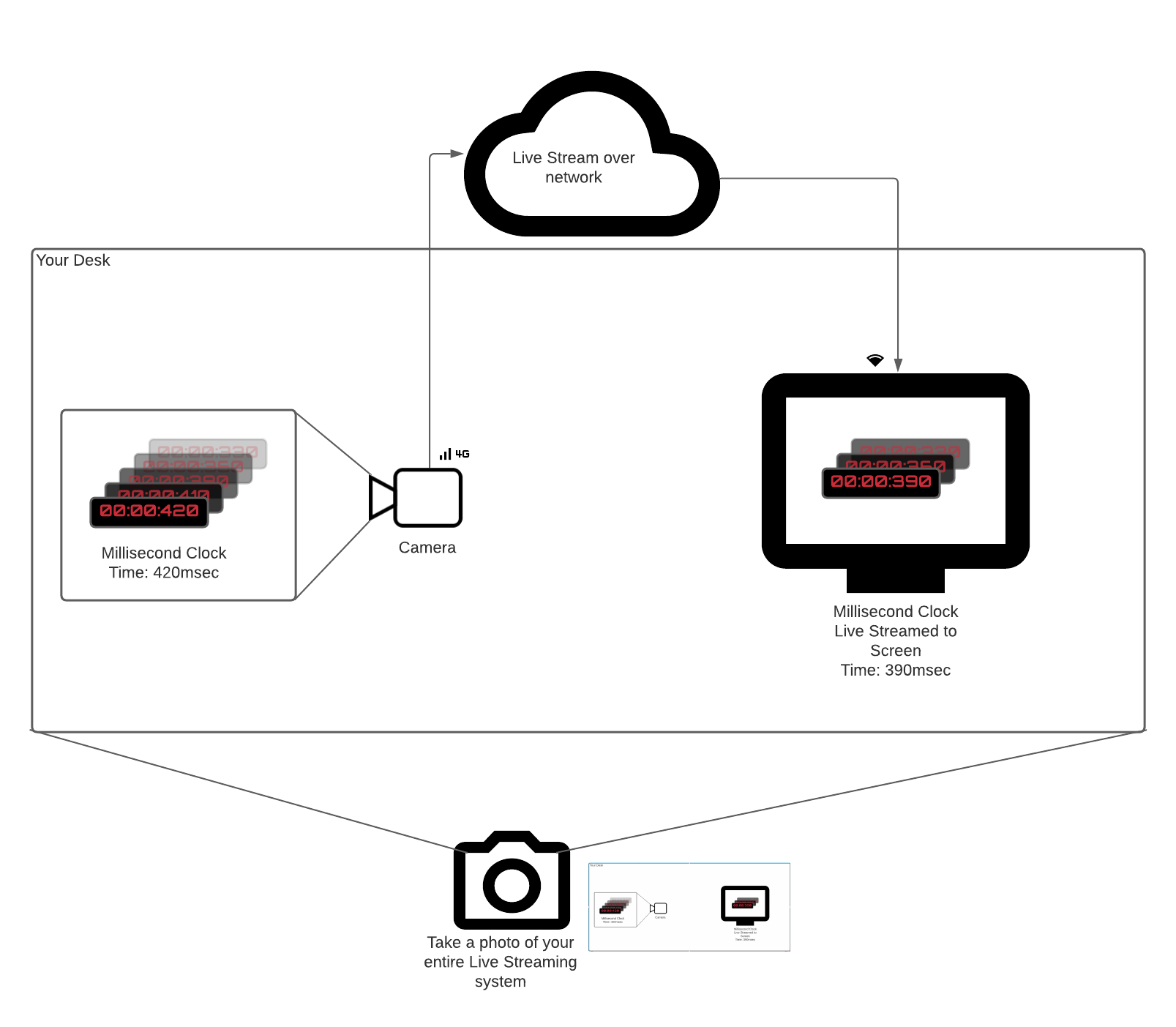
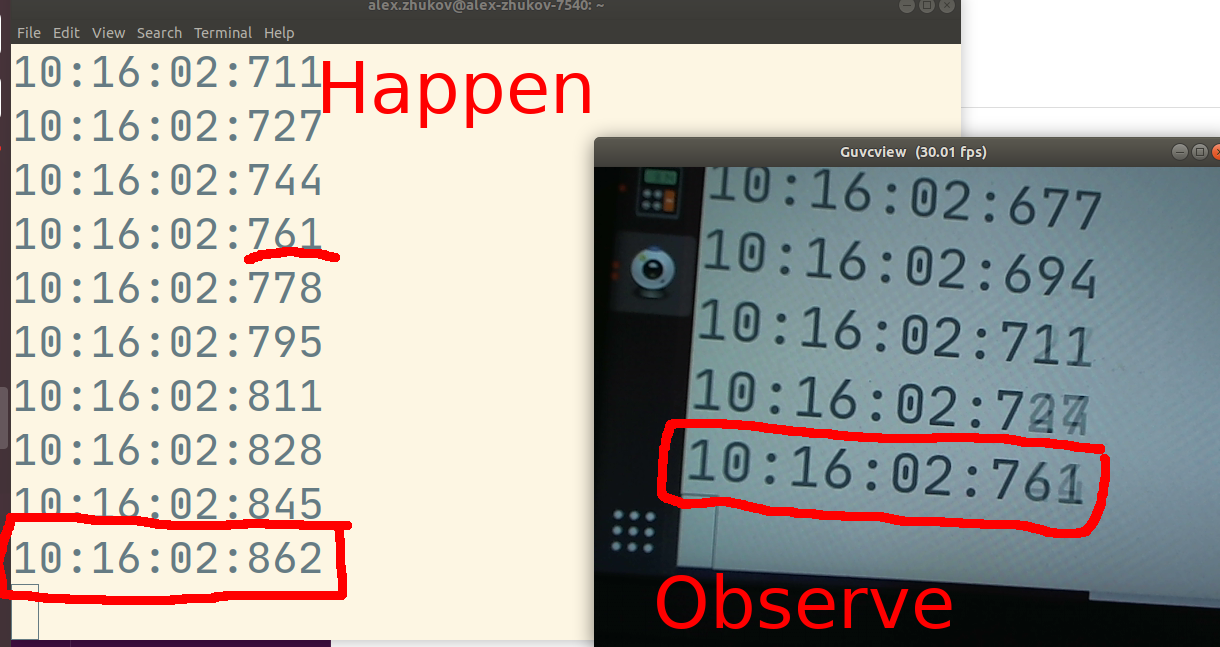
На приведенном выше фото конечная задержка составляет 101 мс. Время возникновения события составляет 10:16:02.761, а время его наблюдения - 10:16:02.862.
Автоматическое измерение задержки
В настоящее время (май 2021 года) стандарт WebRTC, посвященный конечной задержке, находится в стадии активного обсуждения. Firefox реализовал набор API поверх стандартных API WebRTC для автоматического измерения задержки. Однако далее мы рассмотрим более общий способ.
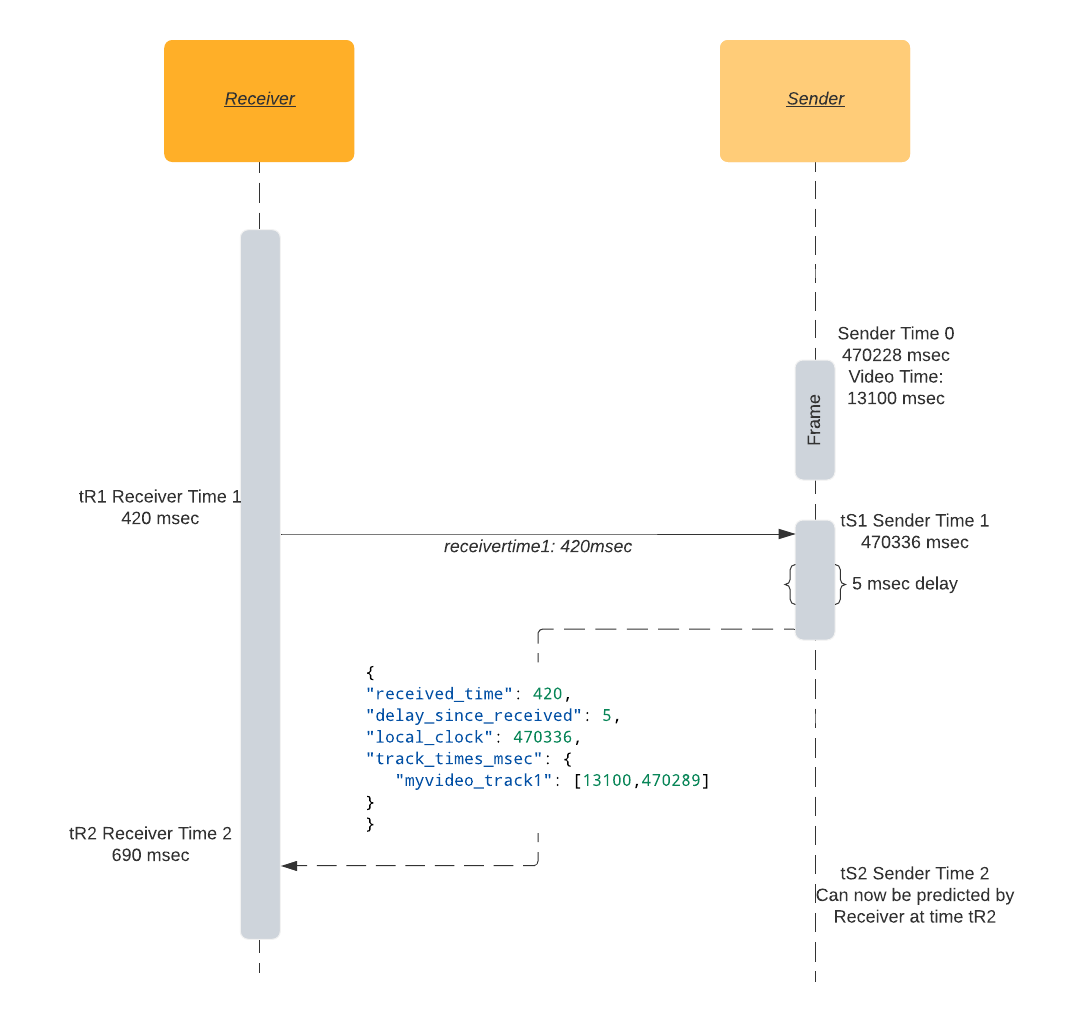
Суть времени пути (round-trip time, rtt): я отправляю тебе мое время tR1, при получении от тебя tR1 обратно я фикси�рую время tR2, таким образом, время пути составляет tR1 - tR2.
При наличии канала коммуникации между отправителем и получателем (например, DataChannel), получатель может смоделировать монотонные часы (monotonic clock) отправителя следующим образом:
- Получатель отправляет сообщение со своим временем
tR1. - При получении сообщения от получателя, отправитель фиксирует свое время
tS1и отправляет копиюtR1иtS1, а также время видеотрека отправителяtSV1. - При получении сообщений от отправителя, получатель фиксирует свое время
tR2и вычисляет время пути:RTT = tR2 - tR1. - Времени пути
RTTи времени отправителяtS1достаточно для вычисления монотонных часов отправителя. Текущее время отправителя дляtR2будет равнятьсяtS1+ половина времени пути. - Времени отправителя
tS1вместе с временем видеотрекаtSV1достаточно для синхронизации времени видеотрека получателя со временем видеотрека отправителя.
Поскольку нам известно время tSV1, мы можем приблизительно вычислить задержку посредством вычитания текущего времени отображения видеокадра (actual_video_time) из ожидаемого времени:
expected_video_time = tSV1 + time_since(tSV1)
latency = expected_video_time - actual_video_time
Недостатком этого метода является то, что не учитывается задержка камеры. В большинстве видеосистем время захвата кадра считается временем доставки кадра из камеры в память, что происходит через некоторое время после возникновения события записи.
Пример вычисления задержки
В следующем примере мы открываем канал данных latency на стороне получателя и пери�одически отправляем время монотонного таймера отправителю. Отправитель отвечает сообщением в формате JSON, и получатель вычисляет задержку на основании этого сообщения.
{
"received_time": 64714, // Время, отправленное получателем, которое фиксируется отправителем
"delay_since_received": 46, // Время, прошедшее с последнего `received_time`, полученного отправителем
"local_clock": 1597366470336, // Текущее монотонное время отправителя
"track_times_msec": {
"myvideo_track1": [
13100, // Временная метка видеокадра RTP (в мс)
1597366470289 // Временная метк�а монотонных часов видеокадра
]
}
}
Открываем канал данных на стороне получателя:
dataChannel = peerConnection.createDataChannel('latency')
Периодически отправляем время получателя tR1. В данном случае интервал составляет 2 секунды:
setInterval(() => {
const tR1 = Math.trunc(performance.now())
dataChannel.send(String(tR1))
}, 2000)
Обрабатываем сообщение получателя на стороне отправителя:
// предположим, что `event.data` - это строка типа '1234567'
const tR1 = event.data
const now = Math.trunc(performance.now())
const tSV1 = 42000 // Временная метка текущего фрейма RTP, преобразованная в мс
const tS1 = 1597366470289 // Временная метка монотонных часов текущего фрейма
const msg = {
"received_time": tR1,
"delay_since_received": 0,
"local_clock": now,
"track_times_msec": {
"myvideo_track1": [tSV1, tS1]
}
}
dataChannel.send(JSON.stringify(msg))
Обрабатываем сообщение отправителя на стороне получателя, вычисляем задержку и выводим ее в консоль:
const tR2 = Math.trunc(performance.now())
const fromSender = JSON.parse(event.data)
const tR1 = fromSender['']
const delay = fromSender[''] // Сколько прошло времени между получением сообщения отправителем и отправкой ответа
const senderTimeFromResponse = fromSender['']
const rtt = tR2 - delay - tR1
const networkLatency = rtt / 2
const senderTime = (senderTimeFromResponse + delay + networkLatency)
const video$ = document.querySelector('video')
video$.requestVideoFrameCallback((now, framemeta) => {
// Вычисляем текущее время отправителя
const delaySinceVideoCallbackRequested = now - tR2
senderTime += delaySinceVideoCallbackRequested
const [tSV1, tS1] = Object.entries(fromSender[''])[0][1]
const timeSinceLastKnownFrame = senderTime - tS1
const expectedVideoTimeMsec = tSV1 + timeSinceLastKnownFrame
const actualVideoTimeMsec = Math.trunc(framemeta.rtpTimestamp / 90) // Преобразуем время RTP (90000) в мс
const latency = expectedVideoTimeMsec - actualVideoTimeMsec
console.log('latency', latency, 'ms')
})
Реальное время видео в браузере
HTMLVideoElement.requestVideoFrameCallback() позволяет разработчикам получать уведомления о представлении фрейма для композиции.
До недавнего времени (май 2020 года) было практически невозможно получить достоверное время отображения видеокадра в браузере. Данная проблема решалась через HTMLVideoElement.currentTime, но не давала необходимой точности. В настоящее время стандарт W3C HTMLVideoElement.requestVideoFrameCallback(), позволяющий получать текущее время видеокадра, поддерживается Chrome и Firefox. Несмотря на то, что это дополнение кажется тривиальным, оно сделало возможным использование некоторых продвинутых возможностей в приложениях, требующих синхронизации аудио и видео. Функция обратного вызова включает поле rtpTimestamp - временную метку RTP, связанную с текущим видеокадром.
Отладка задержки
Поскольку отладка в данном случае означает измерение задержки, общее правило таково: упрощаем настройку до минимума при условии сохранения (воспроизводимости) проблемы. Чем больше компонентов мы удалим, тем проще будет определить, какой компонент вызывает задержку.
Задержка камеры
В зависимости от настроек камеры производимая ей задержка может быть разной. Проверяем настройки автоэкспозиции, автофокуса и автоматического баланса белого. Вс�ем автоматическим настройкам требуется дополнительное время для анализа захваченного изображения перед его передачей в стек WebRTC.
Если у вас Linux, для управления настройками камеры можно воспользоваться командой v4l2-ctl:
## Отключаем автофокус
v4l2-ctl -d /dev/video0 -c focus_auto=0
## Устанавливаем фокус в значение бесконечности
v4l2-ctl -d /dev/video0 -c focus_absolute=0
Также можно воспользоваться графическим интерфе�йсом guvcview для быстрой проверки и установки настроек камеры.
Задержка шифрования
Большинство современных кодировщиков буферизуют некоторые кадры перед их шифрованием. Их главный приоритет - баланс между качеством производимого изображения и битрейтом. Многопроходное кодирование (multipass encoding) - экстремальный пример пренебрежения кодировщиком конечной задержкой. На первом проходе кодировщик "проглатывает" видео целиком перед началом производства кадров.
Однако при правильной настройке можно добиться уменьшения подкадровой (sub-frame) задержки. Убедитесь, что ваш кодировщик не использует чрезмерное количество эталонных кадров (reference frames) и не полагается на B-кадры (B-frames). Настройки для разных кодеков будет разными, но для x264 рекомендуется использовать tune=zerolatency и profile=baseline для снижения задержки.
Сетевая задержка
Сетевая задержка - это то, с чем почти ничего нельзя сделать, кроме обновления сети. Сетевая задержка - это как погода: мы не можем остановить дождь, но можем посмотреть прогноз и взять с собой зонт. WebRTC измеряет сетевые условия с точностью до мс. И при этом самые важные метрики:
- время пути;
- потеря и ретрансляция пакетов.
Время пути
Стек WebRTC имеет встроенный механизм для измерения сетевого времени пути (RTT). Достаточно хорошее приблизительное вычисление задержки - это половина RTT. Механизм исходит из предположения, что отправка и получение пакетов занимает одинаковое время, что не всегда соответствует действительности. RTT устанавливает нижнюю границу конечной задержки. Наши видеокадры не могут достичь получателя быстрее, чем за RTT / 2, независимо от того, насколько оптимизирована наша камера и конвейер кодировщика.
Встроенный механизм RTT основан на специальных пакетах RTCP, которые называются отчетами отправителя/получателя (sender/receiver reports). Отправитель передает свое время получателю, получатель отвечает тем же временем. Это позволяет отправителю определить количество времени, которое занимает путь пакета туда и обратно.
Потеря и ретрансляция пакетов
Прот�околы RTP и RTCP основаны на UDP, что означает отсутствие гарантии сохранения порядка, надежной доставки пакетов или отсутствия дубликатов. Все это может происходить и действительно происходит в реальных WebRTC-приложениях. Простые реализации декодеров ожидают получения всех кадров изображения для его успешного восстановления. В случае потери пакетов P-кадра (P-frame) могут появиться различные артефакты декодирования. Если потеряны пакеты I-кадра (I-frame), все зависимые кадры получат тяжелые артефакты или совсем не будут декодированы. Это может привести к "зависанию" видео на какое-то время.
Для преодоления зависания видео или появления артефактов декодирования WebRTC использует сообщения с негативными благодарностями (Negative Acknowledgement, NACK). Когда получатель не получает ожидаемый пакет RTP, он возвращает отправителю сообщение NACK для повторной отправки недостающего пакета. Получатель ждет повторной отправки пакета. Такое ожидание увеличивает задержку. Количество отправленных и полученных пакетов NACK записывается в статические поля nackCount исходящего потока и nackCount входящего потока.
Графы входящих и исходящих nackCount можно увидеть на странице webrtc-internals. Если мы видим, что nackCount увеличивается, значит, имеет место высокая потеря пакетов, и стек WebRTC делает все возможное для плавного воспроизведения видео или аудио.
При высокой потере пакетов, когда декодер не может произвести изображение или последующие зависимые изображения, например, при полной потере I-кадра, последующие P-кадры не декодируются. Получатель пытается смягчить это путем отправки специального сообщения-индикатора потери изображения (Picture Loss Indicator, PLI). Когда отправитель получает PLI, он повторно отправляет новый I-кадр. I-кадры, как правило, больше P-кадров по размеру. Это увеличивает количество пакетов для передачи. Как и в случае с NACK, получатель ждет получения нового I-кадра, что приводит к увеличению задержки.
Смотрите на значение поля pliCount на странице webrtc-internals. Если значение данного поля у�величивается, установите меньшее количество производимых декодером кадров или включите более лояльный к ошибкам режим.
Задержка на стороне получателя
Задержка также увеличивается при прибытии пакетов в неправильном порядке. Если нижняя часть изображения прибывает раньше верхней, декодирование изображения будет заниматься чуть больше времени, чем когда части изображения прибывают в правильном порядке. Мы говорили об этом в разделе, посвященном джиттеру.
Встроенная метрика jitterBufferDelay показывает, как долго кадр находился в буфере получателя, ожидая прибытия недостающих пакетов, перед его передачей декодеру для расшифровки.